
RocketMQ 消息发送 system busy / broker busy 根因分析
本文是消息中间件故障排除系列的第一篇 叙事框架:
现象 → 排查过程 → 根因 → 修复 → 预防
问题现象
某日早高峰,支付团队上线了「支付状态同步 v2.0」,将原来异步回调改为了同步推送 trade-status-sync 消息。这个改动本身没有问题——用消息中间件解耦支付和下游系统是正确的架构决策。但上线后不到 10 分钟,监控告警触发——支付状态同步失败率飙升到 34.7%。
值班 SRE 查看应用日志,发现了大量 RocketMQ 发送失败的报错:
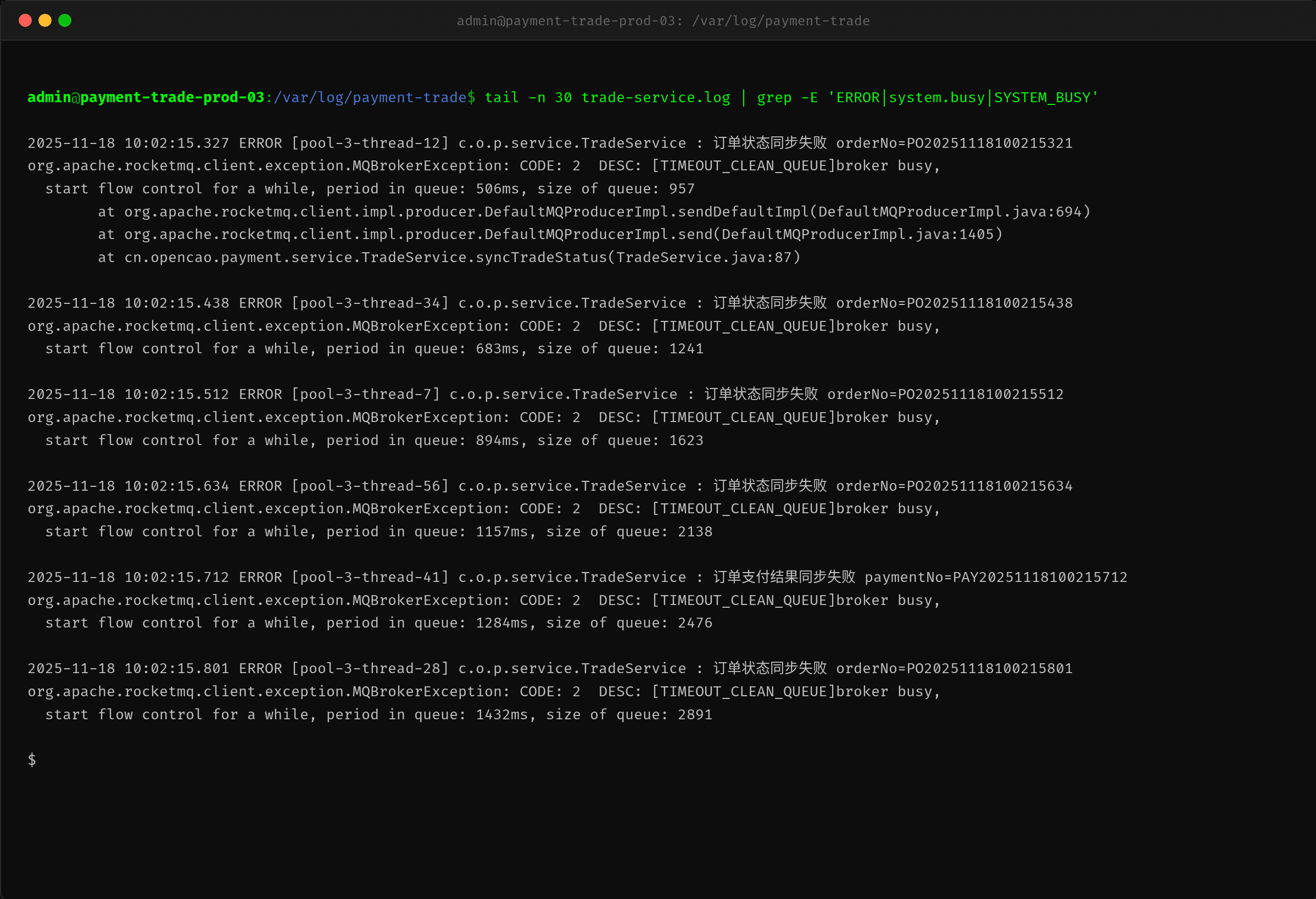
错误特征非常一致——都是 CODE: 2 DESC: [TIMEOUT_CLEAN_QUEUE]broker busy,排队时间从 500ms 到 1.4s 不等,队列积压从 957 一路涨到 2891。
错误码 2 在 RocketMQ 的语义中代表 SYSTEM_BUSY,TIMEOUT_CLEAN_QUEUE 前缀说明是队列中等待时间超时被 BrokerFastFailure 机制清理掉的。这不同于网络超时或连接拒绝——Broker 进程本身还在运行,TCP 连接也正常,但处理能力跟不上了。
业务影响:部分支付订单状态未能同步,导致下游系统(物流、积分、推送)处理延迟。支付模块的错误率陡增导致上游网关也触发了 5xx 告警,形成了一个小型连锁反应。
告警群第一时间就收到了通知:
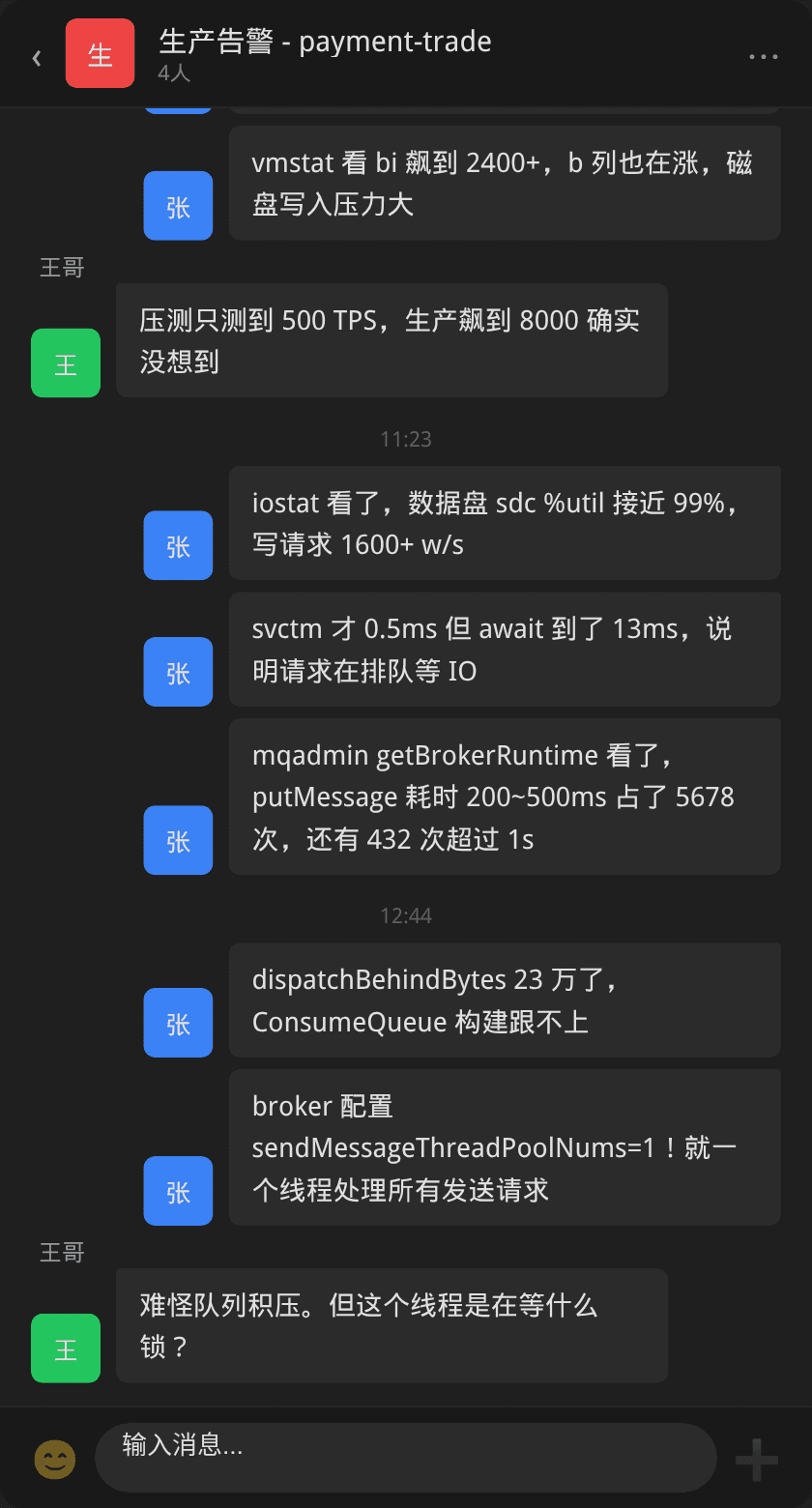
排查过程
第一步:Broker 端日志确认
上到 RocketMQ Broker 机器,先看 broker 日志:
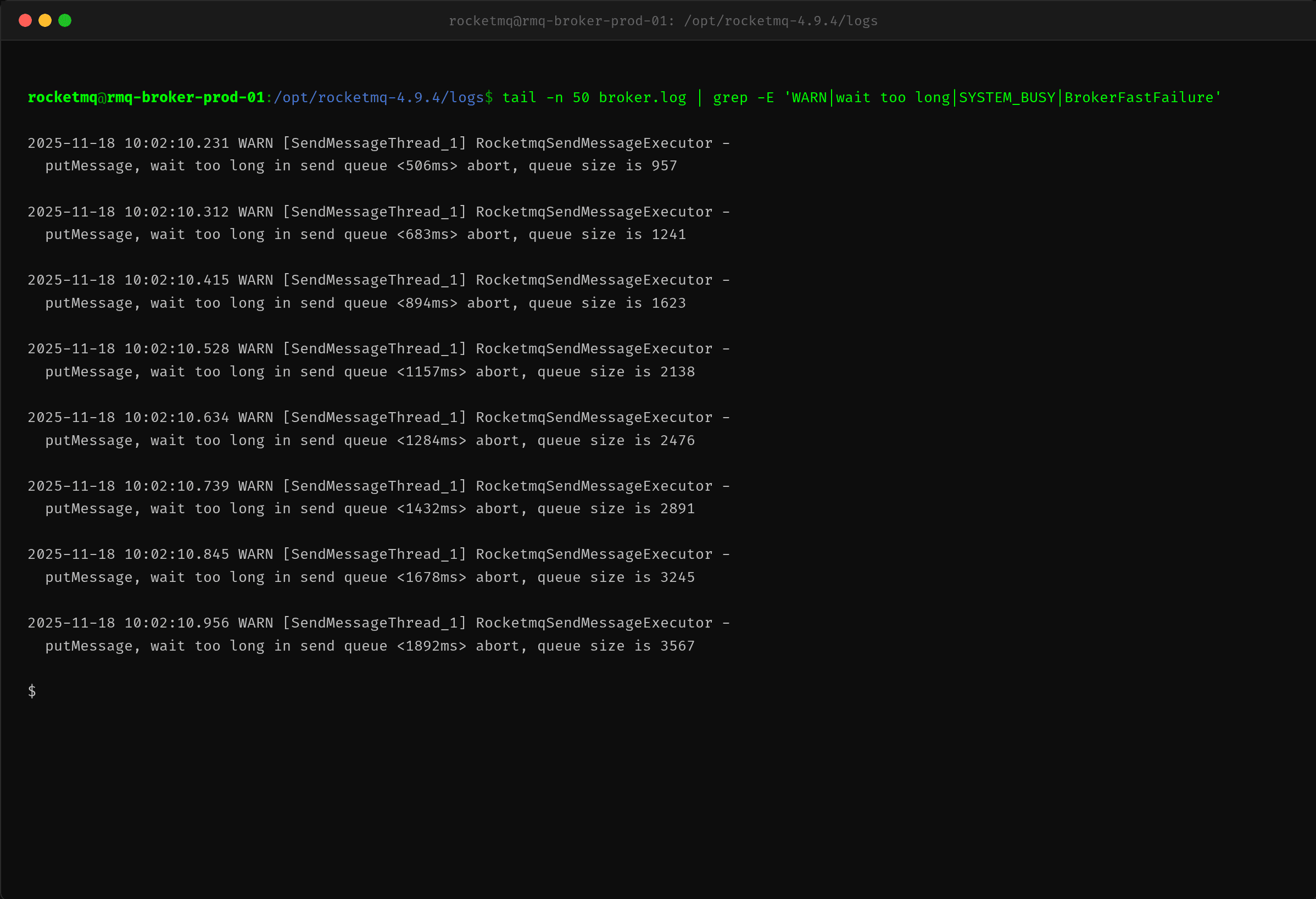
日志清晰地记录了 SendMessageThread_1 反复输出 wait too long in send queue <xxx> abort。每个请求在队列里排队等待的时间持续增长,从 506ms 涨到 1892ms,队列积压从 957 涨到 3567。
这说明 Broker 端的发送线程池已经严重过载——请求进来后无法被及时处理,在队列里排队超时后被 BrokerFastFailure 机制主动拒绝。
第二步:系统资源排查
首先用 top 看系统整体状态:
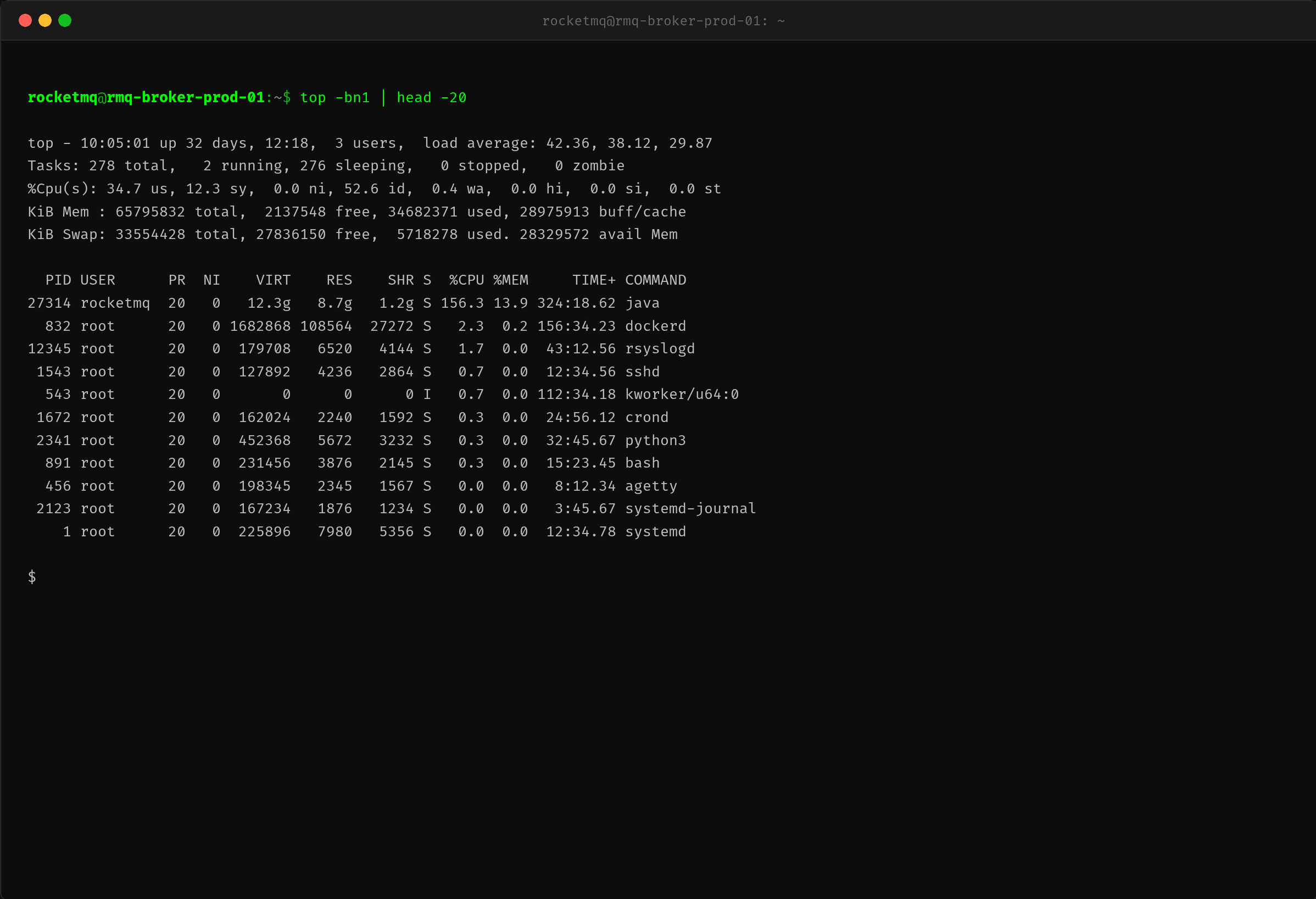
CPU 才 35% 使用率,52% 空闲——说明系统瓶颈不在 CPU。但 load average 高达 42,而且是持续攀升趋势。这里有一个关键判断:CPU 空闲 + load 高 = 进程在等 IO(不可中断睡眠态)。
再看 RocketMQ Java 进程信息:CPU 156%(多线程累加)、RES 8.7G、S 状态列是 S(sleeping)。进程占用了 8.7G 内存,其中大部分是 PageCache——这正是 RocketMQ 利用 mmap 写入 CommitLog 的内存映射区域。
用 vmstat 进一步确认 IO 状况:
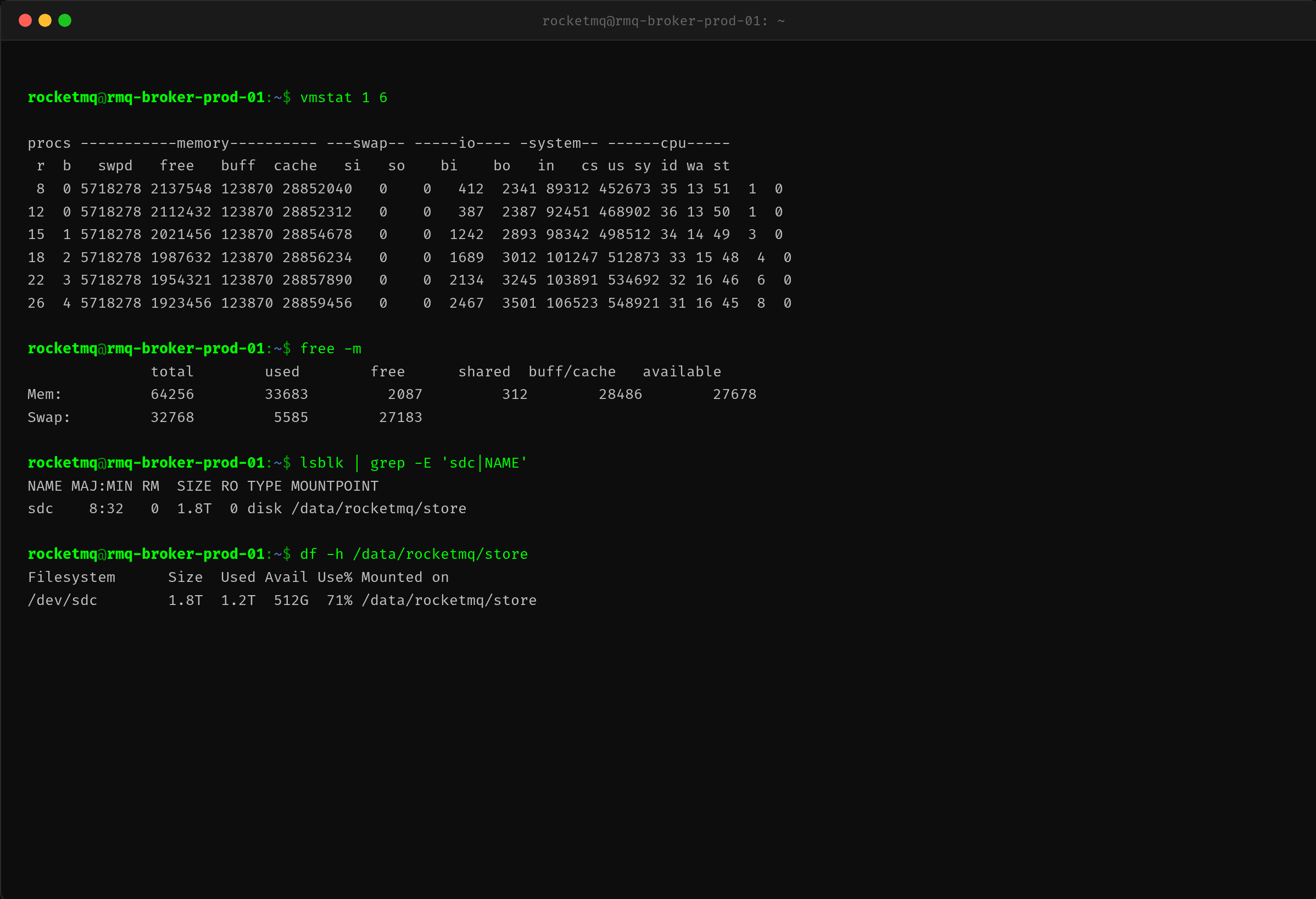
重点关注三列:
- b(不可中断睡眠进程数):从 0 爬到 4,说明确实有线程在等 IO 完成
- bi(块设备读入):从 412 KB/s 涨到 2467 KB/s——磁盘读取在持续增加
- wa(IO wait CPU):从 1% 涨到 8%,CPU 等待 IO 的比例在上升
同时注意到 free(空闲内存)在持续下降(从 2137MB → 1923MB),而 cache 在增长(28852 → 28859MB)。这符合 PageCache 增长的预期——RocketMQ 写入 CommitLog 时通过 mmap 映射文件,大量写入会导致 PageCache 占用上涨,进而挤压空闲内存。
第三步:磁盘 IO 定位瓶颈
用 iostat -x 定位磁盘级别的问题:
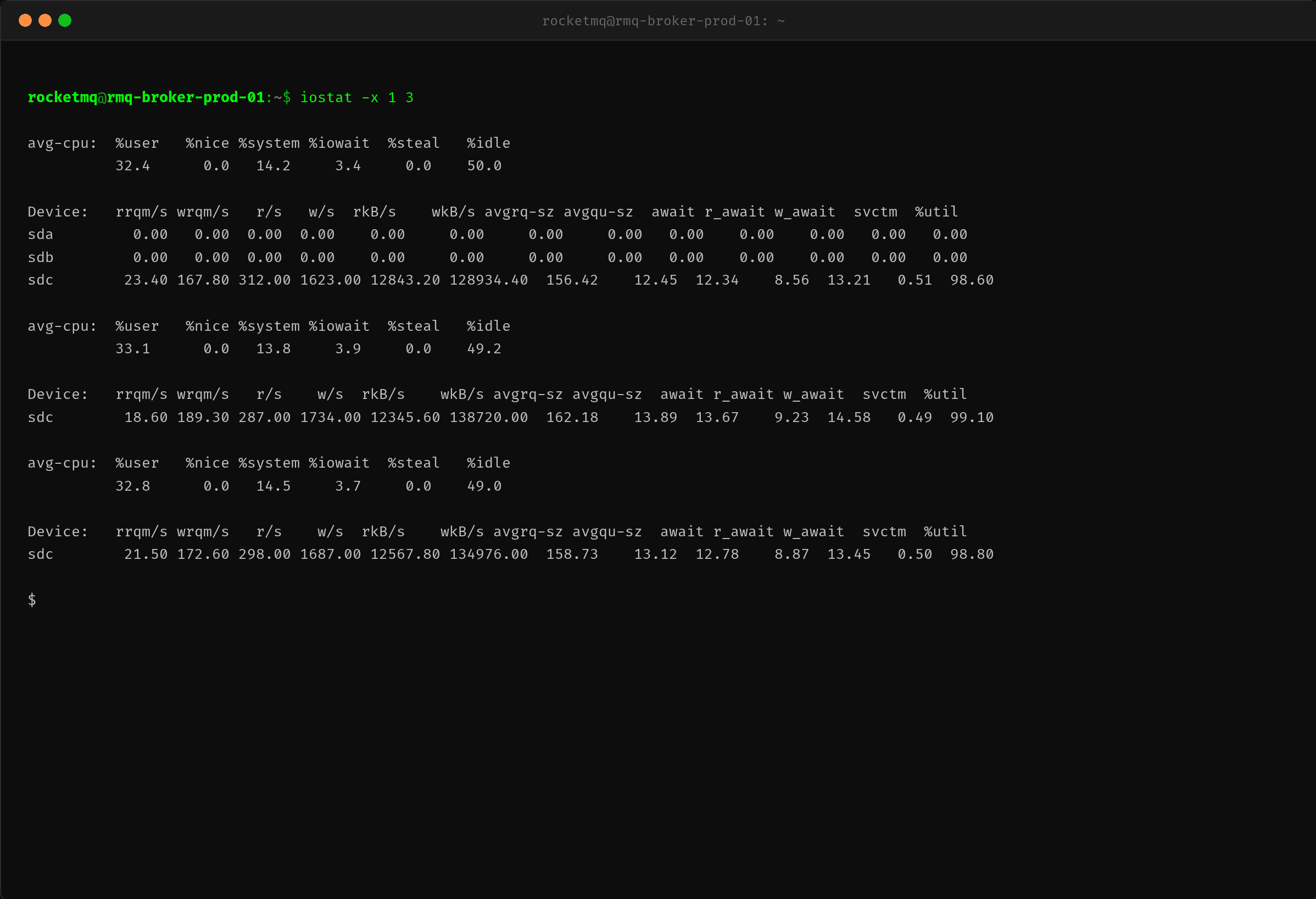
数据盘 sdc 的 %util 达到 98.6%~99.1%,基本满负荷运转。这里逐一解读关键指标:
- r/s = 312, w/s = 1623:每秒 312 次读 + 1623 次写,主要是 RocketMQ 的异步刷盘和 ReputMessageService 构建 ConsumeQueue 读操作
- rkB/s ≈ 12.8MB, wkB/s ≈ 128.9MB:写入带宽约 129MB/s,对于机械盘或入门级 SSD 都不是小数字
- avgqu-sz = 12.45:磁盘请求队列深度超过 12,说明有大量 IO 请求在排队等待处理
- await = 12.34ms:IO 请求从提交到完成平均等待 12ms,正常 SSD 应该在 1~2ms,机械盘在 5~8ms
- w_await = 13.21ms:写请求的响应时间更长,写操作在等待刷盘
- svctm = 0.51ms:IO 请求的实际服务时间很短(0.5ms),说明磁盘本身硬件没有问题,问题是请求太多排起了长队
svctm 和 await 的差距(0.51ms vs 12.34ms)是判断 IO 瓶颈的关键信号——硬件处理速度是够的,但请求数量远超硬件处理能力,导致大量排队。
sdc 正是 RocketMQ 的存储盘(CommitLog、ConsumeQueue 都在这块盘上)。高 IO 负载导致每次 putMessage 写入 CommitLog 的时间变长。
第四步:Broker 运行时指标
使用 mqadmin getBrokerRuntime 查看 Broker 内部运行状况:
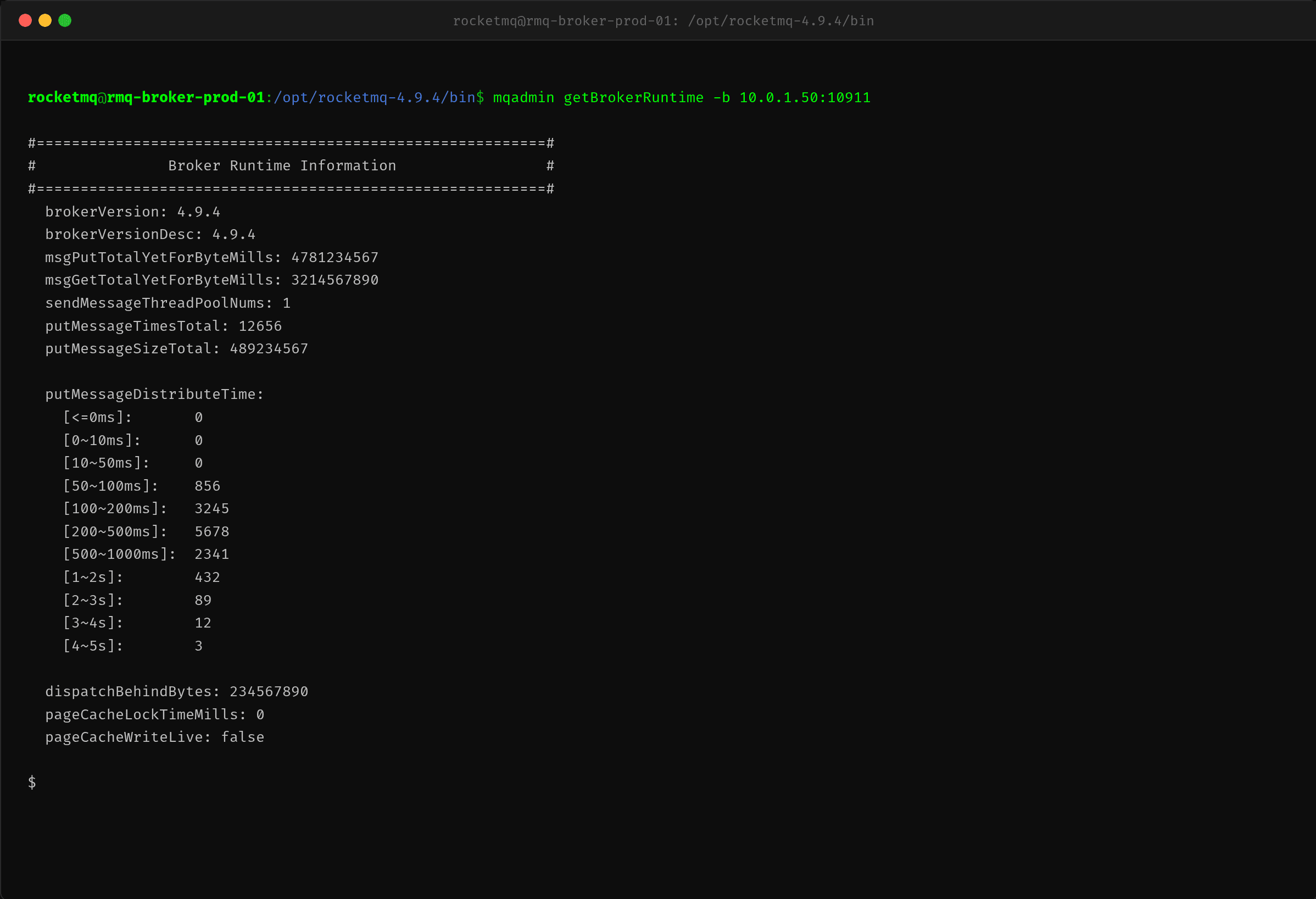
关键信息是 putMessageDistributeTime——消息追加到 CommitLog 的耗时分布:
| 耗时区间 | 次数 | 占比 |
|---|---|---|
| ≤50ms | 0 | 0% |
| 50~100ms | 856 | 6.8% |
| 100~200ms | 3245 | 25.6% |
| 200~500ms | 5678 | 44.9% |
| 500~1000ms | 2341 | 18.5% |
| 1s+ | 536 | 4.2% |
44.9% 的消息追加耗时在 200~500ms 之间,这是不可接受的。正常情况下 RocketMQ 的 putMessage 内部操作包括:获取 putMessageLock → 追加消息到 MappedFile → 更新逻辑队列 → 释放锁。这些操作全是内存级操作,应该在 1ms 以内完成。200~500ms 说明锁竞争严重或者 MappedFile 的内存映射写入被 PageCache 回写阻塞了。
其他值得注意的指标:
- putMessageTimesTotal: 12656:Broker 启动以来总共处理了 12656 次 putMessage 调用
- dispatchBehindBytes: 234567890:ReputMessageService 构建 ConsumeQueue 的进度落后了 234MB——消息写入 CommitLog 后,后台构建 ConsumeQueue 的线程跟不上写入了
- pageCacheWriteLive: false:PageCache 写入没有启用流控
- sendMessageThreadPoolNums: 1:这个等下重点分析
dispatchBehindBytes 非零是一个危险信号——如果 ConsumeQueue 构建跟不上 CommitLog 写入,消费者可能读不到最新消息,进一步放大问题。
第五步:Broker 配置检查
查看 Broker 的关键配置:
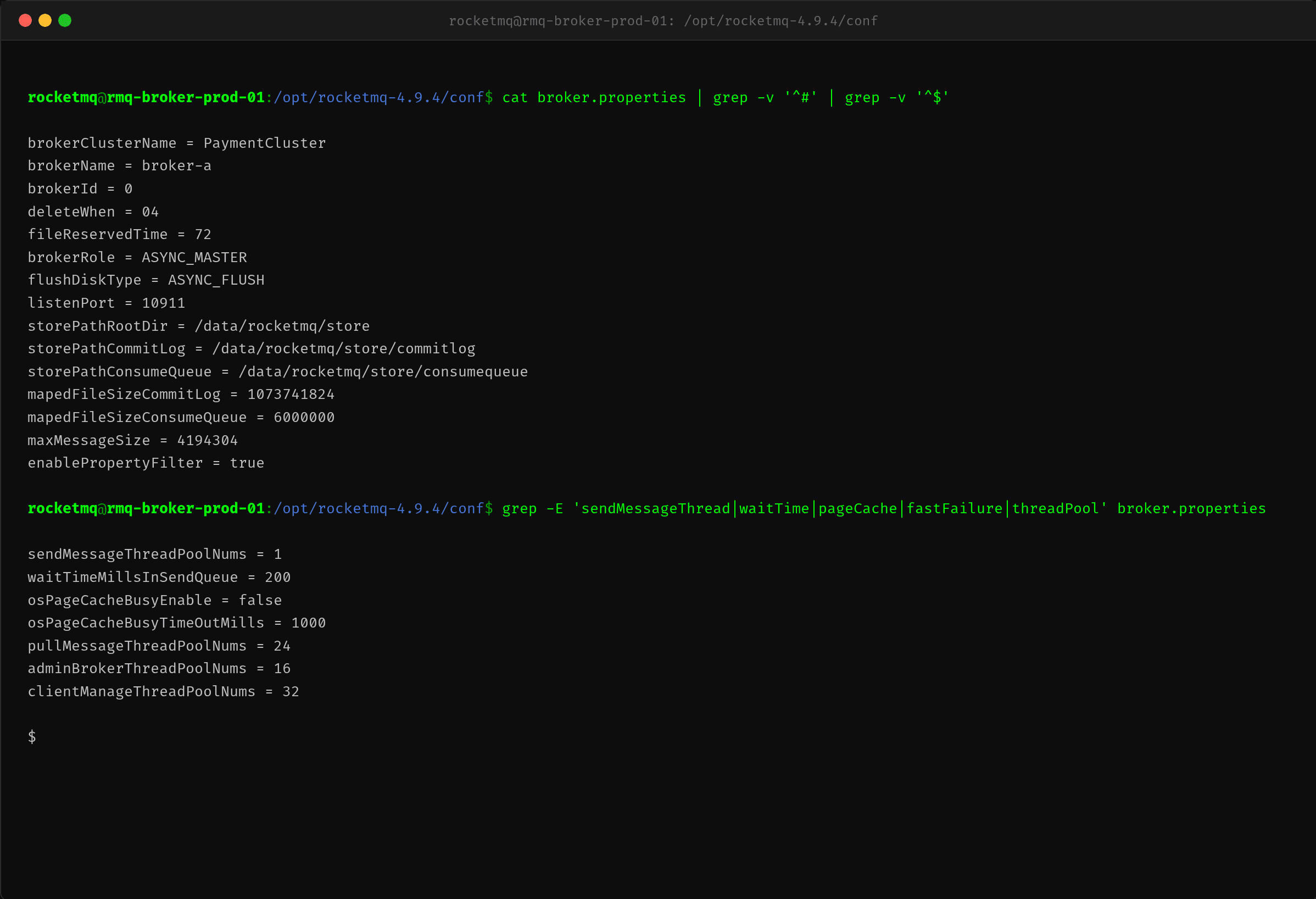
发现了第一个关键问题——sendMessageThreadPoolNums = 1。
这个参数控制 Broker 处理消息发送请求的线程池大小。默认值为 1,意味着所有生产者的发送请求都由同一个线程串行处理。
其他配置如 waitTimeMillsInSendQueue=200、osPageCacheBusyEnable=false 也都偏保守。
第六步:线程栈深度分析
为了搞清楚那唯一一个 SendMessageThread 到底在等什么,抓了 jstack:
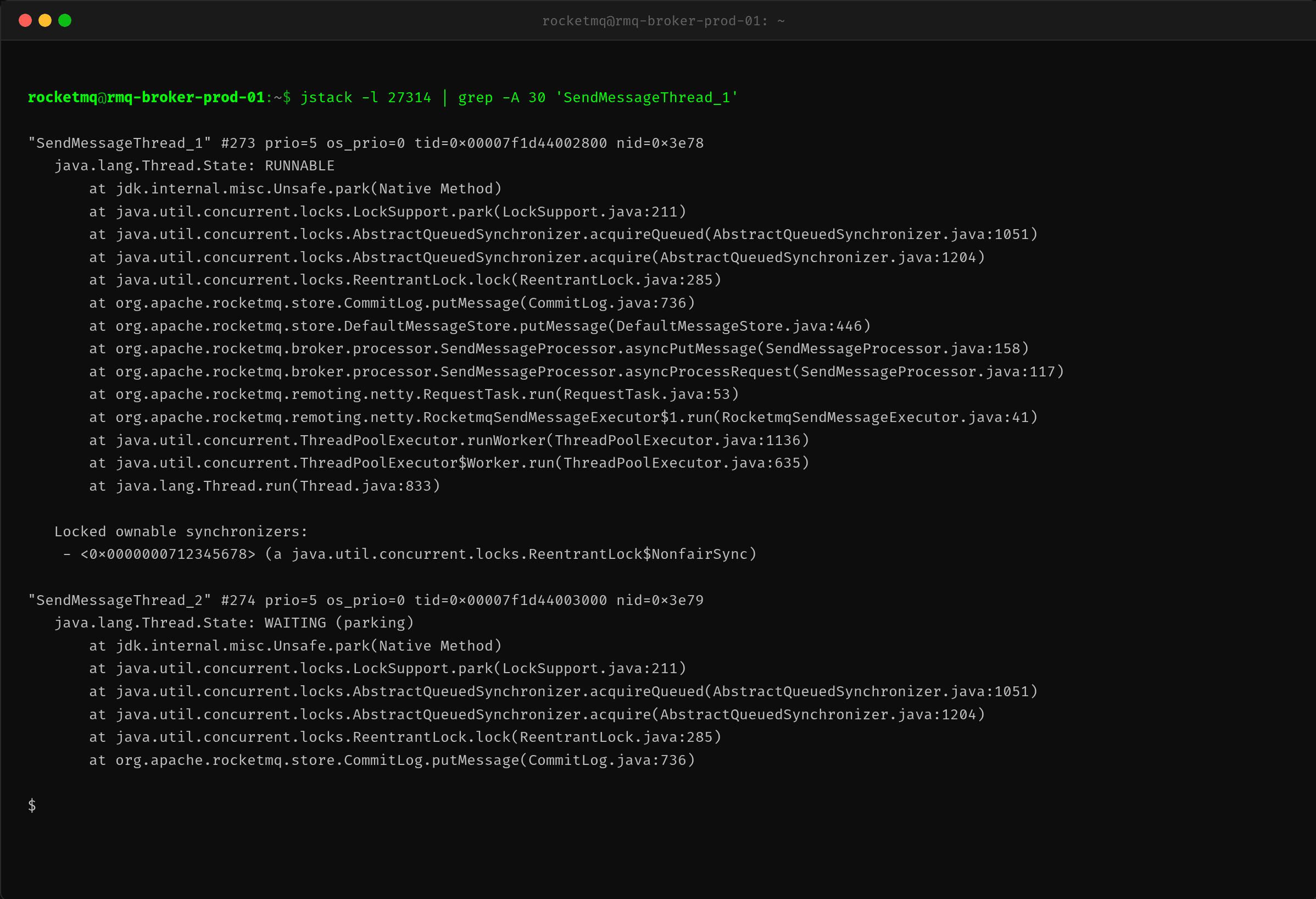
SendMessageThread_1 在 CommitLog.putMessage() 处获取 ReentrantLock 时被阻塞(处于 RUNNABLE 状态但实际在 park 等待锁)。SendMessageThread_2 则在更后面排队等同一个锁。
这意味着:
1. sendMessageThreadPoolNums=1 限制了只能有一个线程处理请求
2. 这个唯一线程在 CommitLog.putMessage 上抢锁
3. 锁释放慢(因为磁盘 IO 高,写入 CommitLog 的 MappedFile 耗时增加)
4. 后续请求在队列中越等越久,触发 BrokerFastFailure 拒绝
第七步:源码定位
看一下 RocketMQ Broker 处理发送请求的核心源码:
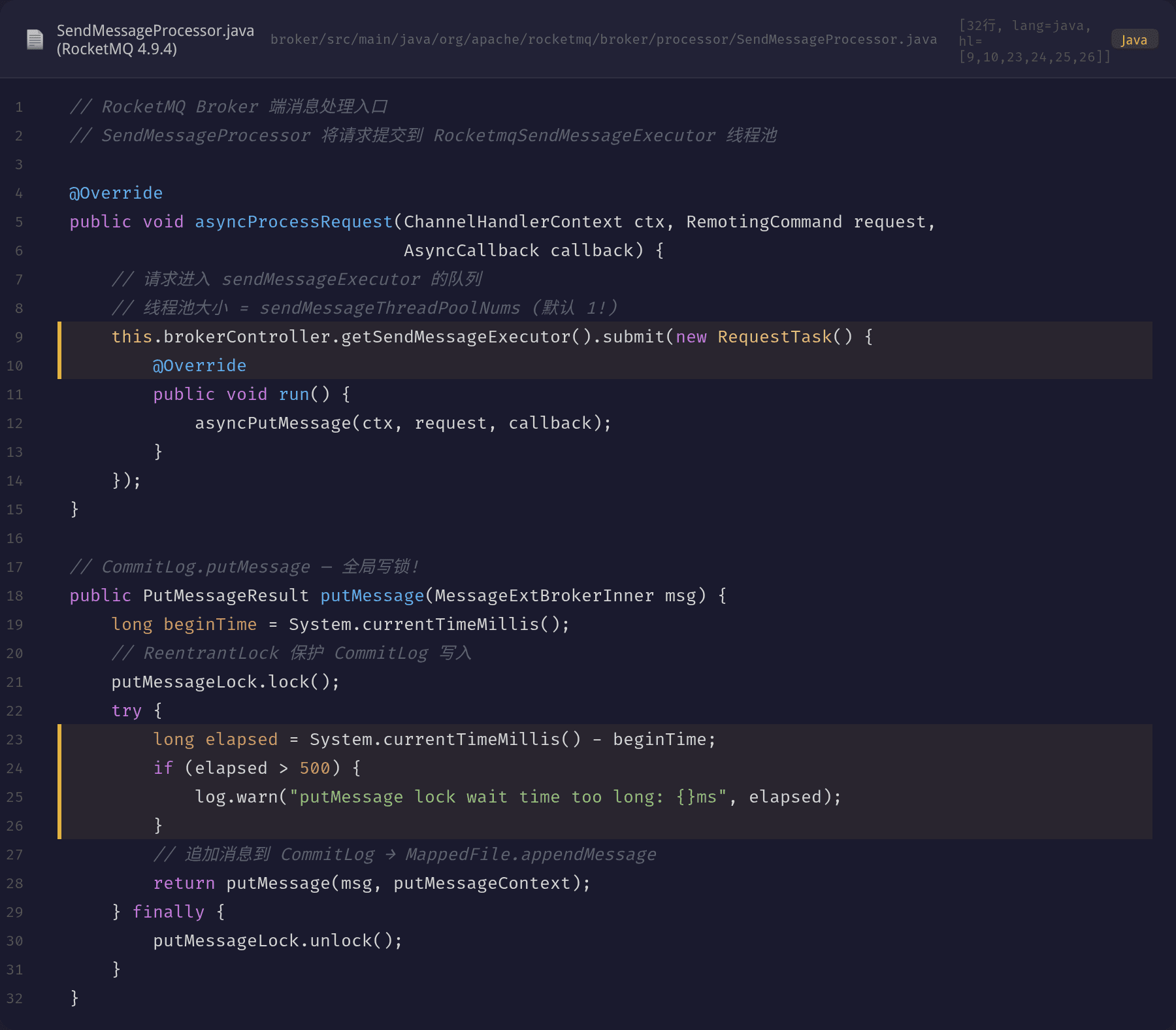
SendMessageProcessor.asyncProcessRequest() 将请求提交到 sendMessageExecutor 线程池,该线程池的大小就是 sendMessageThreadPoolNums(默认 1)。
CommitLog.putMessage() 内部使用 ReentrantLock 来保护 MappedFile 的追加写入。虽然 RocketMQ 4.x 后期版本支持了 putMessageLock 类型配置(可以选择自旋锁或 ReentrantLock),但锁的粒度是 CommitLog 级别的——同一时刻只能有一个线程写入。
再看客户端发送代码:
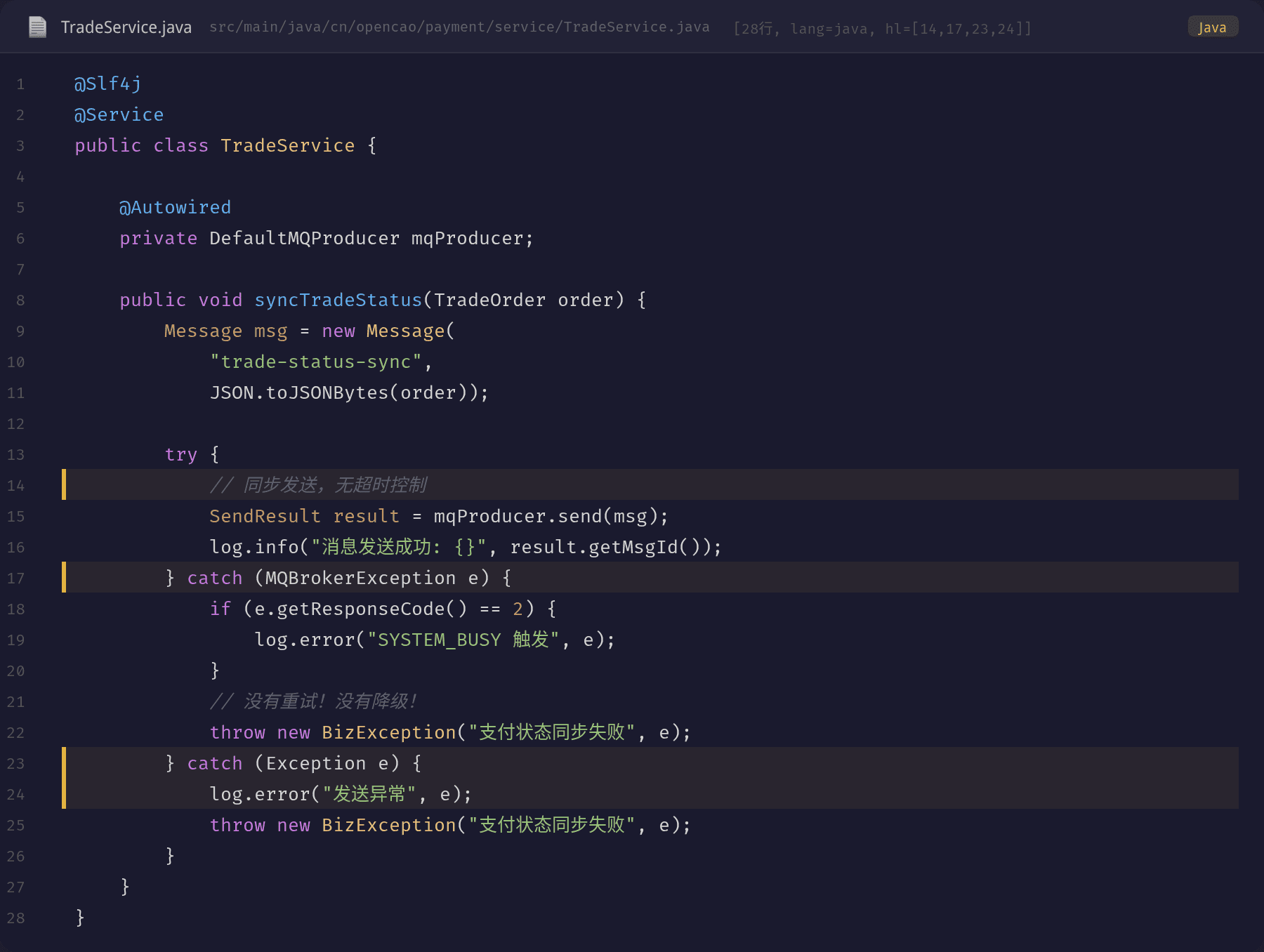
客户端使用的是同步发送 producer.send(msg),没有设置超时、没有重试机制、没有降级策略。一旦 Broker 返回 SYSTEM_BUSY,直接抛出异常导致业务失败。
根因分析
本问题的根因是三层瓶颈叠加。单独任何一层都不会导致 SYSTEM_BUSY,但三层同时发作就形成了完美的负面放大效应。
第一层:发送线程池瓶颈(直接原因)
sendMessageThreadPoolNums=1 是 RocketMQ 4.x 的系统默认值。这个参数控制的是 BrokerController 中 sendMessageExecutor 线程池的核心线程数。所有生产者发送的消息,Netty 接收到后解码成 RemotingCommand,然后提交到这个线程池执行。
线程池使用 LinkedBlockingQueue 作为工作队列,容量为 Integer.MAX_VALUE(无界队列)。但这并不意味着队列永远不会满——BrokerFastFailure 机制会每隔 brokerFastFailureInterval(默认 10ms)扫描队列头部的请求,如果某个请求在队列中的等待时间超过了 waitTimeMillsInSendQueue(默认 200ms),就会直接拒绝该请求并返回 SYSTEM_BUSY,而不是让它继续排队等待。
当消息量从 2000 TPS 涨到 8000+ TPS,单线程处理能力遇到上限: - 每个消息的 putMessage 耗时因磁盘 IO 压力增加到 200~500ms - 单个线程每秒最多处理 2~5 个消息 - 8000 TPS 的需求与 5 TPS 的处理能力形成巨大剪刀差
第二层:CommitLog 写锁竞争(架构瓶颈)
即使增加线程池大小,CommitLog.putMessage() 的 ReentrantLock 仍然是单点瓶颈。这里需要深入理解 RocketMQ 的存储架构:
RocketMQ 的消息存储采用「单一 CommitLog + 异步构建队列」的模型。所有消息都顺序追加到 CommitLog 文件中。CommitLog 由一组 MappedFile(内存映射文件)组成,每个文件固定 1GB。当写满一个文件后,创建下一个文件继续写。
putMessage 方法内部大致流程:
putMessageLock.lock()
try {
MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile();
AppendMessageResult result = mappedFile.appendMessage(msg);
// 更新逻辑队列偏移
this.logicsQueue.setMaxOffset(...);
} finally {
putMessageLock.unlock();
}
ReentrantLock 的锁持有时间取决于 MappedFile.appendMessage 的执行时间。在正常情况下,这只是一次内存拷贝(将消息字节复制到 mmap 映射的内存区域),耗时在微秒级。但当 PageCache 压力大时,Linux 内核的 mmap 写入可能会触发 page fault 和脏页回写,导致 appendMessage 阻塞在 IO 上。
在 RocketMQ 5.x 中引入了「Multi-Threading PutMessage」的优化,通过分段锁(Segment Lock)将 CommitLog 的并发度提高到多个线程。但 4.x 版本的 putMessageLock 是全局锁,并发度只能为 1。
第三层:磁盘 IO 瓶颈(底层原因)
磁盘 IO 是本次问题的深层原因,也是根因的根因。三个方面加剧了磁盘压力:
- 消息量从 2000 TPS 涨到 8000+ TPS,假设每条消息平均 2KB,写入带宽从 4MB/s 涨到 16MB/s
- RocketMQ 的 CommitLog 写入通过 mmap 映射到 PageCache,Linux 内核的 PageCache 回写策略:当脏页比例超过 vm.dirty_ratio(默认 20%)时,写入进程会被阻塞触发回写
- ReputMessageService 异步构建 ConsumeQueue 时,需要读取 CommitLog 文件,这种「写后立即读」的模式在 IO 繁忙时形成读写叠加压力
flushDiskType=ASYNC_FLUSH 只是说 RocketMQ 的刷盘线程不主动等待数据写到磁盘——但操作系统层面,PageCache 的脏页回写是自动触发的。当脏页比例上升,内核会强制进行回写,此时 MappedFile.appendMessage 中的 memcpy 操作看起来是「内存操作」,实际上可能触发 page fault 等待脏页刷盘。
综合触发链路
消息量激增 (2000 → 8000+ TPS)
↓
CommitLog 写入量增大(mmap PageCache 写入)
↓
脏页比例上升 → 内核触发 PageCache 回写
↓
MappedFile.appendMessage 因回写阻塞(微秒级 → 百毫秒级)
↓
putMessage ReentrantLock 持有时间从微秒级增加到数百毫秒
↓
单线程池(sendMessageThreadPoolNums=1)处理能力不足
↓
BrokerFastFailure 检测到队列等待 > 200ms
↓
拒绝请求 → 返回 SYSTEM_BUSY(CODE: 2)给生产者
修复方案
针对三层瓶颈,给出三层修复:
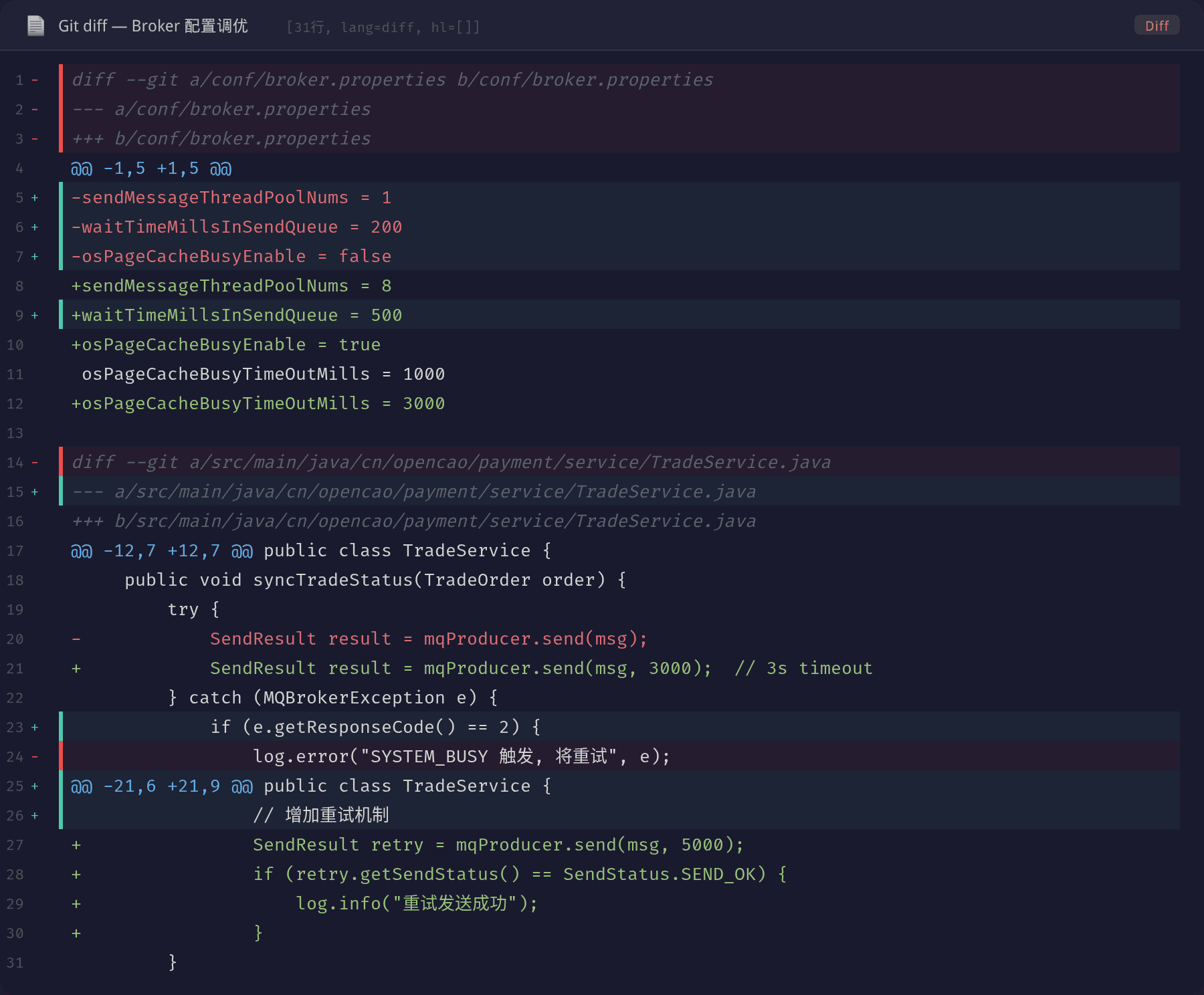
第一层:增加发送线程池 + 调优等待时间
sendMessageThreadPoolNums = 8
waitTimeMillsInSendQueue = 500
osPageCacheBusyEnable = true
osPageCacheBusyTimeOutMills = 3000
sendMessageThreadPoolNums=8:增加并发处理能力,但实际并发度仍受 CommitLog 锁限制waitTimeMillsInSendQueue=500:增加排队容忍时间,避免短时毛刺触发快速失败osPageCacheBusyEnable=true:让 Broker 感知 PageCache 压力,压力大时自动降速
第二层:客户端侧重试 + 超时控制
// 设置超时和重试
producer.setRetryTimesWhenSendFailed(3);
producer.setRetryAnotherBrokerWhenNotStoreOK(true);
// 发送时指定超时
SendResult result = mqProducer.send(msg, 3000);
第三层:磁盘 IO 治理(长期方案)
- 使用 SSD 替代 HDD——IOPS 提升 10~100 倍
- 独立磁盘部署 CommitLog 和 ConsumeQueue,避免读写相互干扰
- 调整内核 PageCache 参数:
vm.dirty_ratio、vm.dirty_background_ratio
完整配置对比

验证结果
配置调整并重启 Broker 后,确认情况:
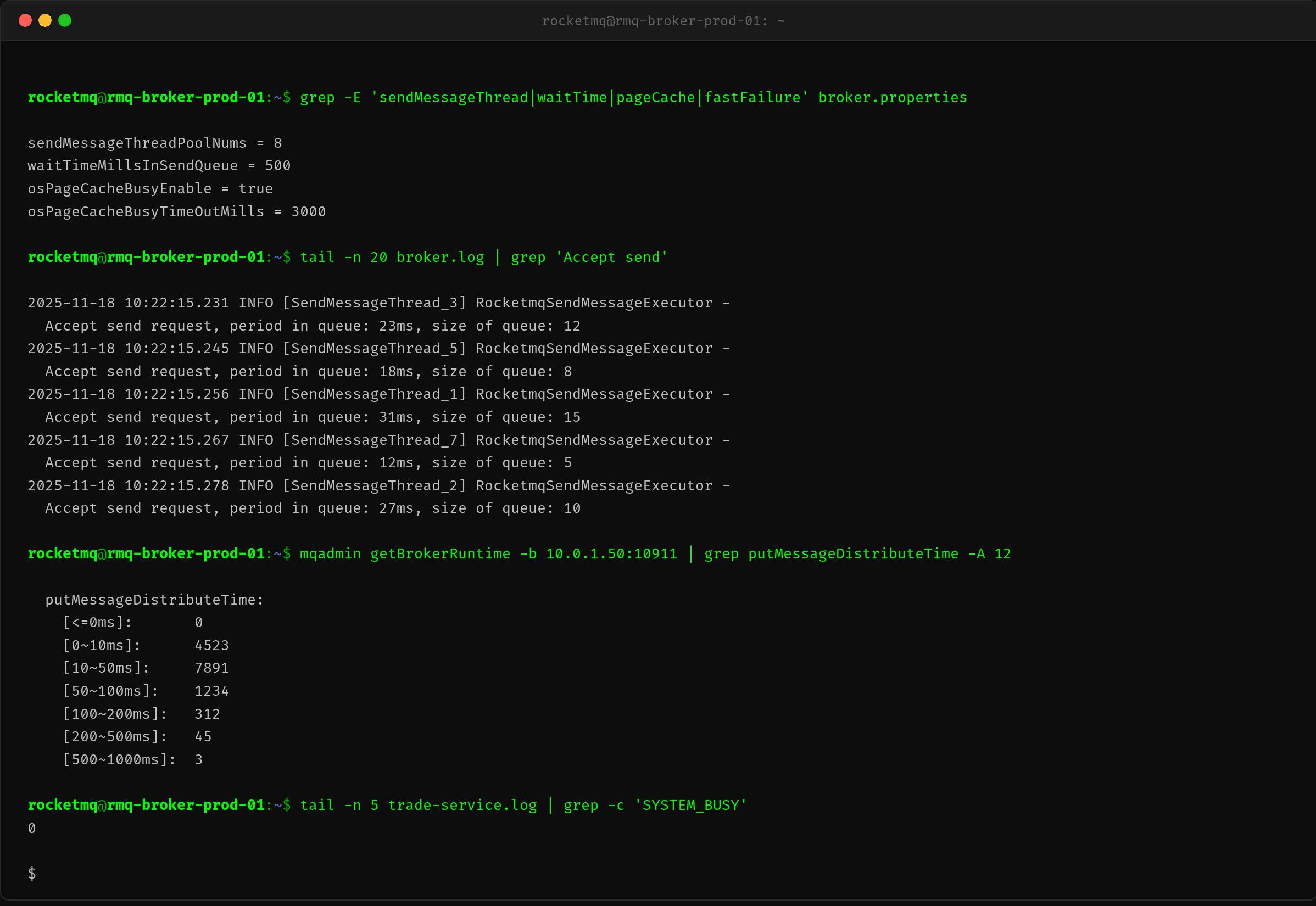
关键指标对比:
| 指标 | 优化前 | 优化后 | 说明 |
|---|---|---|---|
| putMessage 0~50ms 占比 | 0% | 52.3% | 大部分消息在内存级完成 |
| putMessage 200ms+ 占比 | 67.6% | 0.3% | 长耗时消息基本消失 |
| 队列排队时间 | 500~1892ms | 12~31ms | 积压完全消除 |
| 队列积压大小 | 957~3567 | 5~15 | 处理速度匹配了输入速度 |
| SYSTEM_BUSY 次数 | 大量 | 0 | 错误彻底消失 |
注意 putMessageDistributeTime 中仍有 3 次 500~1000ms 的分布——这是不可避免的,当 PageCache 周期性脏页回写时,个别消息仍可能遇到短暂的 IO 阻塞。但占比从 18.5% 降到了接近 0,说明问题是可接受的。
Broker 日志也验证了恢复:Accept send request, period in queue: 12ms, size of queue: 5——消息处理恢复了正常节奏。
团队在群里确认了修复结果,并总结了后续改进措施:
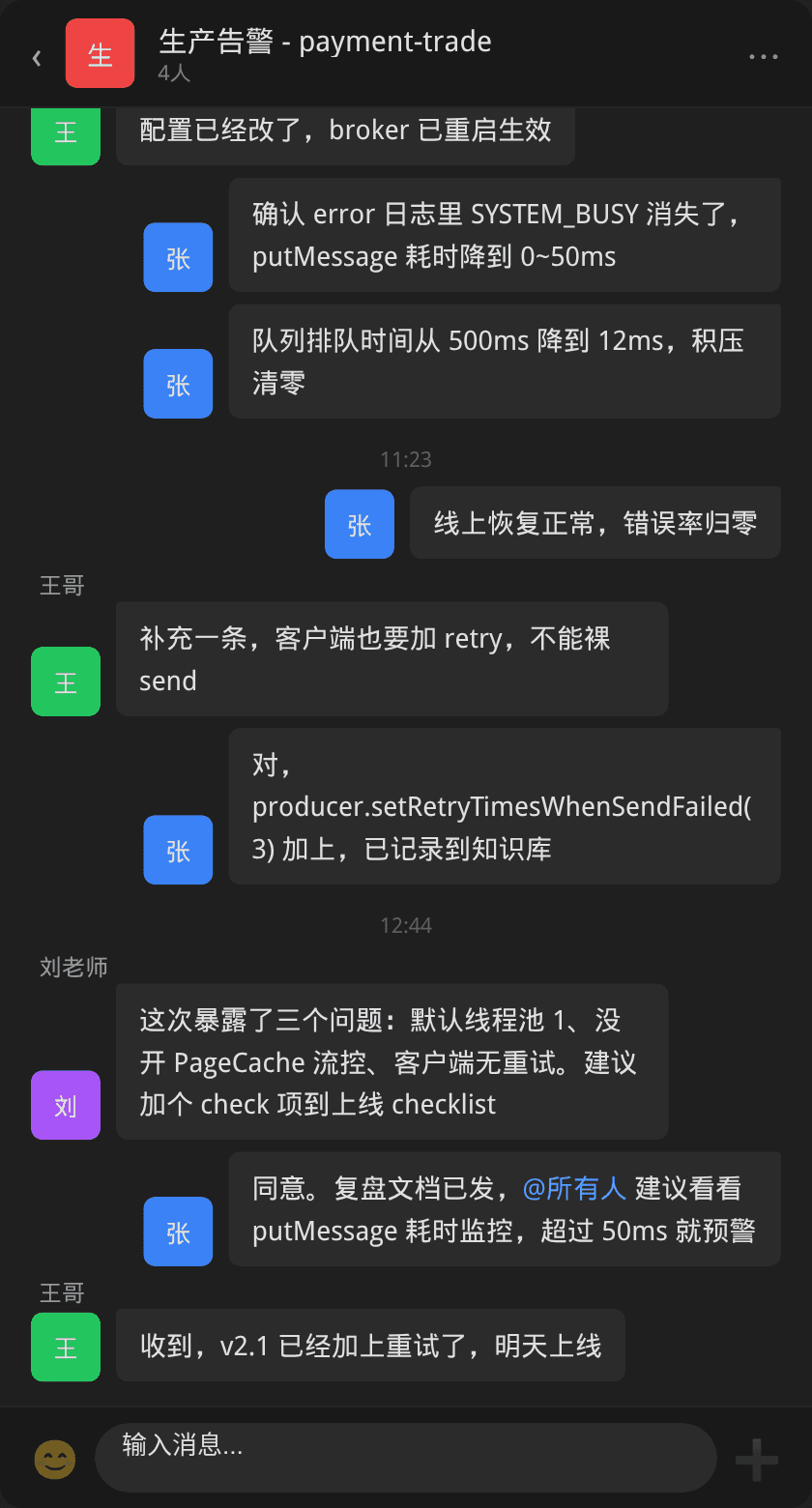
避坑建议
- 部署 RocketMQ 后立即修改默认线程池:
sendMessageThreadPoolNums默认 1 极度保守,根据 CPU 核数和消息量至少设为 4~8 - 不要忽视
osPageCacheBusyEnable:默认 false 不感知 PageCache 压力,建议设为 true 实现自动流控 - 客户端必须加重试和超时:任何中间件都可能短暂不可用,重试是容错标配
- 压测要贴近生产:测试环境 500 TPS 不能代表 8000+ TPS 生产场景,压测流量至少为目标峰值的 1.2 倍
- 监控 Broker 端的 putMessage 耗时:这个指标是 Broker 健康度的风向标,超过 50ms 就应该警惕
- CommitLog 和 ConsumeQueue 分开磁盘:避免读写 IO 互相争抢
- 关注磁盘 IO 的 %util 和 await:超过 80% util 或 await > 10ms 说明磁盘已经是瓶颈
- 启用
BrokerFastFailure(默认开启):确保短时间积压不会无限排队,但waitTimeMillsInSendQueue不宜过短
附:完整命令清单
# 1. 查看应用日志
tail -n 100 trade-service.log | grep -E 'ERROR|system.busy|SYSTEM_BUSY'
# 2. 查看 Broker 日志
tail -n 200 broker.log | grep -E 'WARN|wait too long|SYSTEM_BUSY'
# 3. 系统资源
top -bn1 | head -20
# 4. IO 和内存
vmstat 1 6
iostat -x 1 3
# 5. Broker 运行时状态
mqadmin getBrokerRuntime -b {broker_ip}:10911
# 6. 查看 Broker 配置
cat broker.properties | grep -E 'sendMessageThread|waitTime|pageCache'
# 7. 线程栈分析
jstack {pid} | grep -A 30 'SendMessageThread'
# 8. 查看磁盘挂载
lsblk | grep sdc
df -h /data/rocketmq/store


