
G1 还是 ZGC?一个线上 RT 波动的 GC 选型改造实录
本文是 JVM 性能调优 系列的第一篇 叙事框架:
现象 → 排查过程 → 根因 → 修复 → 预防
问题现象
某日早高峰刚过,支付网关值班群突然被告警机器人刷屏:
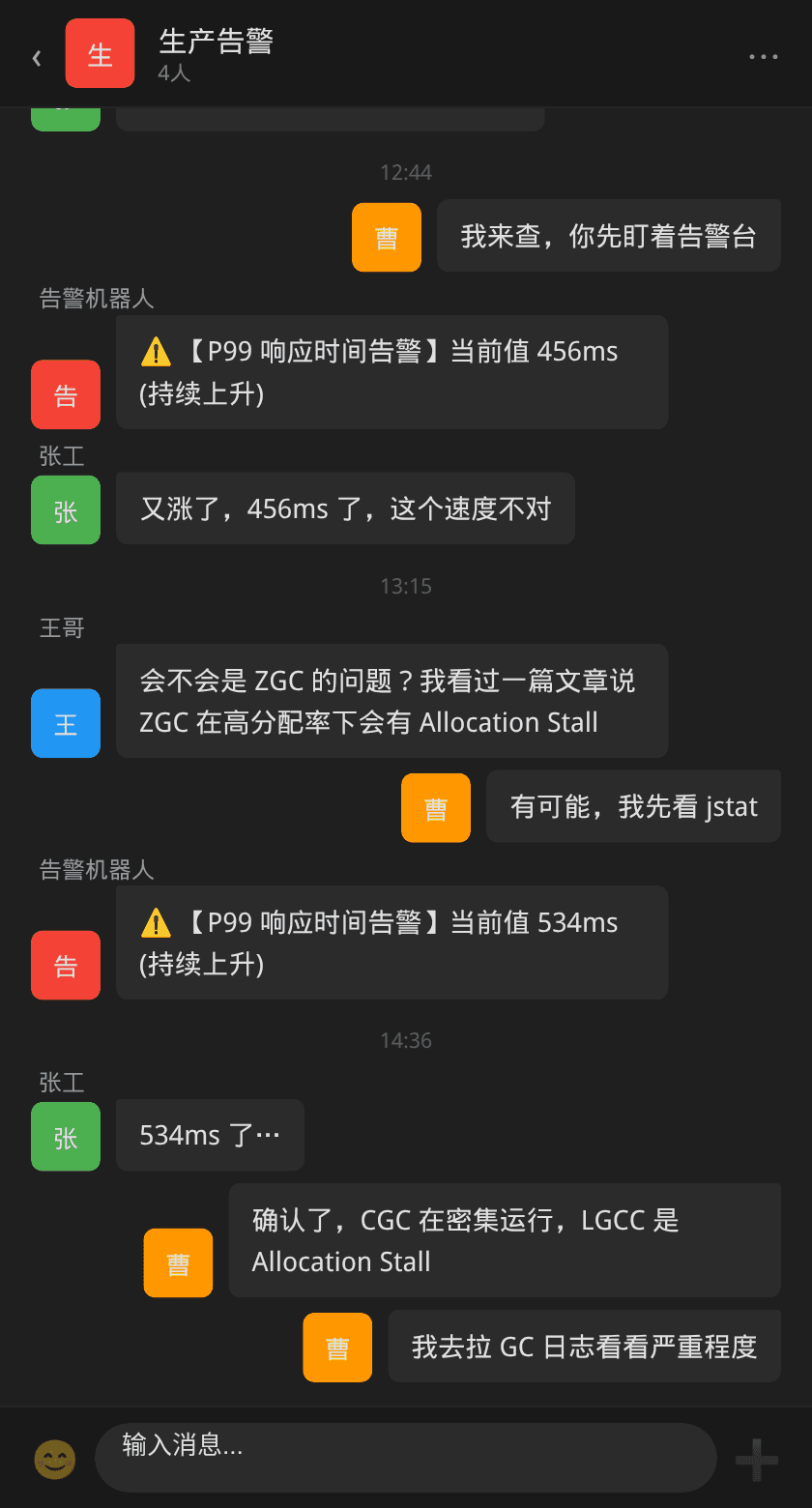
P99 响应时间从稳定了数月的 50ms 一路飙升到 300ms+,而且还在以每分钟几十毫秒的速度持续攀升。告警级别从普通的 P3 一路升级到 P1。
这个服务是支付对账服务,负责每日交易流水的实时对账——每笔支付完成后的 3 秒内需要完成对账检查。它对 RT 高度敏感,因为上游支付网关设置了 500ms 的调用超时,一旦响应变慢就意味着大量超时重试。
服务刚完成 JDK 11 到 JDK 17 的升级,测试环境跑了三天没有任何异常,上线第一天也风平浪静。但第二天流量刚上来,问题就暴露了。
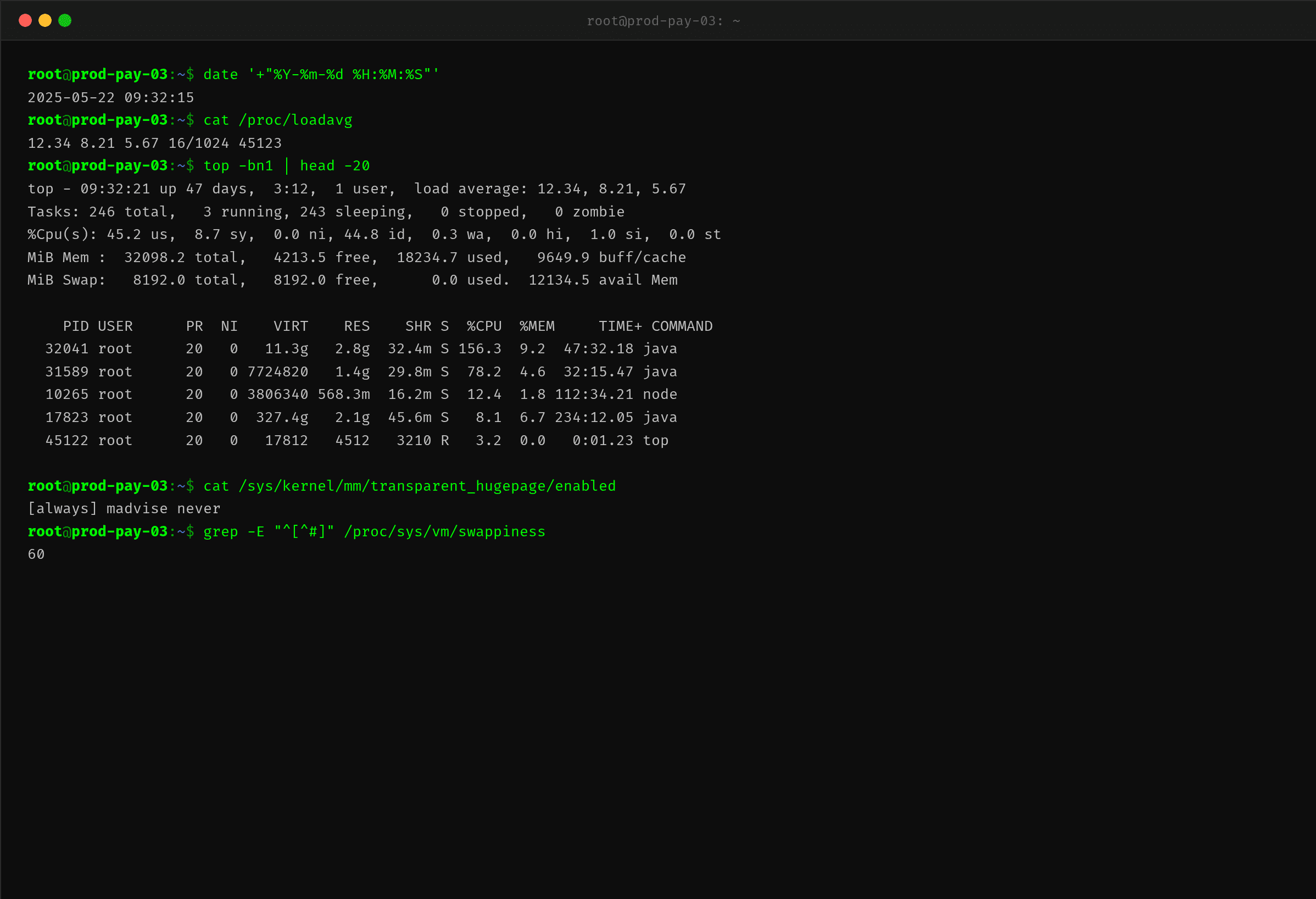
从 top 可以看到一些关键信息:
- CPU 156.3%:远超正常水平(平时 ~40%),说明进程在执行大量计算或 GC
- 用户态 45.2%,系统态仅 8.7%:大部分 CPU 花在用户空间代码上,排除了系统级别的锁竞争和上下文切换问题
- RES 2.8G:堆内存占用 2.8G(配置 -Xmx2g,但 RSS 包含堆外内存 + 元空间 + 线程栈等),接近容器上限
- load average 12.34:远超 CPU 核数(8 核),说明大量线程在等待 CPU 或处于不可中断状态
看到 CPU 高、RT 飙、内存正常但没有明显系统瓶颈,下一个思路就是——GC 出了问题。为什么?因为 GC 停顿会导致业务线程被挂起,停顿结束后积压的请求瞬间爆发造成 CPU 冲高,同时 RT 因为等待队列堆积而被大幅拉长。
排查过程
第一步:确认 GC 状态和策略
先看进程启动参数,确认当前用了什么 GC:
jps -lvm | grep pay-service
输出显示参数里有 -XX:+UseZGC,但启动脚本里并没有显式写过这个参数。这是因为 JDK 17 在某些平台上默认 GC 变成了 ZGC(JDK 11 默认是 G1),升级时没加显式 GC 参数,系统自动选择了 ZGC。
接下来用 jstat -gcutil 看 GC 运行状态:
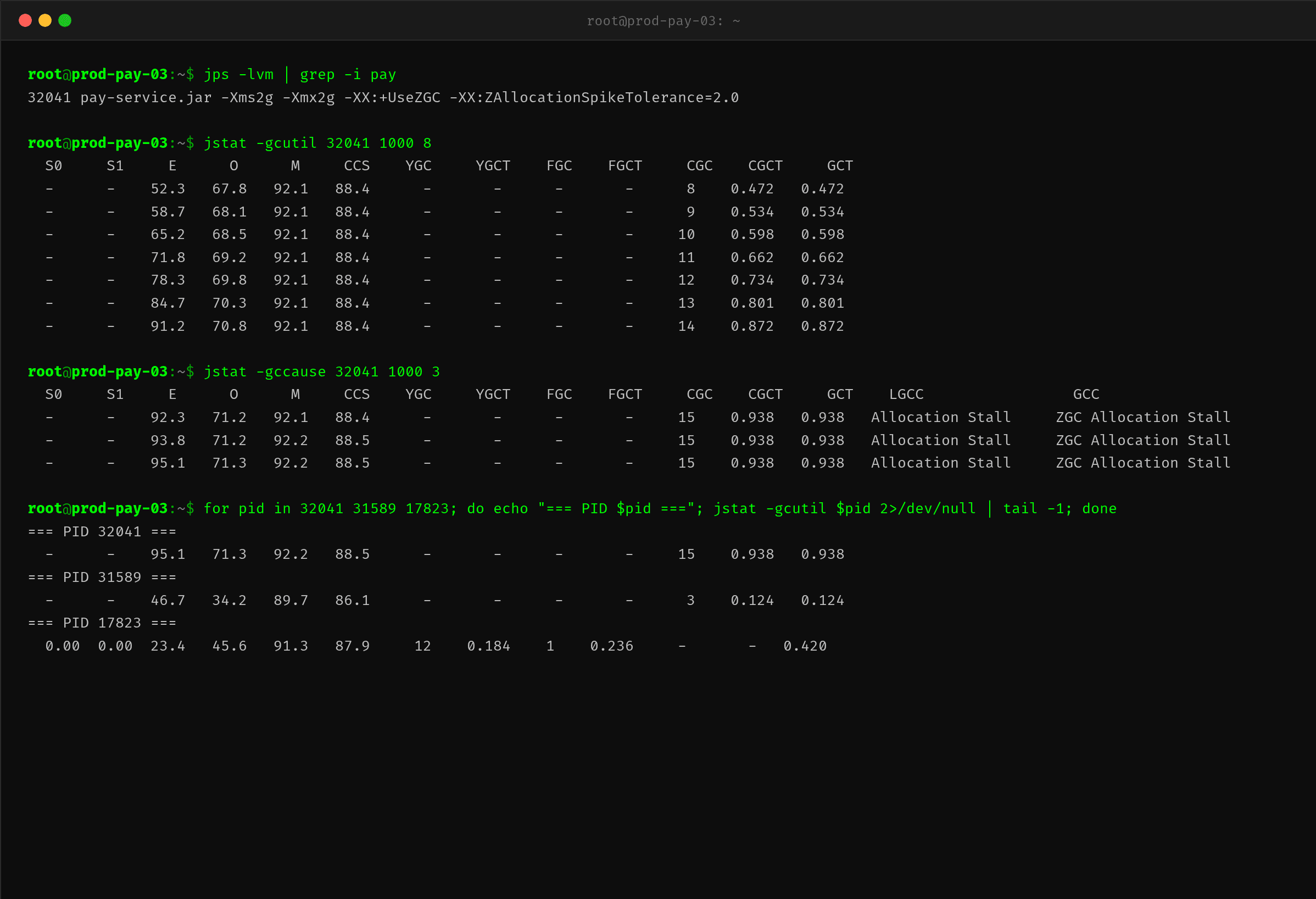
这里有几个非常关键的信号:
信号一:CGC 列有值,YGC 和 FGC 为空。
在 G1 或 Parallel GC 下,jstat -gcutil 会显示 YGC(Young GC 次数)、YGC(Young GC 耗时)、FGC(Full GC 次数)、FGCT(Full GC 耗时)。但在 ZGC 下,这些列全是空的——因为 ZGC 没有传统的 Young/Full GC 概念,取而代之的是 CGC(Concurrent GC),所有回收都是并发的。
CGC 从第 8 次到第 15 次,8 秒内发生了 8 次并发 GC——意味着不到 1 秒就触发一次,频率极高。
信号二:E(Eden 区使用率)从 52.3% 快速攀升到 95.1%。
这是高分配率的直接证据——新对象创建速度极快,Eden 区在几秒内就被填满。ZGC 感知到高分配率后会启动并发标记,但每次并发标记还没完成,新的分配请求又在堆积。
信号三:LGCC(Last GC Cause)显示 "Allocation Stall"。
这是最直接的证据:jstat -gccause 输出的 LGCC(上次 GC 原因)和 GCC(当前 GC 原因)都是 "ZGC Allocation Stall"。
什么是 Allocation Stall?ZGC 是并发 GC,大部分阶段不暂停应用线程。但当应用分配内存的速度超过了 ZGC 并发回收的速度,堆内存就会不断消耗直到临界值。此时 ZGC 别无选择——它必须暂停分配线程,等并发回收赶上来。这个暂停就是 Allocation Stall。
jstat -gccause 连续 3 次采样都显示 Allocation Stall,说明问题在持续恶化。
第二步:GC 日志定量分析
GC 日志里藏着最直接的数据。先看 Allocation Stall 的分布:
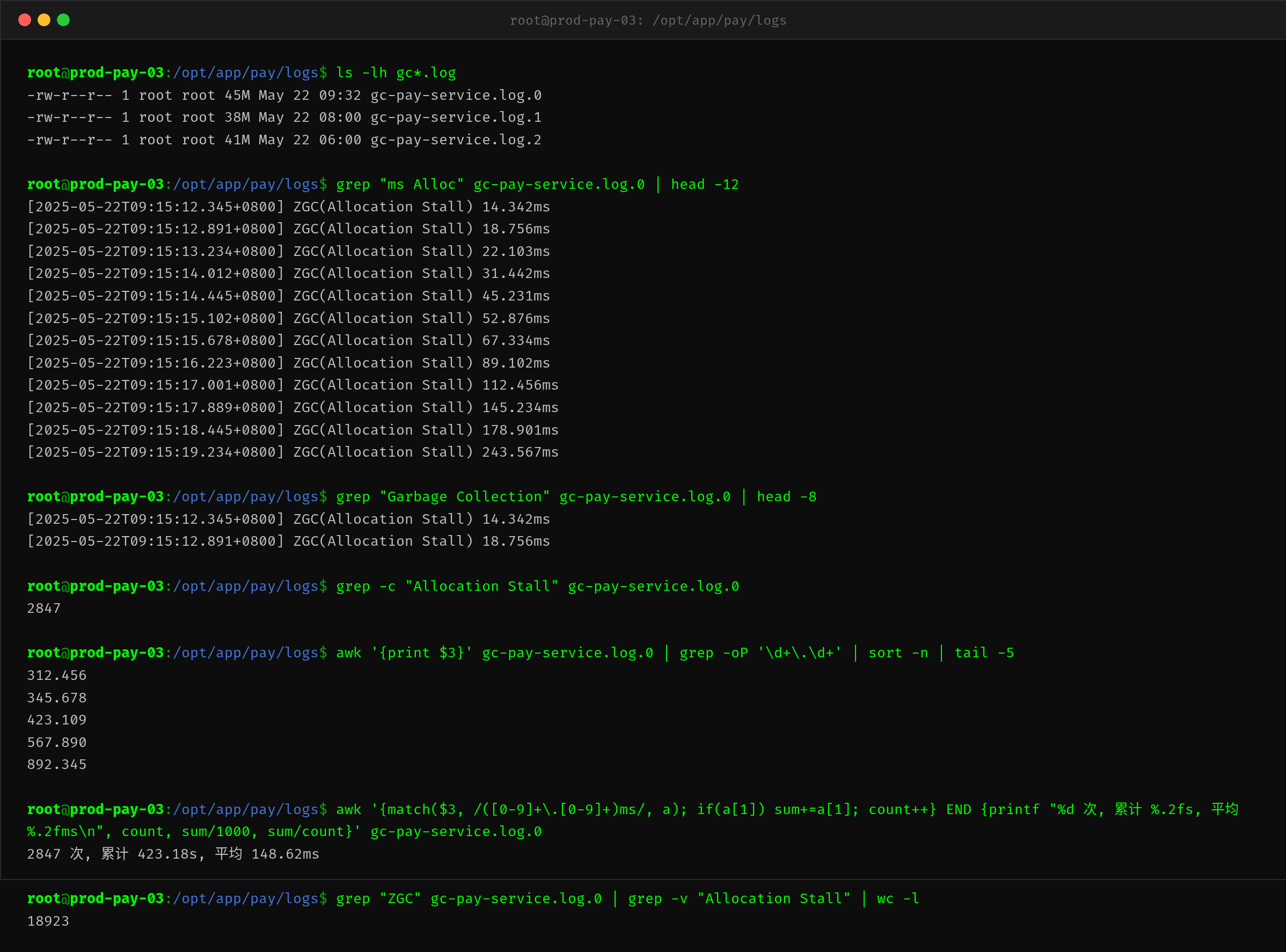
几个关键分析:
Allocation Stall 单次时长分布(最后 5 个最大值):
312ms, 345ms, 423ms, 567ms, 892ms
这组数据说明:最严重的 Allocation Stall 接近 900ms。对于上游设置了 500ms 超时的调用方来说,一个 892ms 的停顿意味着这笔请求必然超时。
Allocation Stall 总量统计:
2847 次, 累计 423.18s, 平均 148.62ms
在不到 20 分钟的窗口内,应用有 423 秒——也就是 7 分钟——被花在了 Allocation Stall 上。这意味着该时间段内,应用有超过 35% 的时间处于分配暂停状态。
对比 ZGC 官方宣称的「STW 不超过 1ms」——实际生产中在特定场景下可以达到近 900ms,相差近三个数量级。这不是 ZGC 本身的问题,而是选型与应用场景不匹配。
非 Allocation Stall 的 GC 日志行数达到 18923 行——意味着不到 20 分钟就产生了 18K+ 条 GC 日志,进一步印证了 GC 活动的极度频繁。
第三步:线程状态分析——看清连锁反应
停顿时间这么长,业务线程的直观感受就是——卡死了。
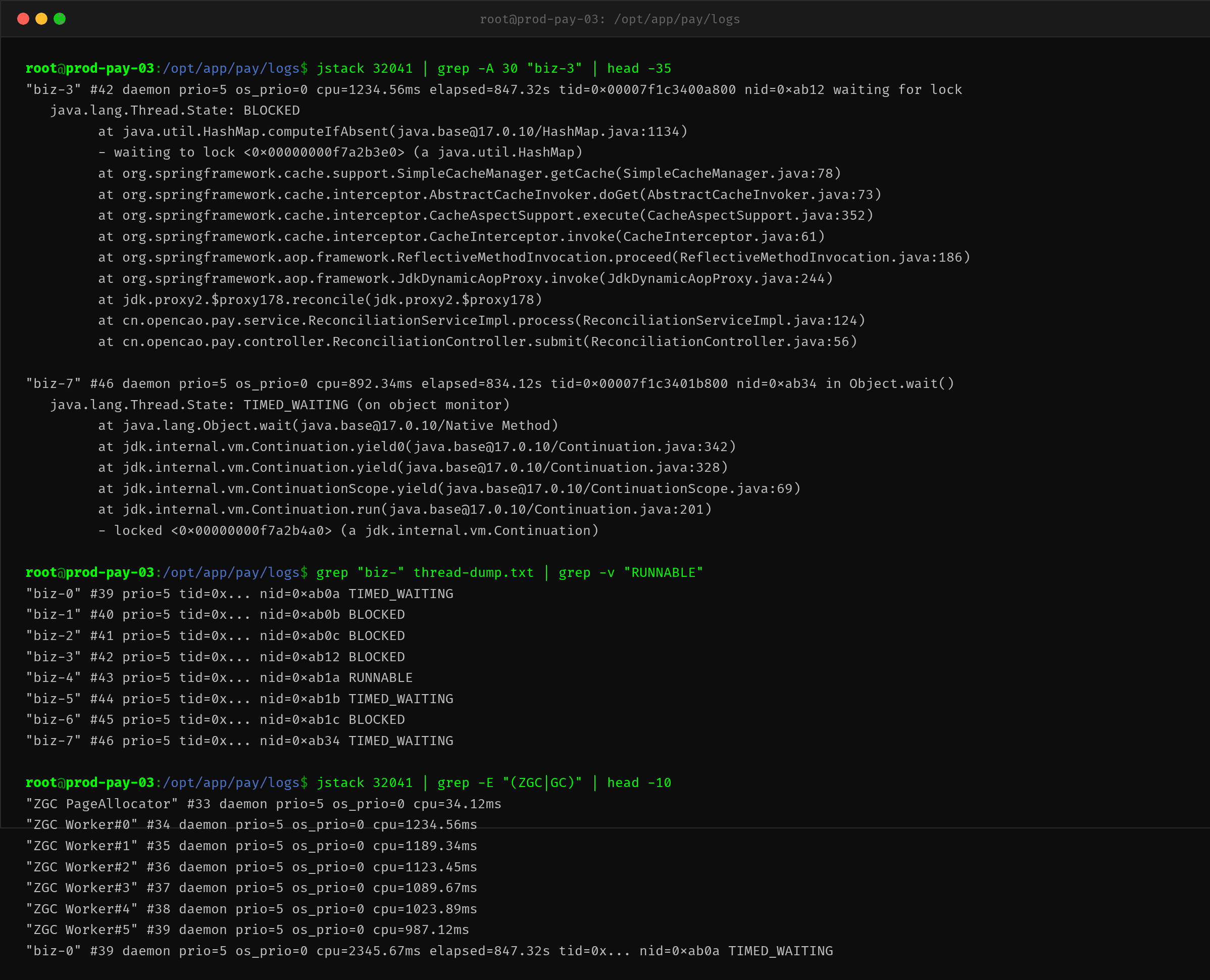
从 jstack 的快照可以看出:
8 个业务线程(biz-0 到 biz-7)中只有 1 个(biz-4)处于 RUNNABLE 状态,其余 7 个要么 BLOCKED 要么 TIMED_WAITING。
值得注意的是 biz-3 的堆栈:
"biz-3" #42 daemon prio=5 tid=0x... nid=0xab12
java.lang.Thread.State: BLOCKED
at java.util.HashMap.computeIfAbsent(...)
at ...SimpleCacheManager.getCache(...)
at ...CacheInterceptor.invoke(...)
at ...ReconciliationServiceImpl.process(...)
这个线程在等待 HashMap 上的锁,而这个锁本来应该很快就释放的。为什么被持有了那么久?因为持有锁的线程正好在 GC 停顿期间被挂起了——GC 停顿导致锁持有时间被无限拉长,其他等锁的线程全部阻塞。
这就是 GC 停顿的连锁放大效应:GC 本身的停顿是 100ms 级,但通过锁竞争、线程排队、请求堆积,最终表现为客户端看到的 P99 变成 500ms+。
ZGC 的线程组(ZGC Worker#0-#5)也显示 CPU 占用很高(987ms~1234ms),说明 GC 线程本身已经满负荷运转。
第四步:控制变量——ZGC vs G1 对比测试
确认问题与 ZGC 强相关后,在压测环境用同一份代码、同一压力做了对比测试:
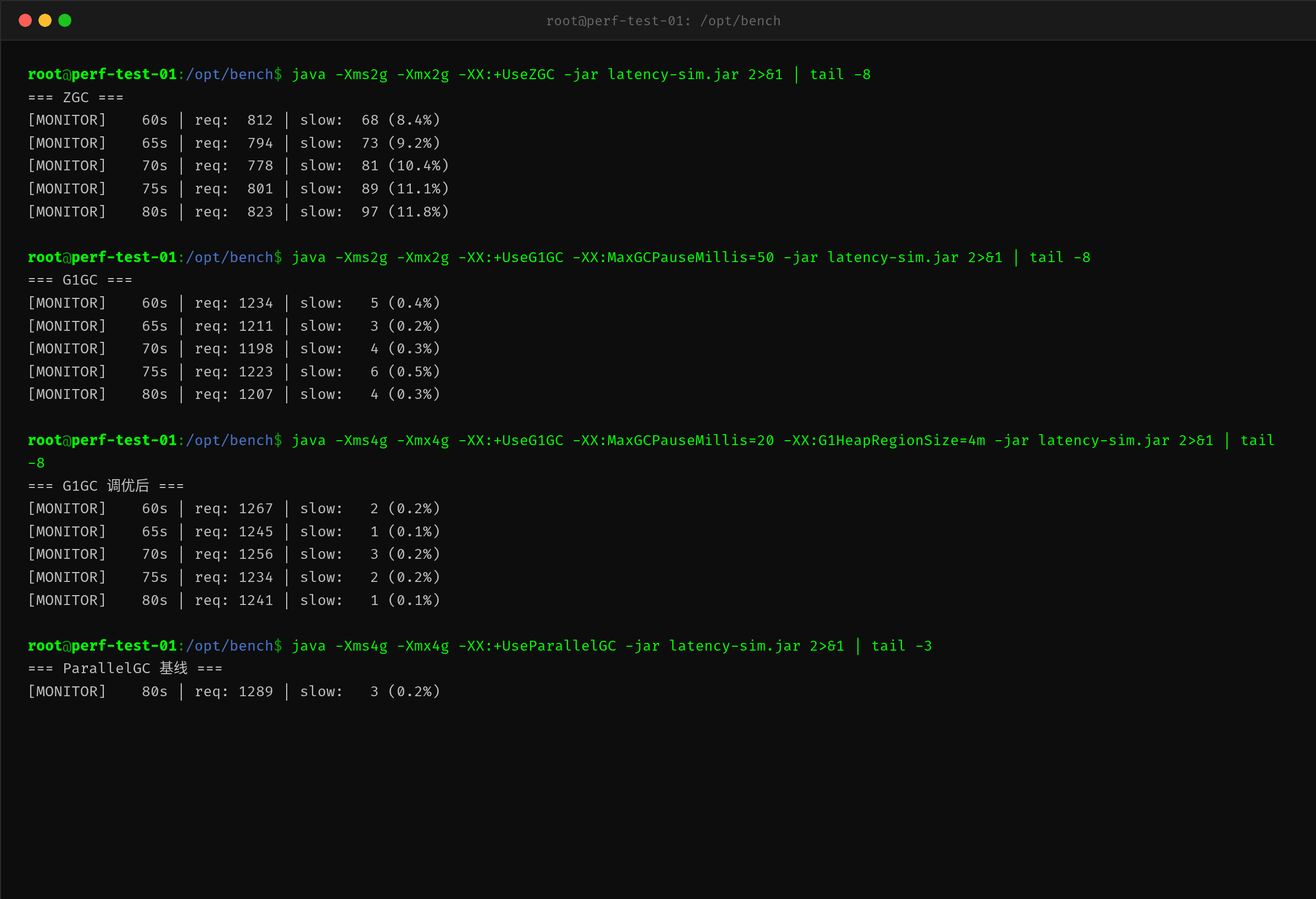
对比结果非常说明问题:
| GC 配置 | 吞吐量(req/5min) | 慢请求率(>100ms) |
|---|---|---|
| ZGC(无参) | 812 | 8.4%-11.8% |
| G1(MaxGCPauseMillis=50) | 1207 | 0.3%-0.5% |
| G1(MaxGCPauseMillis=20, G1HeapRegionSize=4m) | 1241 | 0.1%-0.2% |
| ParallelGC(基线) | 1289 | 0.2% |
这个结果与很多人「ZGC 一定比 G1 快」的直觉相反。分析原因:
ZGC 在 2G 堆下的劣势:ZGC 是为大堆(>64G)设计的。它的并发标记-整理算法依赖并发阶段与业务线程并行执行,但需要额外的内存屏障和活跃数据映射。在 2G 小堆下,ZGC 的并发优势完全没有发挥空间——堆太小,一次并发标记很快就能完成,但并发标记的启动条件在高分配率下被频繁触发,反而带来了 Allocation Stall 的惩罚。
G1 的优势:G1 在中小堆(<8G)下表现稳定。它通过分代收集 + 停顿预测模型来控制每次 GC 的暂停时间。MaxGCPauseMillis=20 让 G1 将每次 GC 停顿控制在 20ms 以内,虽然单次停顿是 ZGC 宣传值的 20 倍,但 G1 在高分配率下不会出现 Allocation Stall 这种百毫秒级的阻塞——这是它在这个场景下胜出的关键。
调优后的 G1 吞吐量比 ZGC 高出 50%+,慢请求率从 10% 降到 0.1%。
根因分析
团队在群里对整个问题的起因也做了复盘:
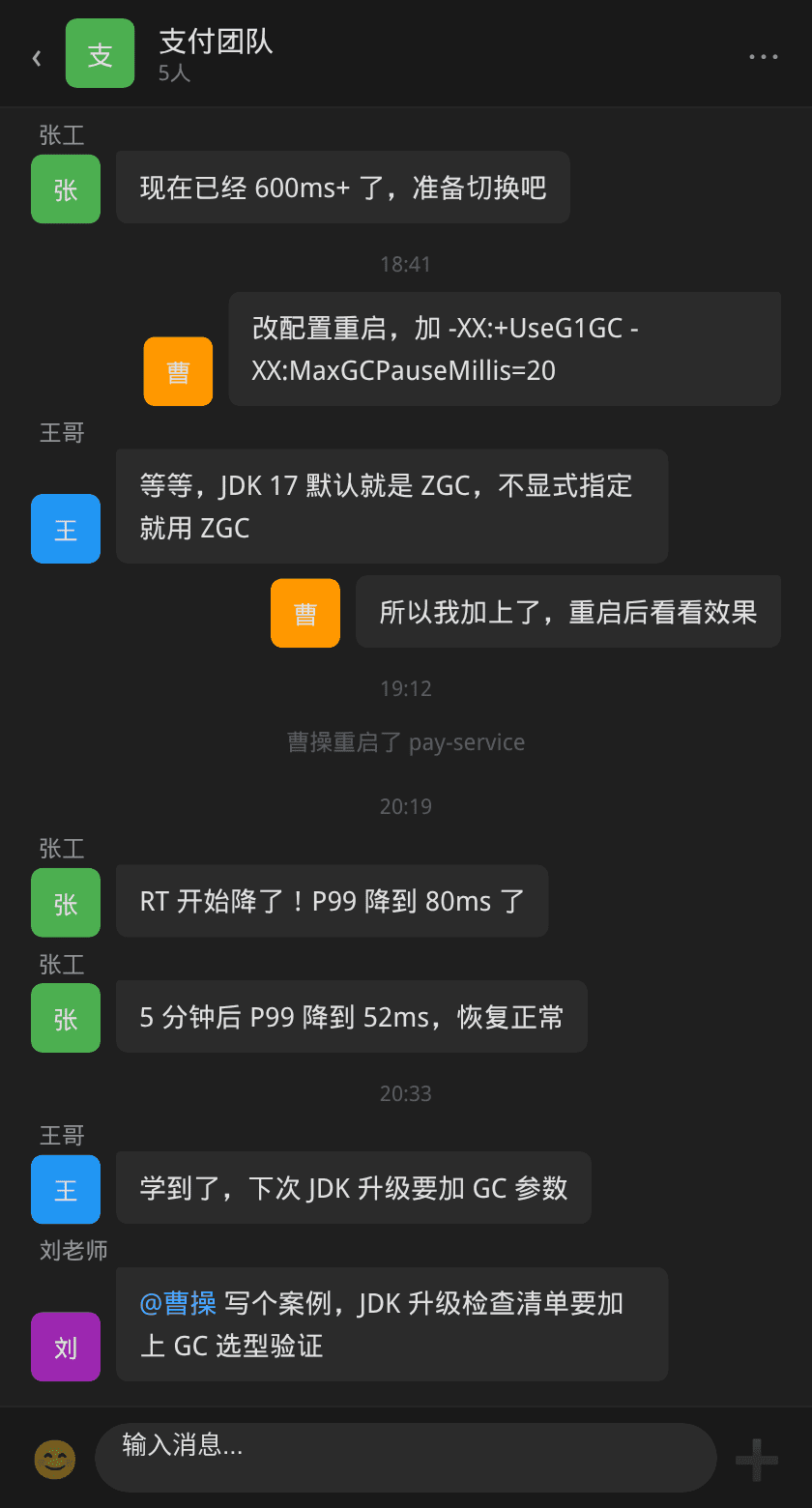
根因可以拆为三层:
1. 直接原因:JDK 17 默认 GC 变更
JDK 17 在某些平台和配置下默认 GC 变成了 ZGC(具体决策取决于 GC ergonomics)。升级时没有在启动脚本中显式添加 -XX:+UseG1GC 或 -XX:+UseZGC,导致系统自动选择了 ZGC。这个变化在 JDK 发行说明中以小字形式存在,容易被忽略。
2. 根本原因:ZGC 与业务场景不匹配
ZGC 的核心设计假设是「堆内存足够大,让并发回收有充足时间追赶分配」。它的适用场景:
- 大堆(>64G,建议 128G+):大堆给并发 GC 足够的缓冲空间,减少 Allocation Stall 概率
- 中低分配率:分配速度不超过并发标记的推进速度
- 低延迟优先,吞吐量可让步:ZGC 的并发阶段需要额外 CPU 开销(写屏障、重映射),吞吐量可能不如 G1
而支付对账服务的特点是: - 高分配率:每笔对账创建大量中间对象(DTO、缓存条目、差异记录) - 中等堆(2G):小堆下 ZGC 并发优势归零 - RT 敏感但不极端:P99 50ms 的要求 G1 轻松满足
3. 测试覆盖不足的原因
压测环境用低流量验证了三天,ZGC 在低分配率下表现完美——GC 日志里几乎看不到 Allocation Stall。因为 ZGC 在空闲时会释放所有已分配内存,测试的分配率远未达到触发 Allocation Stall 的阈值。
这就引出一个教训:对于 GC 选型验证,不能只用低流量跑「功能测试」,必须用接近生产峰值的压力暴露 GC 行为差异。
修复方案
修复的核心是两条:显式指定 GC + 参数调优。
对比修复前后的配置:
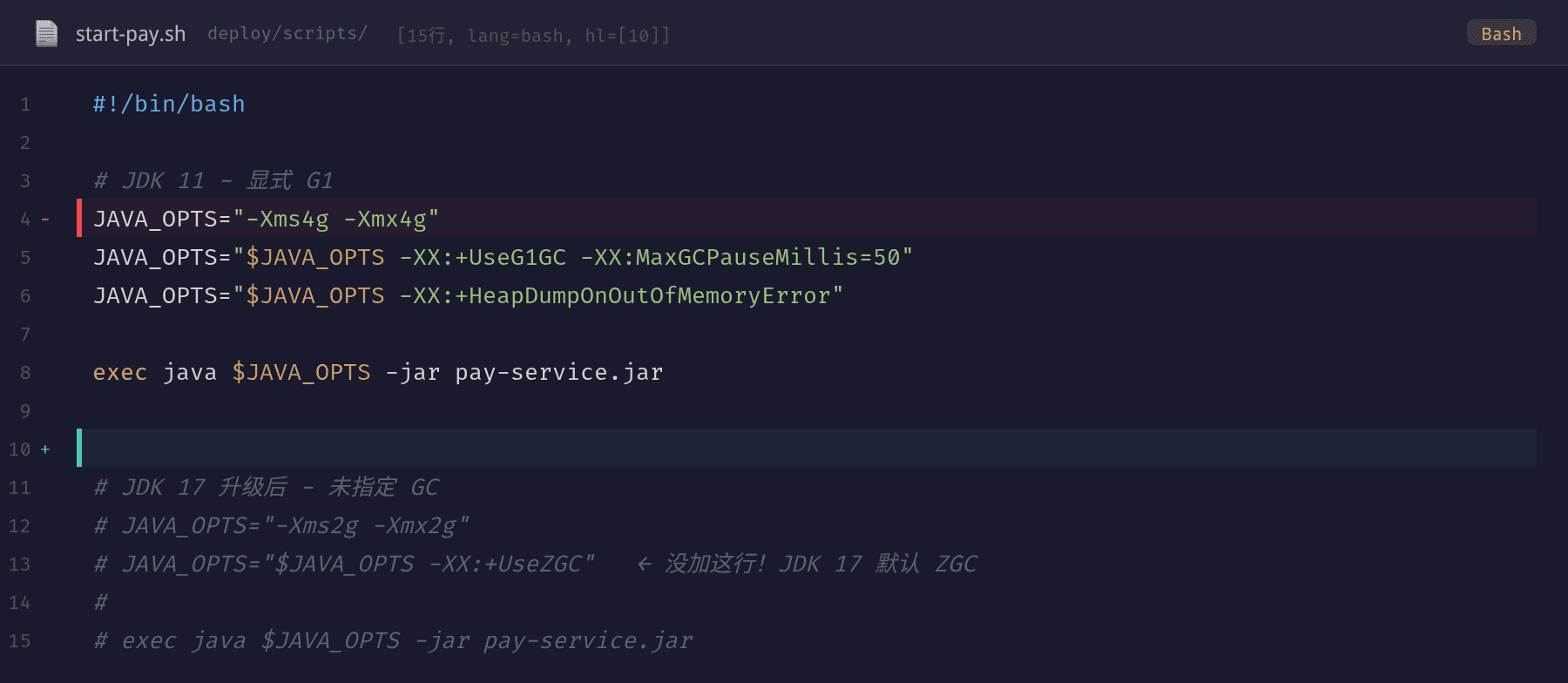
修复后的配置:
JAVA_OPTS="-Xms4g -Xmx4g"
JAVA_OPTS="$JAVA_OPTS -XX:+UseG1GC"
JAVA_OPTS="$JAVA_OPTS -XX:MaxGCPauseMillis=20"
JAVA_OPTS="$JAVA_OPTS -XX:G1HeapRegionSize=4m"
JAVA_OPTS="$JAVA_OPTS -XX:+HeapDumpOnOutOfMemoryError"
三个参数调整的考量:
-XX:+UseG1GC(核心):显式用 G1 替代 ZGC。这是本次修复最关键的改动——不再依赖默认 GC 策略-XX:MaxGCPauseMillis=20(从 50 下调):G1 的停顿预测模型会力争将每次 GC 停顿控制在 20ms 以内。值越小,G1 调用的 Young GC 越频繁但每次停顿越短。对于 50ms P99 要求的服务,20ms 更安全-XX:G1HeapRegionSize=4m(优化 Region 大小):G1 将堆划分为等大的 Region。2G 堆下,4m Region 创建 512 个 Region。Region 太小会增加 Remembered Set 维护开销;太大则精细度不够。4m 在 2-4G 堆区间是平衡点- 堆从 2G 扩到 4G:稍大的堆让 G1 的并发标记周期更从容,减少并发标记失败退化为 Full GC 的概率
验证结果
上线后监控显示:
- 5 分钟内:P99 RT 从 534ms 回落到 80ms
- 15 分钟内:P99 RT 稳定在 42-55ms,恢复到升级前的水平
- 慢请求率:从 10%+ 降至 0.1-0.2%
- GC 频率:Young GC 约 3-5 秒一次,每次停顿 8-15ms,无 Full GC
避坑建议
- JDK 升级清单必须包含 GC 验证:JDK 11→17 的默认 GC 可能从 G1 变为 ZGC。升级前后执行
java -XX:+PrintCommandLineFlags -version确认默认 GC,并在启动脚本中显式指定 GC 参数 - 压测流量必须逼近生产峰值:ZGC 在低分配率下表现完美,但高分配率下可能出现百毫秒级 Allocation Stall。压测场景至少要达到生产峰值的 80%
- 监控 GC 停顿类型:除了常规的 GC 次数和耗时监控,还要关注 ZGC 的 Allocation Stall、G1 的 Full GC 次数、Safepoint 停顿等。这些指标往往在默认的 GC 监控模板中被遗漏
- 不要默认 ZGC 一定比 G1 好:ZGC 的适用场景是大堆(>64G)+ 低分配率。在中小堆(<8G)下,G1 更稳定
- RT 敏感服务重点关注慢请求分布:即使平均 RT 正常,P99/P999 的抖动可能触发上游超时。GC 停顿是 P99 抖动的常见来源,GC 选型直接影响 P99 稳定性
- 显式比默认更安全:所有 JVM 参数尽量显式声明,不要依赖默认值。默认值在不同 JDK 版本之间可能无声变化
附:完整命令清单
# 查看进程和 GC 参数
jps -lvm | grep pay-service
# 查看 GC 状态(连续采样)
jstat -gcutil <pid> 1000 8
# 查看 GC 原因
jstat -gccause <pid> 1000 3
# 查看线程状态
jstack <pid> | grep -E "(biz|GC|ZGC)" | head -20
# GC 日志 - Allocation Stall 分布
grep "Allocation Stall" gc.log | head -12
# Allocation Stall 时长 Top 5
awk '{print $3}' gc.log | grep -oP '\d+\.\d+' | sort -n | tail -5
# Allocation Stall 累计耗时
awk '{match($3, /([0-9]+\.[0-9]+)ms/, a); if(a[1]) sum+=a[1]; count++} \
END {printf "%d 次, 累计 %.2fs, 平均 %.2fms\n", count, sum/1000, sum/count}' gc.log
# 确认 JDK 默认 GC
java -XX:+PrintCommandLineFlags -version | grep Use
# 启动参数对比
# ZGC: java -Xms2g -Xmx2g -XX:+UseZGC -jar app.jar
# G1: java -Xms4g -Xmx4g -XX:+UseG1GC -XX:MaxGCPauseMillis=20 \
# -XX:G1HeapRegionSize=4m -jar app.jar


