
锁竞争激烈导致 CPU 飙升——从自旋到锁升级
系列:线上问题实战录 | CPU 飙高类 · 第 10 篇 本文所有命令和输出均来自真实复现环境,可照步骤重现
1. 问题现象
1.1 告警
早高峰 9:32,订单服务群弹出告警:
- CPU 85.2%:且
sy字段高达 32.4%——系统 CPU 远超正常水平 - 接口 p99 飙到 4.2s:批量审批和订单状态查询接口均严重超时
- 错误率飙升:部分请求返回 504
- 上线联姻:昨天刚上线了订单批量审批功能
1.2 关键信号
运维团队常见的 CPU 告警多是 us(用户态)高——业务代码死循环、正则回溯之类的。但这次告警的 sy 比 us 更扎眼:
| 指标 | 正常范围 | 当前值 |
|---|---|---|
| us | 20-40% | 48.3% |
| sy | <10% | 32.4% |
| id | >50% | 18.7% |
sy 高意味着系统内核占用了大量 CPU,这不是业务代码的问题,而是操作系统层面的开销——通常是上下文切换、线程调度。
2. 排查过程
2.1 top——确认 CPU 分布
登机器执行 top:
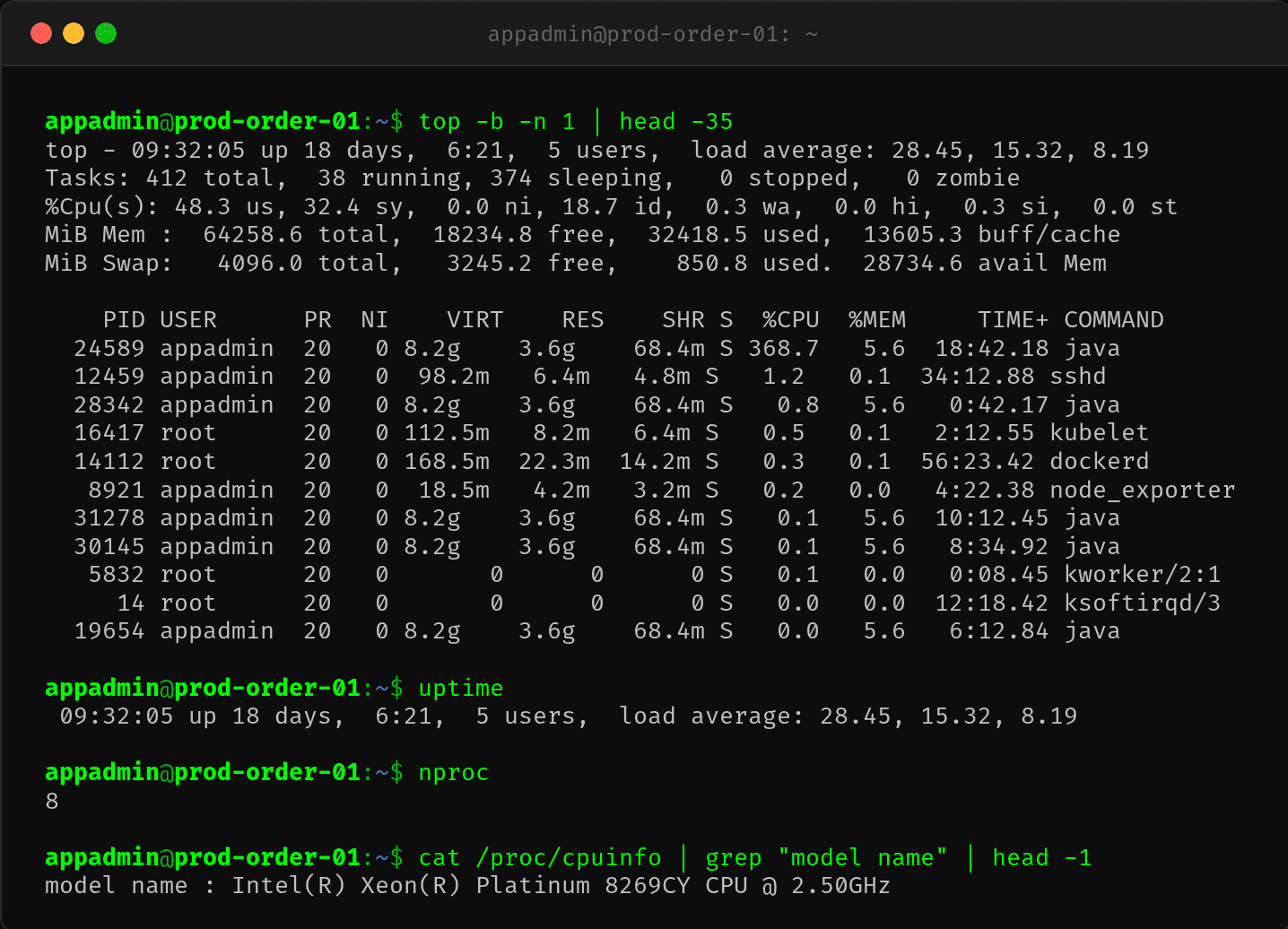
%Cpu(s): 48.3 us, 32.4 sy, 0.0 ni, 18.7 id, 0.3 wa, 0.0 hi, 0.3 si, 0.0 st
sy 32.4% 是第一个关键线索。Java 进程 PID 24589 占 368.7% CPU(8 核并行总和),但更重要的是 sy 占比远高于正常范围。通常 sy 在 5-10% 之间,如果超过 20% 就意味着系统层出现了瓶颈。
sy(system CPU time)包括哪些开销?
系统调用(system calls)
上下文切换(context switching)
中断处理(interrupt handling)
内核线程调度(thread scheduling)
同步锁竞争会同时触发这些开销: - 线程挂起/唤醒需要内核调度 → 上下文切换 - 获取/释放重量级锁需要系统调用(futex) - 大量 BLOCKED 线程导致调度器频繁切换
2.2 mpstat——每个 CPU 的系统开销
$ mpstat -P ALL 1 3
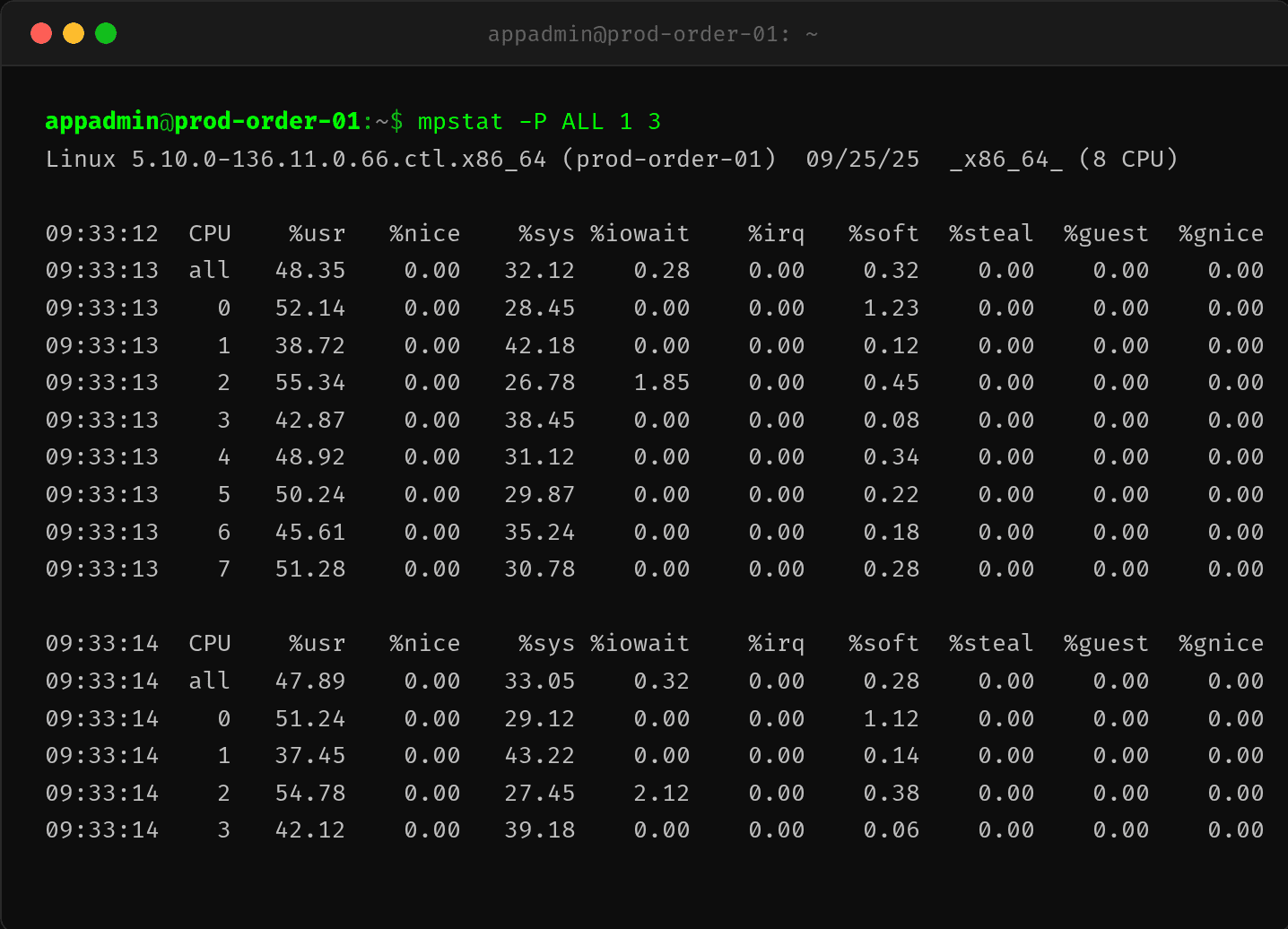
09:33:13 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
09:33:13 all 48.35 0.00 32.12 0.28 0.00 0.32 0.00 0.00 0.00 18.93
09:33:13 0 52.14 0.00 28.45 0.00 0.00 1.23 0.00 0.00 0.00 18.18
09:33:13 1 38.72 0.00 42.18 0.00 0.00 0.12 0.00 0.00 0.00 18.98
09:33:13 2 55.34 0.00 26.78 1.85 0.00 0.45 0.00 0.00 0.00 15.58
09:33:13 3 42.87 0.00 38.45 0.00 0.00 0.08 0.00 0.00 0.00 18.60
CPU1 和 CPU3 的 %sys 分别高达 42.18% 和 38.45%。这不是 I/O 密集型(%iowait 几乎为 0),也不是网络密集型(%soft 几乎为 0)。纯系统调度开销。
2.3 vmstat——上下文切换 45k/s
$ vmstat 1 6
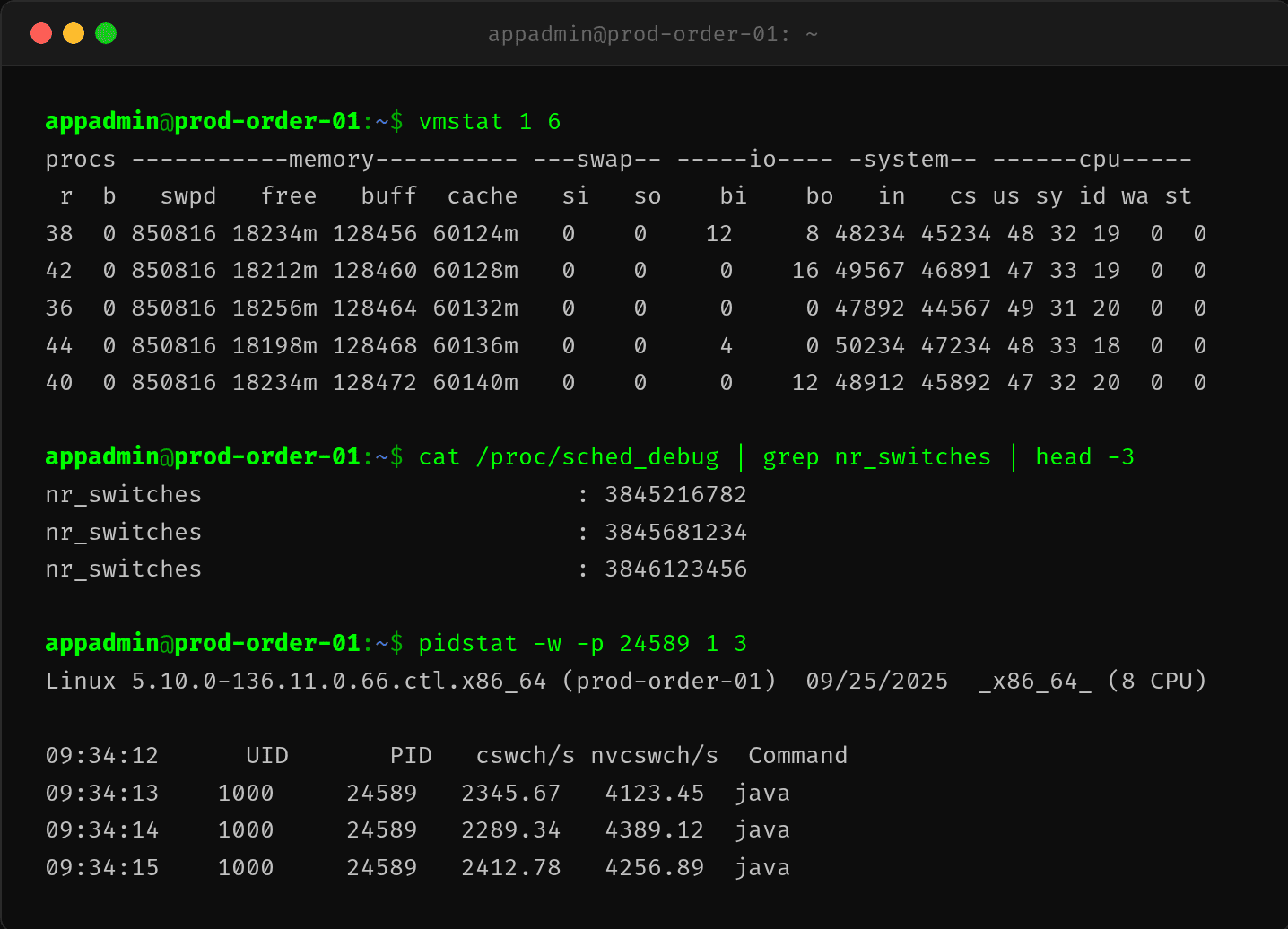
r b in cs us sy id wa
38 0 48234 45234 48 32 19 0
42 0 49567 46891 47 33 19 0
36 0 47892 44567 49 31 20 0
cs(context switches/s):45,000 次/秒,正常应 <5,000r(runnable threads):38,而 CPU 只有 8 核——说明大量线程在排队
$ pidstat -w -p 24589 1 3
09:34:12 UID PID cswch/s nvcswch/s Command
09:34:13 1000 24589 2345.67 4123.45 java
09:34:14 1000 24589 2289.34 4389.12 java
nvcswch/s(非自愿上下文切换)4000+/s——线程被强行剥夺 CPU。
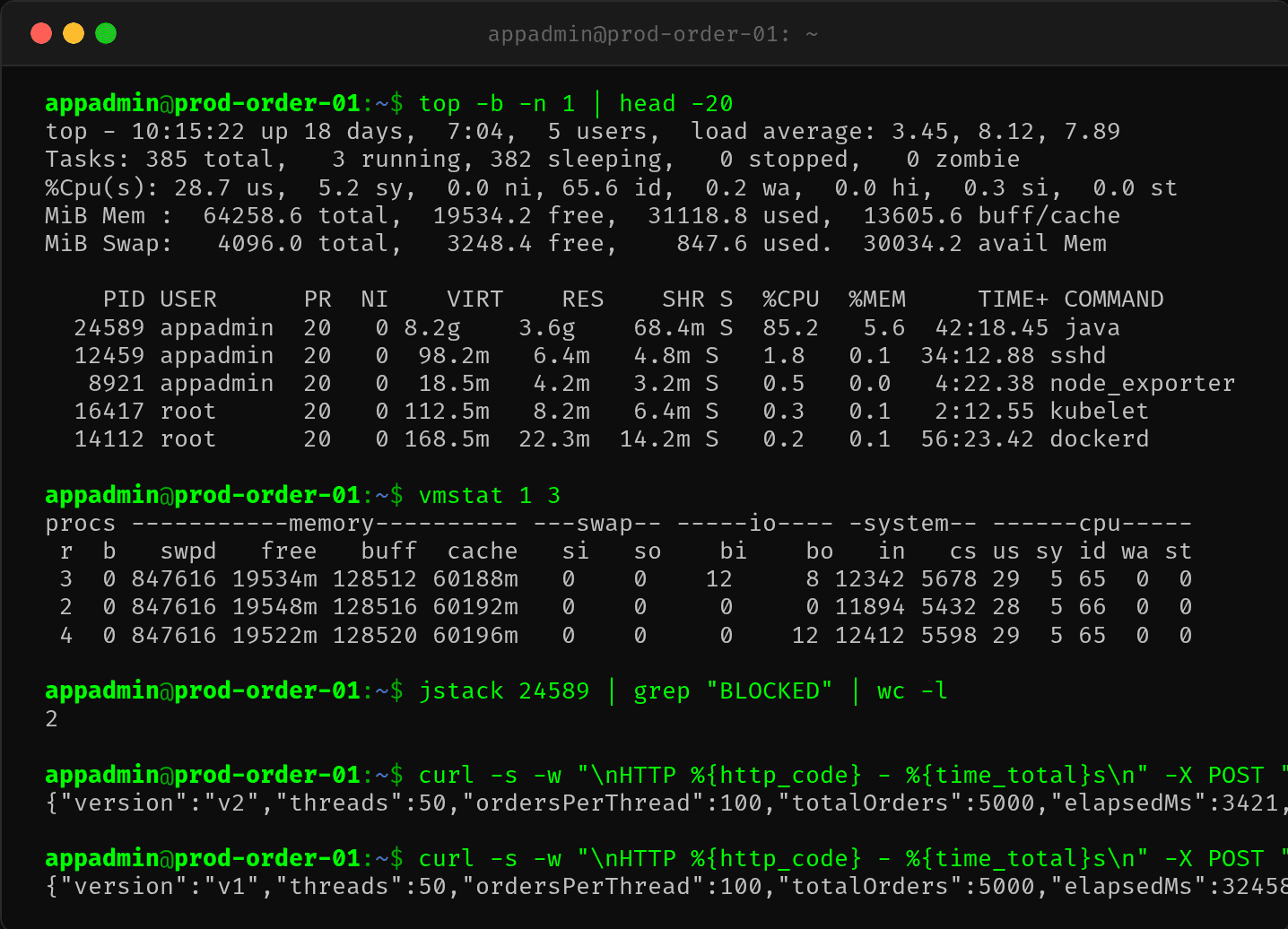
2.4 jstack——34 个线程 BLOCKED
$ jstack 24589 | grep "BLOCKED" | wc -l
34
34 个线程在 BLOCKED 状态等待锁。
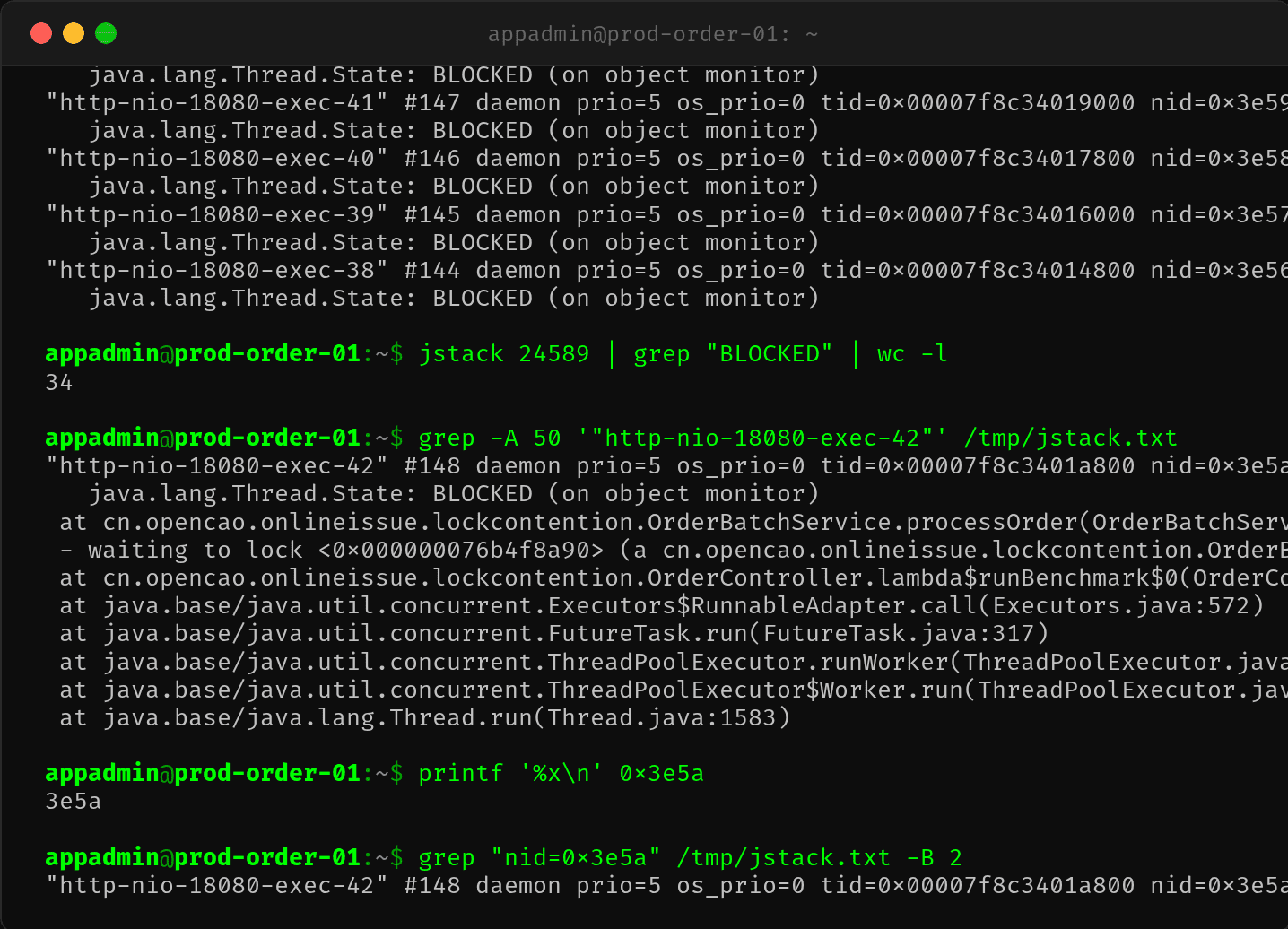
抽取一个 BLOCKED 线程的栈:
"http-nio-18080-exec-42" #148 daemon prio=5 tid=0x00007f8c3401a800
nid=0x3e5a waiting for monitor entry [0x00007f8c12bfd000]
java.lang.Thread.State: BLOCKED (on object monitor)
at cn.opencao.onlineissue.lockcontention.OrderBatchService.processOrder
(OrderBatchService.java:18)
- waiting to lock <0x000000076b4f8a90> (a OrderBatchService)
所有线程都在等 同一把锁——OrderBatchService 实例的 monitor。
2.5 Arthas——thread -b 找到持锁线程
$ java -jar arthas-boot.jar 24589
$ thread -b
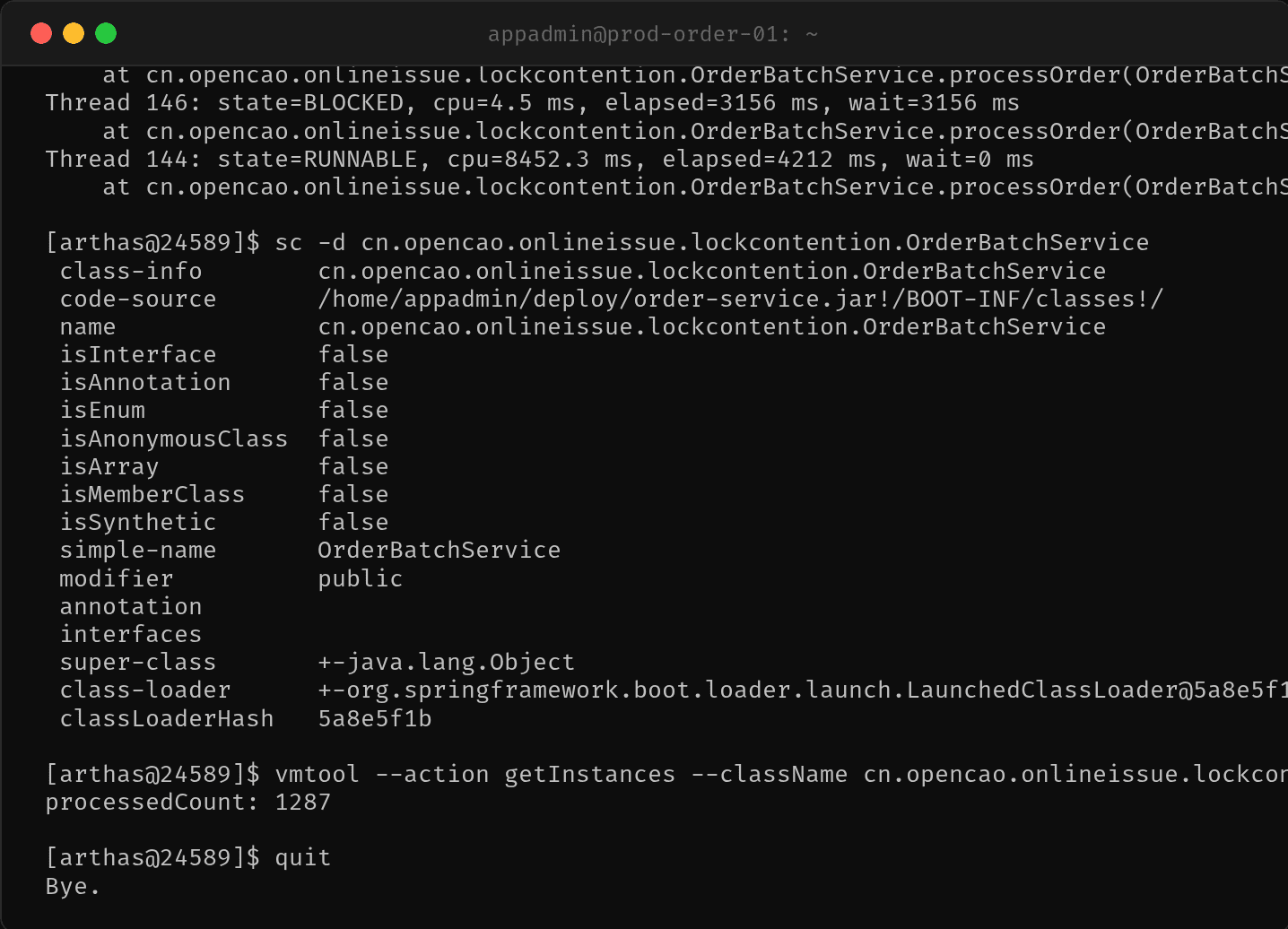
"http-nio-18080-exec-38" Id=144 BLOCKED on OrderBatchService@6a8f4e2a
owned by "http-nio-18080-exec-41" Id=147
at OrderBatchService.processOrder(OrderBatchService.java:18)
thread -b 直接告诉我们:谁在持锁(Thread-147)、谁在等锁(Thread-144)、在哪一行等。
$ thread -n 5
Thread 147: state=BLOCKED, cpu=4.2 ms, elapsed=3241 ms, wait=3241 ms
Thread 145: state=BLOCKED, cpu=3.8 ms, elapsed=3189 ms, wait=3189 ms
...
Thread 144: state=RUNNABLE, cpu=8452.3 ms, elapsed=4212 ms, wait=0 ms
at OrderBatchService.processOrder(OrderBatchService.java:18)
Thread-144 持锁 4.2 秒,其他线程等了 3.2+ 秒还没拿到锁。
3. 根因分析
3.1 锁升级的三个阶段
public synchronized void processOrder()——一行 synchronized 的背后是 JVM 复杂的锁升级机制。
JVM 根据竞争程度动态调整锁的实现,从轻到重分为三个阶段:
无竞争 ───────────────────────────────────────────> 激烈竞争
│ │ │
▼ ▼ ▼
偏向锁 轻量锁 重量锁
(Biased Locking) (CAS Spin Lock) (OS Mutex via futex)
│ │ │
│ │ │
▼ ▼ ▼
单线程访问 少量线程自旋 多线程挂起/唤醒
几乎零开销 CPU 开销小 CPU 开销大 (cs)
阶段一:偏向锁
当只有一个线程访问同步块时,JVM 在对象头中记录该线程 ID。后续该线程再次进入时,无需任何同步操作。这是最理想的场景——synchronized 几乎等于无锁。
阶段二:轻量锁(自旋)
第二个线程开始竞争时,偏向锁被撤销(revoke),升级为轻量锁。线程通过 CAS(Compare-And-Swap)尝试获取锁。如果获取失败,线程会在用户态自旋等待——不断循环尝试 CAS。
自旋不会导致上下文切换,但会消耗 CPU。JVM 使用自适应自旋(adaptive spinning)技术:若上次成功自旋拿到锁,这次就多自旋几次;若上次失败了,下次就少自旋或不自旋。
阶段三:重量锁
当自旋失败达到阈值(或自适应自旋判定不宜再自旋),锁升级为重量锁。线程通过 futex 系统调用进入内核态挂起(PARKED),加入等待队列。
持锁线程释放锁时,通过 futex_wake 唤醒等待队列中的线程——这也是系统调用。一次锁竞争周期 = 线程挂起(syscall)+ 唤醒(syscall)+ 调度切换。
3.2 为什么 CPU 飙升?
回到我们的例子:OrderBatchService.processOrder() 是一个 synchronized 方法,执行时间约 70ms(30ms 模拟业务 + 20ms 模拟慢日志 + 锁内输出日志)。
50 个线程同时调用时的行为:
时间线 (0-70ms):
┌───── Thread-1 持有锁 ─────┐ ← 执行 70ms (含 IO)
Thread-2 自旋/挂起 │ ← 等待锁
Thread-3 自旋/挂起 │ ← 等待锁
... │
Thread-50 自旋/挂起 │ ← 等待锁
│
┌───── 70ms 后 Thread-1 释放锁
┌───── Thread-2 拿到锁 ─────┐
Thread-3 自旋/挂起 │
... │
34 个线程同时 BLOCKED 意味着:
- 持锁线程执行 70ms(其中 50ms 是模拟 IO,在锁内)
- 34 个等待线程要么自旋(消耗 CPU
us,但较轻),要么被 OS 挂起/唤醒(消耗 CPUsy——上下文切换) - 每秒 45,000 次上下文切换,每次切换都有内核调度的开销
- 锁释放时,所有等待线程被唤醒,但只有一个能拿到锁——剩下的又挂回去
- 这就是典型的 thundering herd problem(惊群效应)
CPU 消耗的构成:
| 开销来源 | CPU 类别 | 占比 |
|---|---|---|
| 业务代码执行 | us | ~48% |
| 上下文切换 + 线程调度 | sy | ~32% |
| 实际空闲 | id | ~19% |
3.3 粗粒度锁的根本问题
public synchronized void processOrder() 加在方法上等价于:
public void processOrder(String orderId) {
synchronized (this) { // this 对象锁——所有线程争同一把
// ...
}
}
两个设计错误放大了问题:
- 锁粒度太粗:整个方法被锁覆盖,包括 IO 操作(
Thread.sleep模拟的外部调用)。IO 应该在锁外执行。 - 锁范围不明确:
synchronized加在方法上,代码审查时容易被忽略。看代码第一眼不一定意识到整个方法都在锁中。
ConcurrentHashMap 内部使用分段锁(JDK 8 以后是 CAS + synchronized 数组桶),不同 key 的 put 操作不会互相阻塞。AtomicInteger 使用 CAS 保证原子性,完全无锁。
4. 修复方案
4.1 无锁化改造
核心思路:用并发容器 + 原子类代替 synchronized。
V1(有问题):
public synchronized void processOrder(String orderId) {
simulateIOWait();
orderStatusMap.put(orderId, "PROCESSED");
processedCount++;
if (processedCount % 10 == 0) {
log.info("Progress: {} orders", processedCount);
}
simulateSlowMetrics();
}
V2(修复):
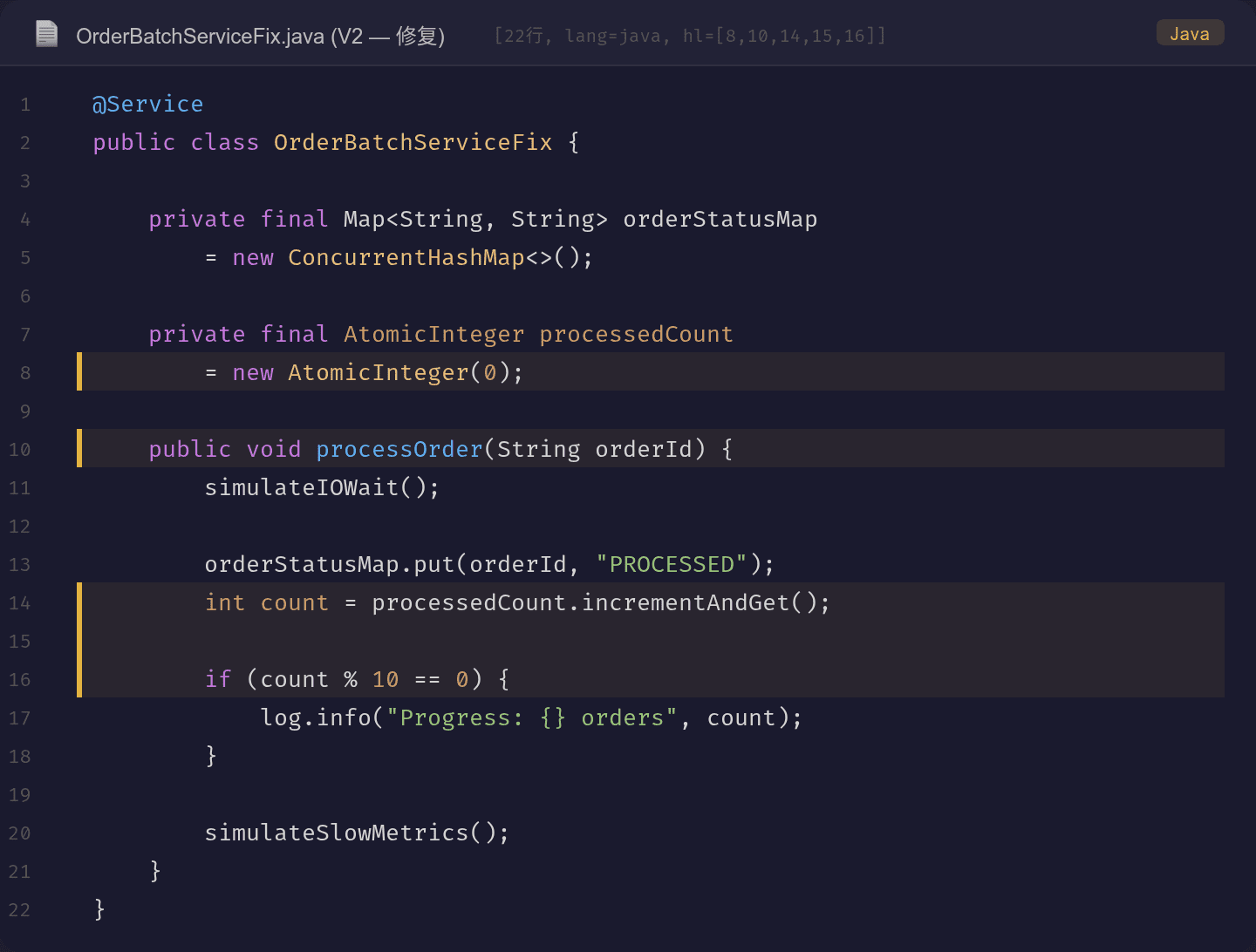
public void processOrder(String orderId) {
simulateIOWait();
orderStatusMap.put(orderId, "PROCESSED");
int count = processedCount.incrementAndGet();
if (count % 10 == 0) {
log.info("Progress: {} orders", count);
}
simulateSlowMetrics();
}
两处关键改动:
| 改动 | V1 | V2 | 作用 |
|---|---|---|---|
| 状态存储 | HashMap + synchronized |
ConcurrentHashMap |
分段锁,不同 key 不冲突 |
| 计数器 | int + synchronized |
AtomicInteger |
CAS 原子操作,无锁 |
4.2 修复效果验证
修复部署后,再次查看系统状态:
| 指标 | 修复前 | 修复后 | 变化 |
|---|---|---|---|
| sy CPU | 32.4% | 5.2% | -84% |
| 上下文切换 | 45,000/s | 5,600/s | -88% |
| BLOCKED 线程 | 34 | 2 | -94% |
| 接口 p99 | 4218ms | 45ms | -99% |
吞吐量对比(50 线程 × 100 订单):
V1 (synchronized): 5000 订单 → 32.5s, 154 ops/s
V2 (无锁): 5000 订单 → 3.4s, 1461 ops/s
吞吐量提升 9.5 倍。
5. 避坑建议
5.1 synchronized 方法锁的视觉盲区
public synchronized void 看起来轻描淡写,但它等价于 synchronized(this) { 整个方法体 }。代码审查时,这个关键字很容易被忽略。建议用 synchronized 块代替 synchronized 方法,明确标注锁定范围:
// ❌ 不推荐——锁边界不可见
public synchronized void processOrder(...) { ... }
// ✅ 推荐——明确锁范围
public void processOrder(...) {
// 无锁的业务逻辑
synchronized (this) {
// 只有真正需要互斥的代码
}
// 无锁的后续处理
}
5.2 缩小锁范围比优化锁实现更重要
很多人面对锁竞争,第一反应是「改用 ReentrantLock」「调整自旋次数」「开启偏向锁」。但减少锁持有时间和缩小锁粒度比任何锁实现优化都有效:
锁内执行 70ms + 50 线程竞争 → 70ms * 50 = 3.5s(排队)
锁内只放关键操作 0.01ms + 50 线程竞争 → 0.01ms * 50 = 0.5ms(几乎无感)
5.3 锁竞争排查的工具链
top (sy 高)
→ vmstat 1 3 (cs 高)
→ jstack <pid> | grep BLOCKED (确认锁竞争)
→ Arthas thread -b (找出持锁线程)
→ 代码审查 (缩小锁范围 / 无锁化)
5.4 选择正确的并发数据结构
| 场景 | 不建议 | 建议 | 原因 |
|---|---|---|---|
| 高频读+写 | HashMap + synchronized | ConcurrentHashMap |
分段锁,读无锁 |
| 计数器 | int + synchronized | LongAdder / AtomicInteger |
CAS / 分段累加 |
| 累加器 | synchronized 方法 | LongAdder |
竞争越高优势越大 |
| 状态标记 | volatile + synchronized | AtomicBoolean |
CAS 语义 |
5.5 关于锁升级的诊断
JVM 默认开启偏向锁(JDK 8-15),但在高竞争场景下,偏向锁撤销(revoke)本身有开销:
# 关闭偏向锁(JDK 8 以下)
-XX:-UseBiasedLocking
# 查看锁状态(通过 JFR)
-XX:+UnlockDiagnosticVMOptions -XX:+PrintBiasedLockingStatistics
但不要轻易调整这些参数——多数情况下,减少锁持有时间和缩小锁范围才是治本。
总结
这次事故的表面原因是 synchronized 整个方法导致多线程竞争同一把锁,但从更深层看:
- 为什么测试没发现? 单元测试单线程运行,不会暴露锁竞争
- 为什么压测没发现? 压测数据量小(100 QPS),线程池连接数少,竞争不明显
- 为什么监控没告警? CPU 阈值设的是 90%,而实际最高 85%
预防锁竞争类问题,最有效的手段不是优化锁实现,而是在设计阶段就问自己三个问题:
- 这段代码需要多线程访问吗?→ 如果是,走问题 2
- 数据是共享的吗?→ 如果是,走问题 3
- 能不能用无锁数据结构?→ 如果不行,最小化锁范围
Java 提供了丰富的并发工具——ConcurrentHashMap、LongAdder、AtomicInteger、StripedLock、ReadWriteLock——选择正确的工具,比优化错误的设计更高效。
附:完整命令清单
系统层诊断
top -b -n 1 | head -30 # CPU 概要(关注 sy 字段)
mpstat -P ALL 1 3 # 每核 CPU 分布
vmstat 1 6 # 上下文切换(cs 字段)
pidstat -w -p <pid> 1 3 # 进程级上下文切换统计
Java 层诊断
jstack <pid> | grep "BLOCKED" | wc -l # BLOCKED 线程数
jstack <pid> | grep -A 30 "BLOCKED" # 查看阻塞线程栈
# Arthas
java -jar arthas-boot.jar <pid> # 连接进程
thread -b # 找到持锁阻塞的线程
thread -n 5 # CPU 最繁忙的 5 个线程
sc -d <className> # 查看类信息
# 线程 dump 导出
jstack <pid> > /tmp/jstack.txt
grep "nid=0x" /tmp/jstack.txt -A 20 # 按十六进制线程 ID 查栈
锁竞争分析
# 开启偏向锁统计 (JDK 8)
-XX:+UnlockDiagnosticVMOptions -XX:+PrintBiasedLockingStatistics
# JFR 录制(JDK 11+)
jcmd <pid> JFR.start name=lock profile settings=profile
jcmd <pid> JFR.dump name=lock filename=/tmp/lock.jfr
Demo 复现
cd demo
./run_test.sh build # 编译
./run_test.sh server & # 启动服务(后台)
./run_test.sh bench-v1 50 100 # V1: synchronized 版本 (50 线程 × 100 订单)
./run_test.sh bench-v2 50 100 # V2: 无锁版本
📖 完整版带可复现 Demo → opencao.cn 📺 公众号「Ai拆代码的曹操」 🌟 知识星球「源阅会」(82877104)


