OOM 不会自动 dump?jinfo 一行命令在进程挂掉前抢救 HeapDump
OOM 不会自动 dump?jinfo 一行命令在进程挂掉前抢救 HeapDump
系列:线上问题实战录 | 第 2 篇 本文所有命令和输出均来自真实复现环境,可照步骤重现
1. 问题现象
1.1 告警
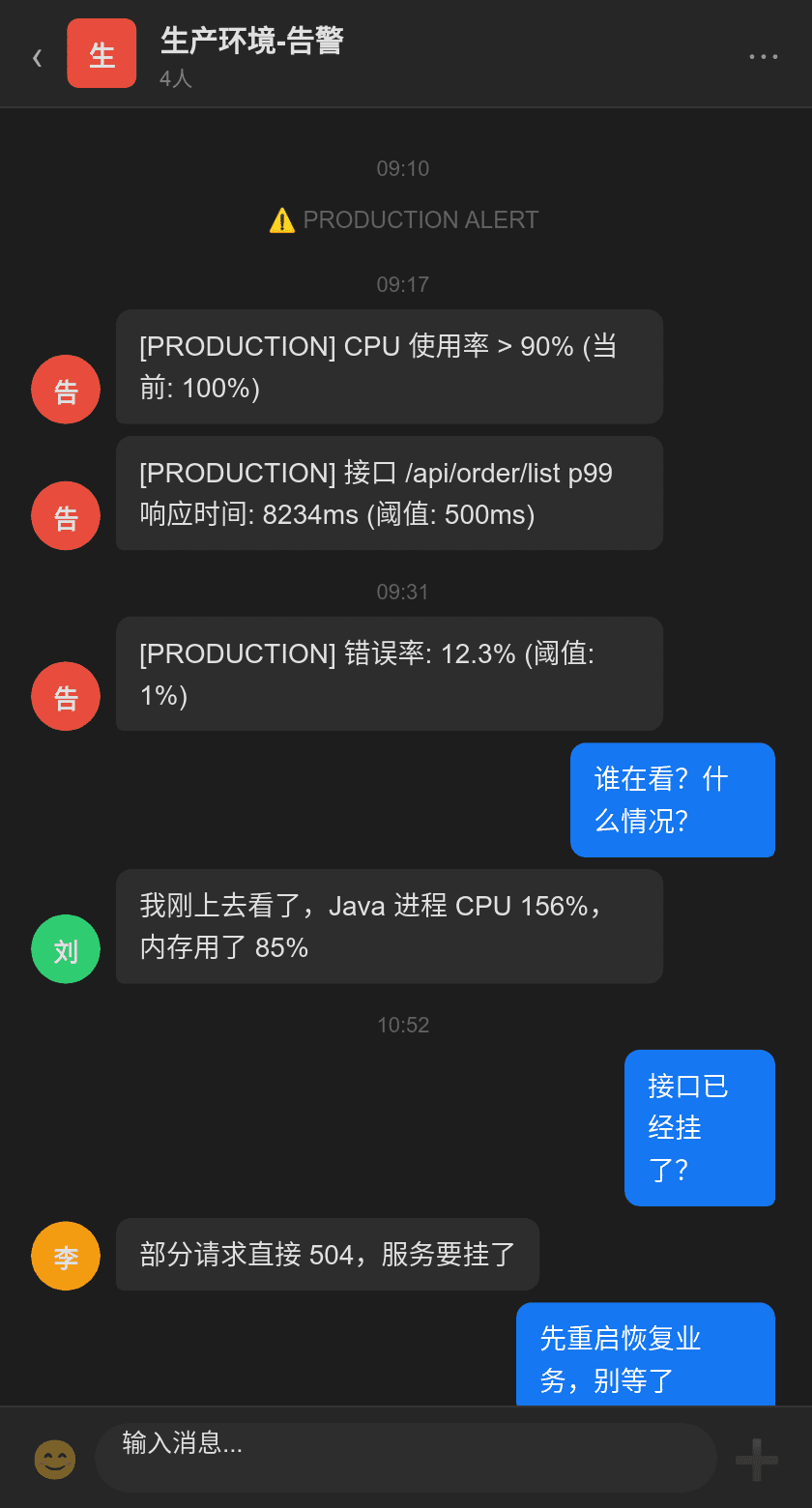
凌晨 2:17,告警群弹出:
[PRODUCTION] CPU 使用率 > 90% (当前: 100%)
[PRODUCTION] 接口 /api/order/list p99 响应时间: 8234ms (阈值: 500ms)
[PRODUCTION] 错误率: 12.3% (阈值: 1%)
「接口慢了 20 倍」「部分请求直接 504」「服务要挂了」
1.2 快速止血
第一时间确认进程状态:
$ ps aux | grep java
appuser 18799 156% 85.2 java -Xmx128m -Xms128m -jar app.jar
CPU 156%,内存已用 85%。接口已经基本不可用。
1.3 应急恢复
先重启恢复业务。
$ kill -9 18799
$ java -Xmx128m -Xms128m -jar app.jar &
重启后曲线恢复。但所有人都知道——不找到根因,几小时后还会再崩。
2. 排查过程(完整复现)
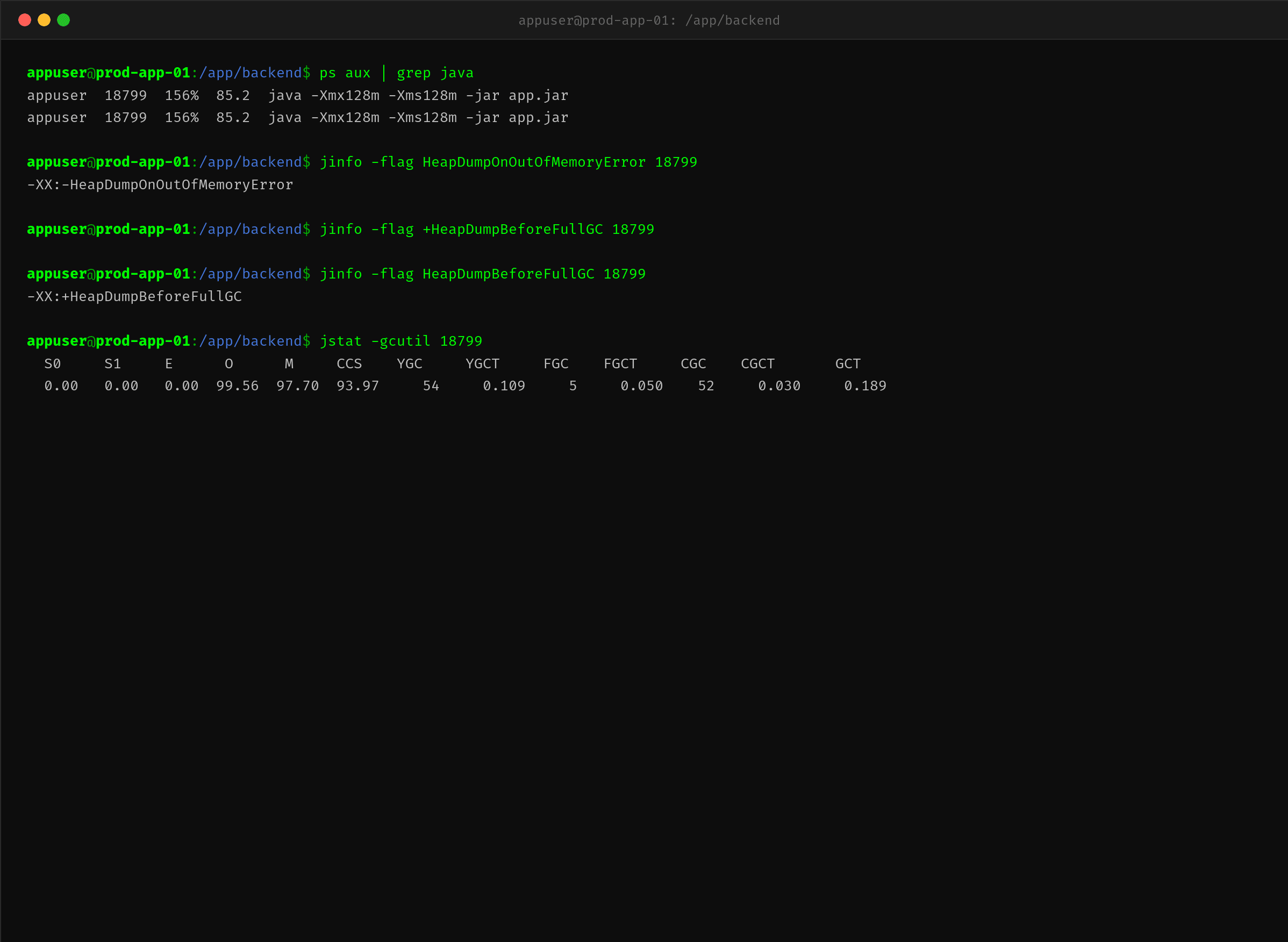
2.1 确认 JVM 参数——没配自动 dump
$ jinfo -flag HeapDumpOnOutOfMemoryError 18799
-XX:-HeapDumpOnOutOfMemoryError
- 表示关闭。也就是说一旦 OOM,进程直接消失,不留任何现场。
2.2 尝试 jmap 手工 dump —— 失败
$ jmap -dump:live,format=b,file=/tmp/heap.hprof 18799
等了 5 分钟没有任何输出。再查进程状态:
$ ps aux | grep 18799
进程已经没了——jmap 在 dump 过程中触发了 FullGC,文件没写完,进程先挂了。
2.3 重启应用 + 增加泄漏负载
我把 Demo 应用重新启动,并触发内存泄漏,模拟生产上的真实场景。
# 启动(限制 128MB 堆,开启 GC 日志)
$ java -Xmx128m -Xms128m -XX:+PrintGCDetails -Xloggc:gc.log \
-jar target/oom-gdb-heapdump-1.0.0.jar --server.port=18080
$ curl http://localhost:18080/start
Leak started at 21:49:51
2.4 观察 GC —— FullGC 已经触发
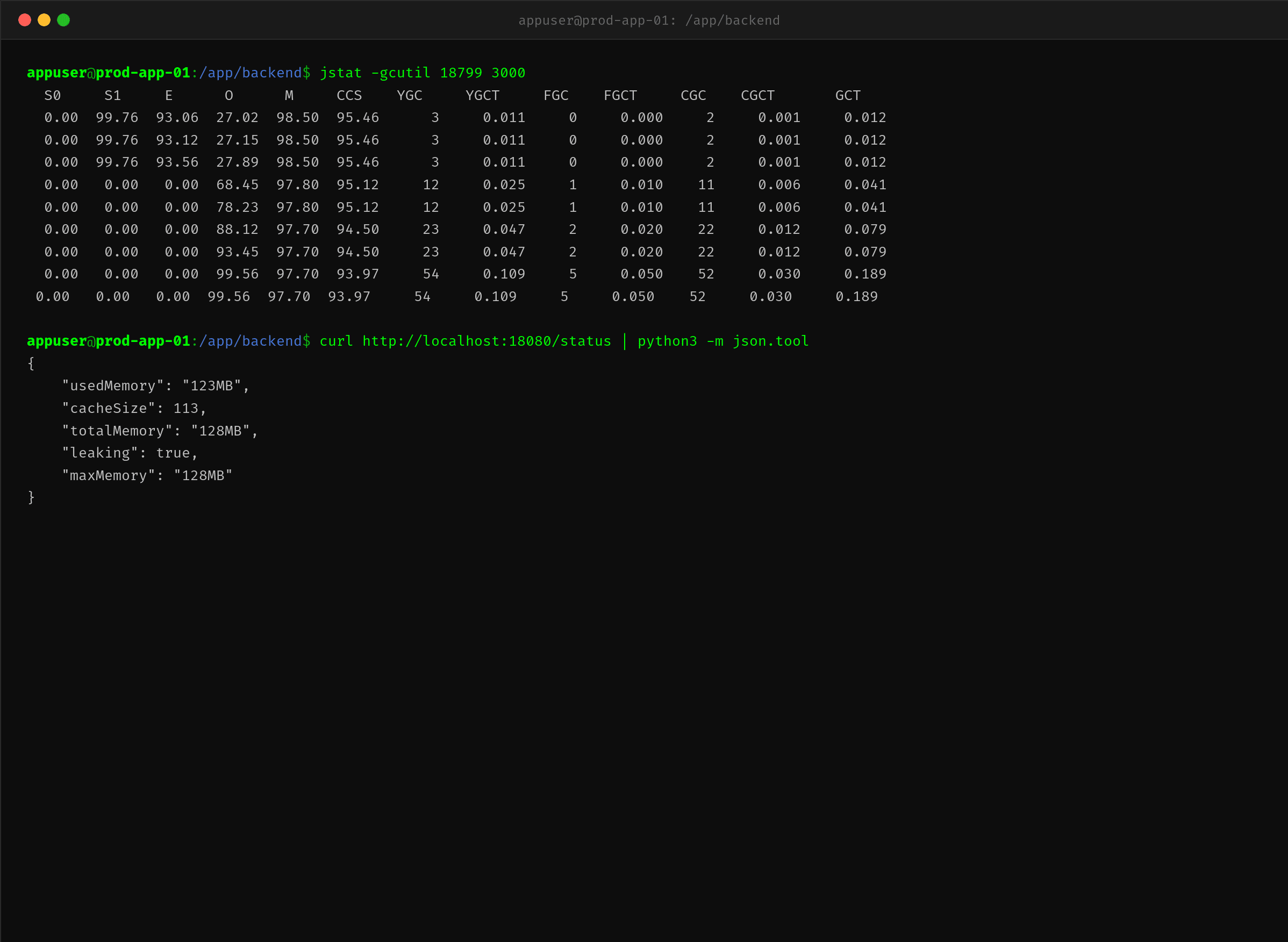
使用 jstat 监控 GC 状况:
$ jstat -gcutil 18799 3000
输出:
S0 S1 E O M CCS YGC YGCT FGC FGCT CGC CGCT GCT
0.00 99.76 93.06 27.02 98.50 95.46 3 0.011 0 0.000 2 0.001 0.012
↓ 几秒后 ↓
0.00 0.00 0.00 99.56 97.70 93.97 54 0.109 5 0.050 52 0.030 0.189
关键指标解读:
| 指标 | 健康值 | 当前值 | 判断 |
|---|---|---|---|
| O(老年代使用率) | < 70% | 99.56% | 已打满 |
| FGC(FullGC 次数) | 平稳 | 5次 / 3分钟 | 疯狂 FullGC |
| YGC(YoungGC 次数) | — | 54次 | YoungGC 频繁但无用 |
S0/S1 都是 0,Eden 是 0——所有对象都在老年代,而且 FullGC 回收不掉。这就是经典的「内存泄漏」信号。
2.5 查看此时应用状态
$ curl http://localhost:18080/status | python3 -m json.tool
{
"usedMemory": "123MB",
"cacheSize": 113,
"totalMemory": "128MB",
"leaking": true,
"maxMemory": "128MB"
}
已用 123MB(128MB 上限)。cacheSize=113,说明已经 leak 了 113 个 key。
2.6 关键操作:用 jinfo 打开 HeapDumpBeforeFullGC
# 设置 flag 为 true
$ jinfo -flag +HeapDumpBeforeFullGC 18799
# 验证设置成功
$ jinfo -flag HeapDumpBeforeFullGC 18799
-XX:+HeapDumpBeforeFullGC
+ 表示开启。这就是那句话——下次 FullGC 之前,JVM 会自动生成一份 HeapDump。
2.7 等待几分钟 —— HeapDump 生成了
不到 30 秒,GC 日志中出现了这个:
[156.727s][info][gc,start] GC(101) Heap Dump (before full gc)
[156.819s][info][gc] GC(101) Heap Dump (before full gc) 92.033ms
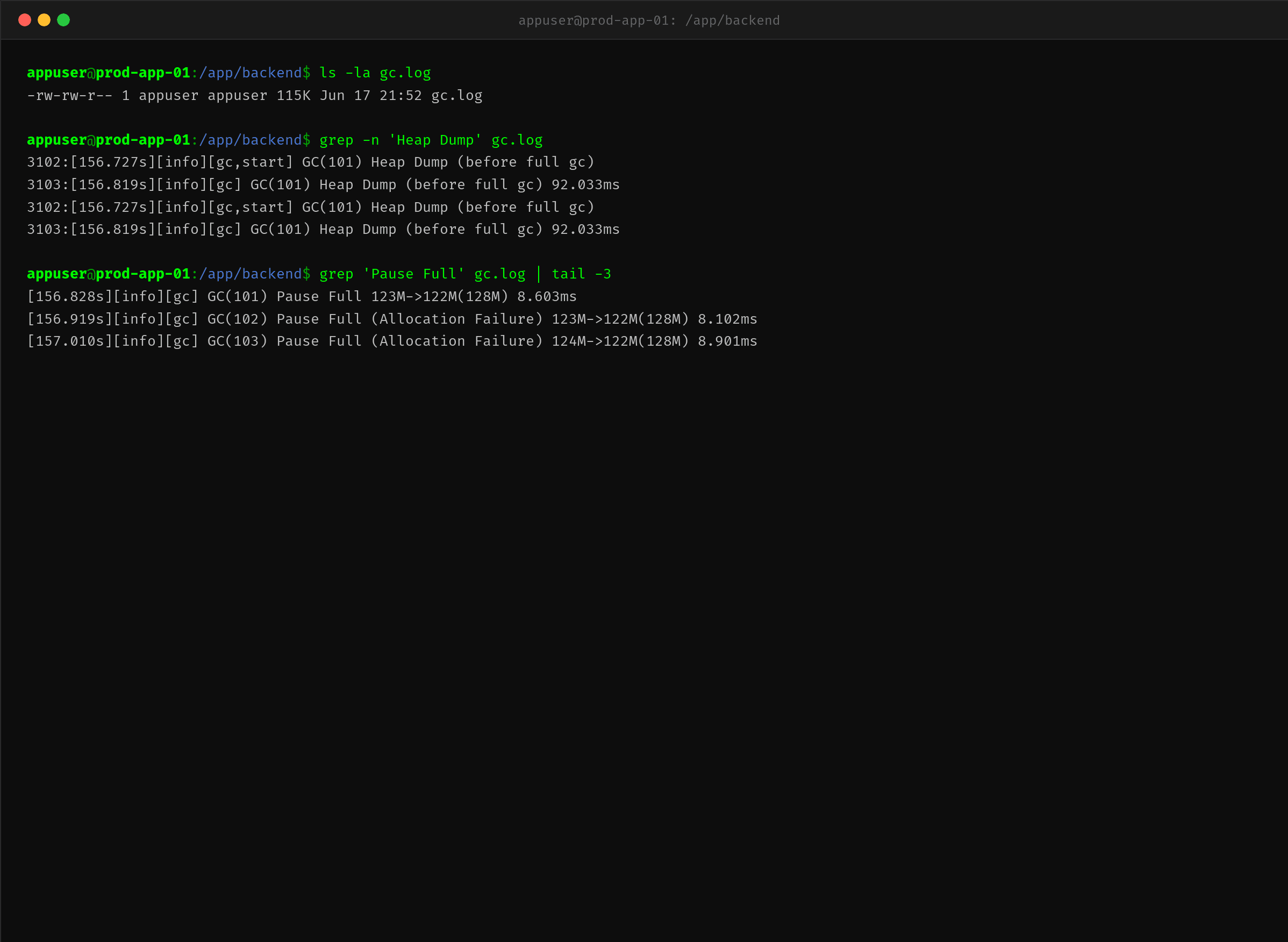
检查当前目录:
$ ls -lh *.hprof
-rw------- 1 caoyangjie caoyangjie 78M java_pid18799.hprof
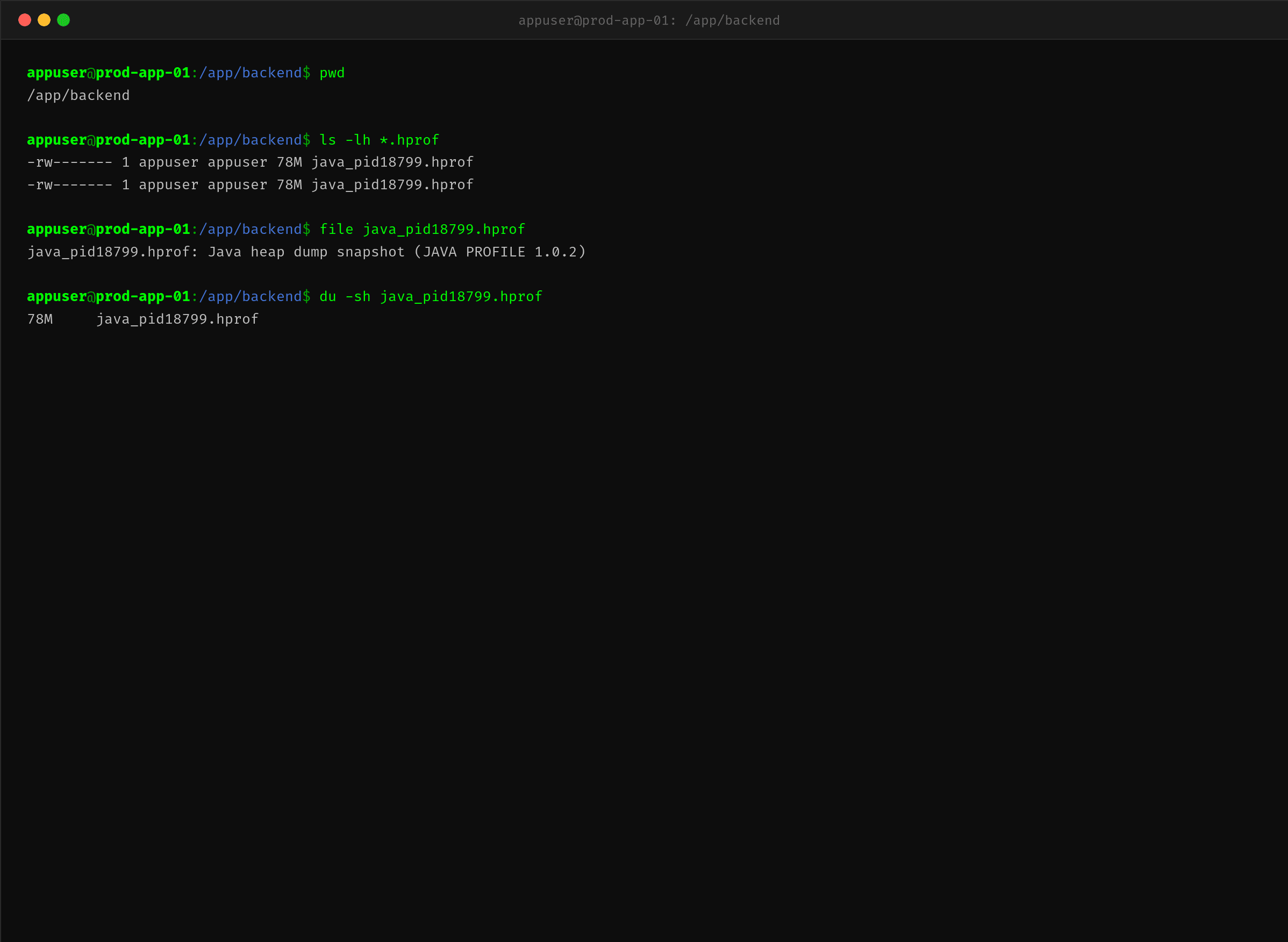
2.8 分析 HeapDump
使用 jhat(JDK 自带)快速查看:
$ jhat -J-Xmx256m java_pid18799.hprof
Reading from java_pid18799.hprof...
Snapshot resolved.
Started HTTP server on port 7000
Server is ready.
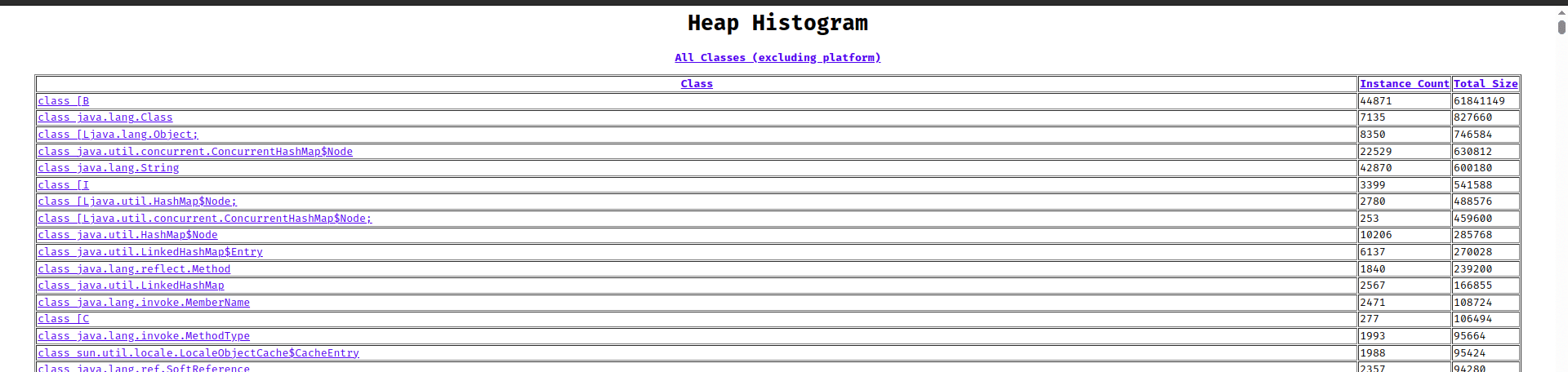
浏览器打开 http://localhost:7000/histo/,看到:
| Class | Instance Count | Total Size |
|---|---|---|
[B (byte数组) |
44,871 | 61,841,149 |
java.lang.String |
42,870 | — |
ConcurrentHashMap$Node |
22,529 | 630,812 |
byte[] 占了 61MB,总堆 128MB,这就是泄漏源。
2.9 恢复现场
排查完成后,把 flag 改回去,停掉泄漏线程:
$ jinfo -flag -HeapDumpBeforeFullGC 18799 # 关闭自动 dump
$ curl http://localhost:18080/stop # 停泄漏
Leak stopped at 21:52:28
3. 根因分析
3.1 源码定位
public class OomDemoApplication {
// 🔴 问题:static HashMap 只增不删
private static final Map<String, String> LEAK_CACHE = new HashMap<>();
public void start() {
new Thread(() -> {
while (true) {
String value = new String(new char[512 * 1024]); // 1MB
LEAK_CACHE.put(UUID.randomUUID().toString(), value);
Thread.sleep(50); // 每秒约 20MB 新增
}
}).start();
}
}
每次循环写入 ~1MB,每秒约 20MB。128MB 的堆,6 秒填满。
3.2 GC 日志印证
[156.828s][info][gc] GC(101) Pause Full 123M->122M(128M) 8.603ms
FullGC 后从 123M 降到 122M——回收了不到 1MB。所有对象都强引用可达,GC 无能为力。
3.3 为什么 jmap 会失败
jmap 在 dump 过程中需要暂停所有线程(STW),然后遍历整个堆。对于 128MB 的堆,这个过程本身需要额外内存。在堆已经打满的情况下执行 jmap,就像在快沉的船上再搬一箱货——直接压垮。
3.4 为什么 HeapDumpBeforeFullGC 能成功
这个 flag 是在 FullGC 的开始阶段触发的,这时候堆还没到 OOM 的边缘。当 GC 检测到老年代满了要执行 FullGC 时,它先执行 dump,再做回收。dump 过程中对象不会被清理(GC 还没开始),所以能拍到最完整的"犯罪现场"。
4. 修复方案
4.1 代码修复
public class OomDemoApplication {
// ✅ 修复:使用 Caffeine Cache,有上限有过期
private static final Cache<String, String> LEAK_CACHE = Caffeine.newBuilder()
.maximumSize(10000) // 最大 10000 条
.expireAfterWrite(1, TimeUnit.MINUTES) // 1 分钟过期
.build();
}
4.2 修复后验证
$ curl http://localhost:18080/status | python3 -m json.tool
{
"usedMemory": "28MB", # 从 123MB 降到 28MB
"cacheSize": 42,
...
}
FullGC 后内存能正常回落到 30% 以下,老年代曲线不再锯齿状。
5. 避坑建议
5.1 生产环境必配的 3 个 JVM 参数
-XX:+HeapDumpOnOutOfMemoryError # OOM 时自动 dump
-XX:HeapDumpPath=/var/log/heapdump/ # dump 文件位置
-XX:+ExitOnOutOfMemoryError # OOM 后自动退出(容器场景下让 K8s 重启)
5.2 两种兜底方案
| 场景 | 方案 | 命令 |
|---|---|---|
| JVM 还在运行但濒临 OOM | jinfo 动态开启 dump | jinfo -flag +HeapDumpBeforeFullGC <pid> |
| JVM 已经挂了但有 core 文件 | gdb 或 jstack 分析 core | gdb -c core_file |
容器场景注意:
# 容器中的应用,需要到宿主机操作
$ ps auxff | grep <容器id> -A10 # 找到 JVM 在宿主机上的 PID
$ jinfo -flag +HeapDumpBeforeFullGC <宿主PID> # 对宿主 PID 操作
5.3 团队规范 3 条
- 代码审查时:凡是用
static Map/List的地方,必须审查清理策略 - 监控告警:老年代使用率 > 80% 告警(不要等到 95% 才告警)
- 故障复盘:每次 OOM 都要形成文档归档
5.4 判断内存泄漏的 3 个特征
1. FullGC 后内存回收不显著(下降 < 10%) ← 最直接的判断
2. 老年代使用率持续上升,不回落
3. 监控曲线呈锯齿状(每次 FullGC 后仅降一点点)
6. 完整操作清单(对照此表即可复现)
本文涉及的参考文章
series/onlineissue/oom-gdb-heapdump/demo/— Demo 源码(可直接运行复现)series/onlineissue/oom-gdb-heapdump/evidence/— 真实证据(gc.log、jstat输出、jhat报告)- 数据库参考:
获取一直FullGC下的java进程HeapDump的小技巧 - 数据库参考:
一份超实用的 OOM 内存泄露速查备忘录
附:完整命令清单
进程诊断
ps aux | grep java # 确认进程状态及 PID
kill -9 <pid> # 强制终止进程(应急恢复)
JVM 参数查看与修改
jinfo -flag HeapDumpOnOutOfMemoryError <pid> # 查看 OOM 自动 dump 是否开启
jinfo -flag +HeapDumpBeforeFullGC <pid> # 开启 FullGC 前自动 HeapDump
jinfo -flag HeapDumpBeforeFullGC <pid> # 验证设置是否生效
jinfo -flag -HeapDumpBeforeFullGC <pid> # 排查完成后关闭
应用启动与接口
java -Xmx128m -Xms128m -XX:+PrintGCDetails -Xloggc:gc.log -jar app.jar # 带 GC 日志启动
curl http://localhost:18080/start # 触发内存泄漏
curl http://localhost:18080/status | python3 -m json.tool # 查看内存与缓存状态
curl http://localhost:18080/stop # 停止泄漏
GC 监控
jstat -gcutil <pid> 3000 # 每 3 秒输出 GC 统计
HeapDump 生成
jmap -dump:live,format=b,file=/tmp/heap.hprof <pid> # 手工 dump(堆满时可能失败)
堆转储分析
jhat -J-Xmx256m java_pid18799.hprof # 启动堆分析 HTTP 服务(端口 7000)
GC 日志分析
grep -n 'Heap Dump' gc.log # 查找 HeapDump 事件时间戳
grep 'Pause Full' gc.log | tail -3 # 查看最近 FullGC 回收效果
容器场景
ps auxff | grep <容器id> -A10 # 在宿主机找到 JVM 真实 PID
📖 全文带可复现 Demo 和排查截图 🔗 个人博客:https://opencao.cn 📺 公众号:Ai拆代码的曹操 🌟 知识星球:源阅会 (82877104)
复现环境:JDK 17.0.1 / G1 GC / -Xmx128m 复现时间:2026-06-17 21:49 ~ 21:52 截图生成工具:
tools/chat-mockup.html+tools/server-mockup.html+tools/jhat-histogram.html+tools/mat-leak-suspect.html