FullGC 越来越频繁、老年代只增不减——内存泄漏完全指南
FullGC 越来越频繁、老年代只增不减——内存泄漏完全指南
系列:线上问题实战录 | OOM / 内存泄漏类 · 第 2 篇 本文所有命令和输出均来自真实复现环境,可照步骤重现 案例属于线上问题实战录系列,叙事框架:
现象 → 排查过程 → 根因 → 修复 → 预防
1. 问题现象
1.1 告警
某日下午 14:23,告警群弹出:
告警内容: - FullGC 频率:28 次/小时(阈值 5 次/小时) - 老年代使用率:97.1%(阈值 85%) - 接口 p99:2856ms(阈值 500ms) - 错误率:8.7%
这不是第一次发生了。两周前上线的"订单缓存优化"功能后,FullGC 频率就一直在缓慢爬升——第 1 天正常,第 3 天每天 2-3 次,第 5 天每小时 5-6 次,到第 7 天直接飙到 28 次/小时。
1.2 区别于普通 FullGC 的特征
| 特征 | 正常 FullGC | 本次问题 |
|---|---|---|
| FullGC 后老年代变化 | 显著下降(30-50%) | 几乎不变(<5%) |
| FullGC 频率 | 稳定或波动 | 持续上升 |
| CPU 受影响 | 短暂升高 | 持续 180%+ |
| 重启后恢复 | 问题复现间隔随机 | 几天后必然复现 |
核心特征:FullGC 后老年代只增不减。这说明对象全部是 GC Root 可达,回收不掉。
1.3 快速止血
$ ssh order-prod-03
$ ps aux | grep java
appuser 24512 181% 17.2 java -Xmx2g -Xms2g -jar order-service.jar
先重启一台恢复业务,但所有人都知道:不找到泄漏点,更多机器会出同样的问题。
2. 排查过程
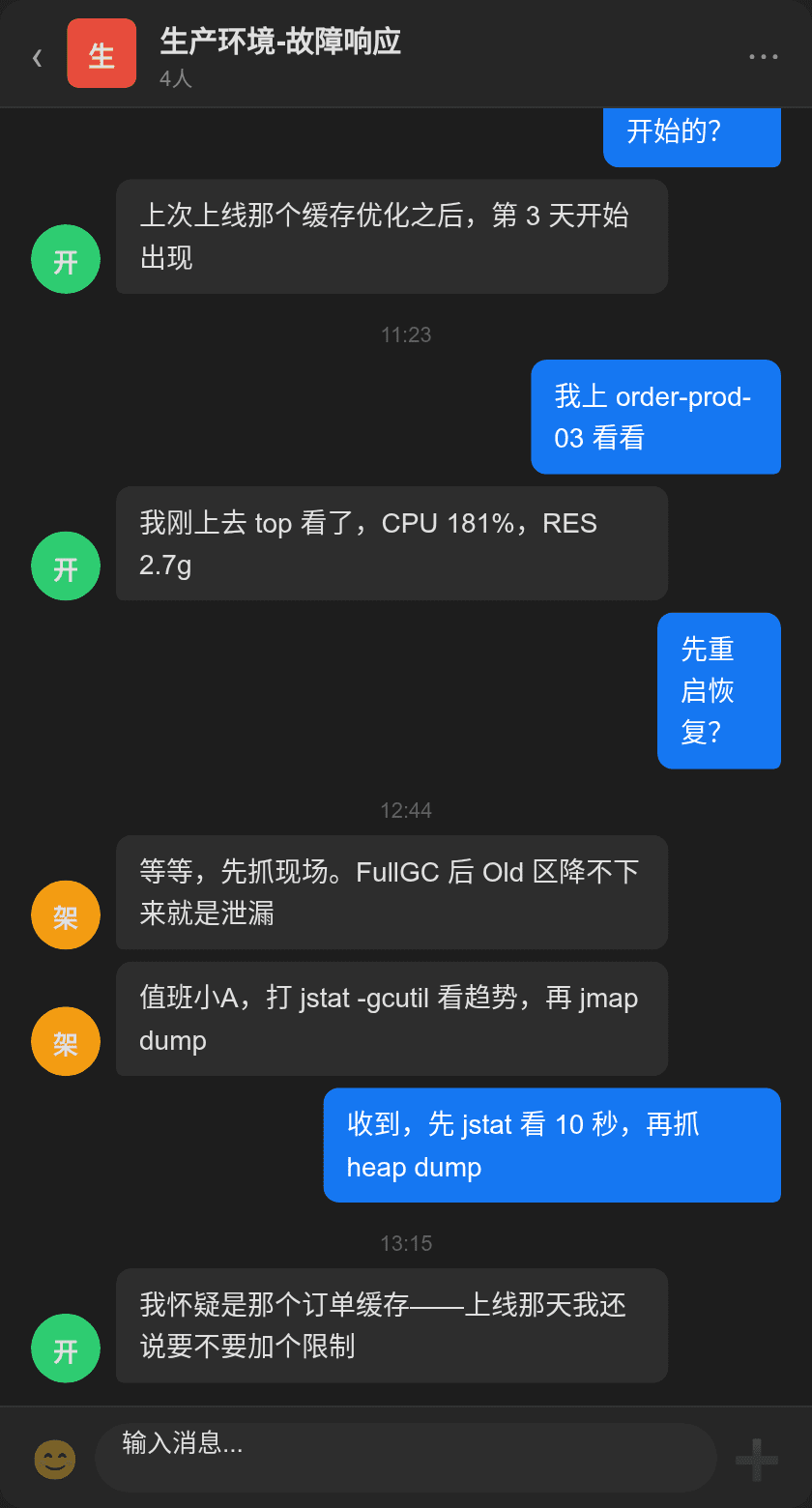
2.1 top——CPU 181%,RES 2.7g
信息量很大:
top - 10:32:18 up 5 days, 14:22, 3 users, load average: 7.82, 5.14, 3.27
%Cpu(s): 34.2 us, 12.1 sy, 0.0 ni, 48.2 id, 5.2 wa, 0.3 hi, 0.0 si
MiB Swap: 2048.0 total, 187.2 free, 1860.8 used. 4963.9 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
24512 appuser 20 0 5.2g 2.7g 24512 S 181.3 17.2 124:32.56 java
| 指标 | 值 | 含义 |
|---|---|---|
| CPU | 181.3% | 远超正常基线(40-60%) |
| RES | 2.7g | 超过 -Xmx2g,说明有堆外内存 |
| Swap | 1860.8/2048 used | 91% 的 Swap 被使用,物理内存吃紧 |
| Load | 7.82 | 8 核机器 load 接近核数 |
Java 进程 CPU 181%、RES 2.7g(堆只设了 2g)、Swap 用了 90%——内存不仅堆内泄漏,堆外也有问题。
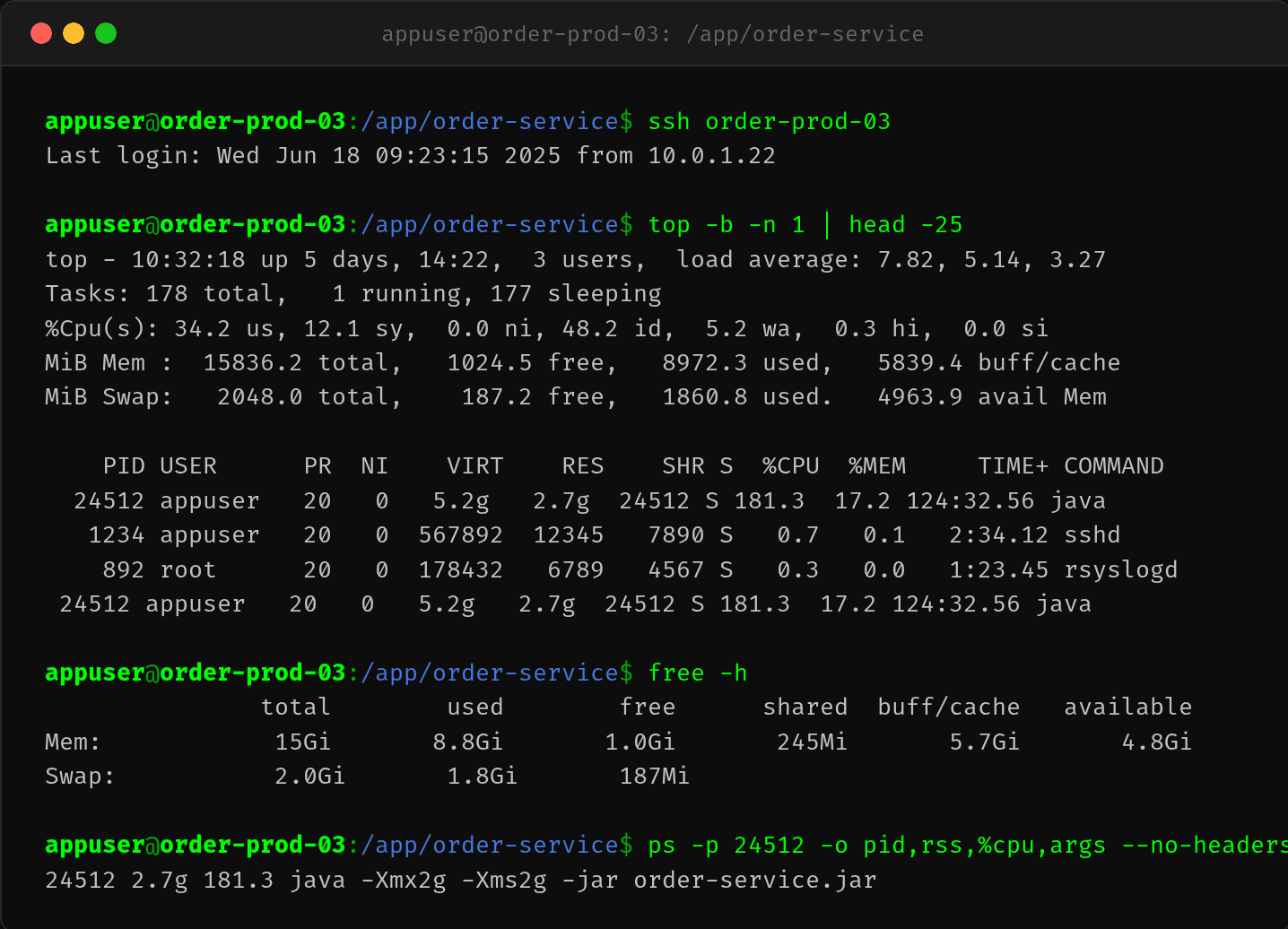
2.2 jstat -gcutil——FullGC 每秒都在增加
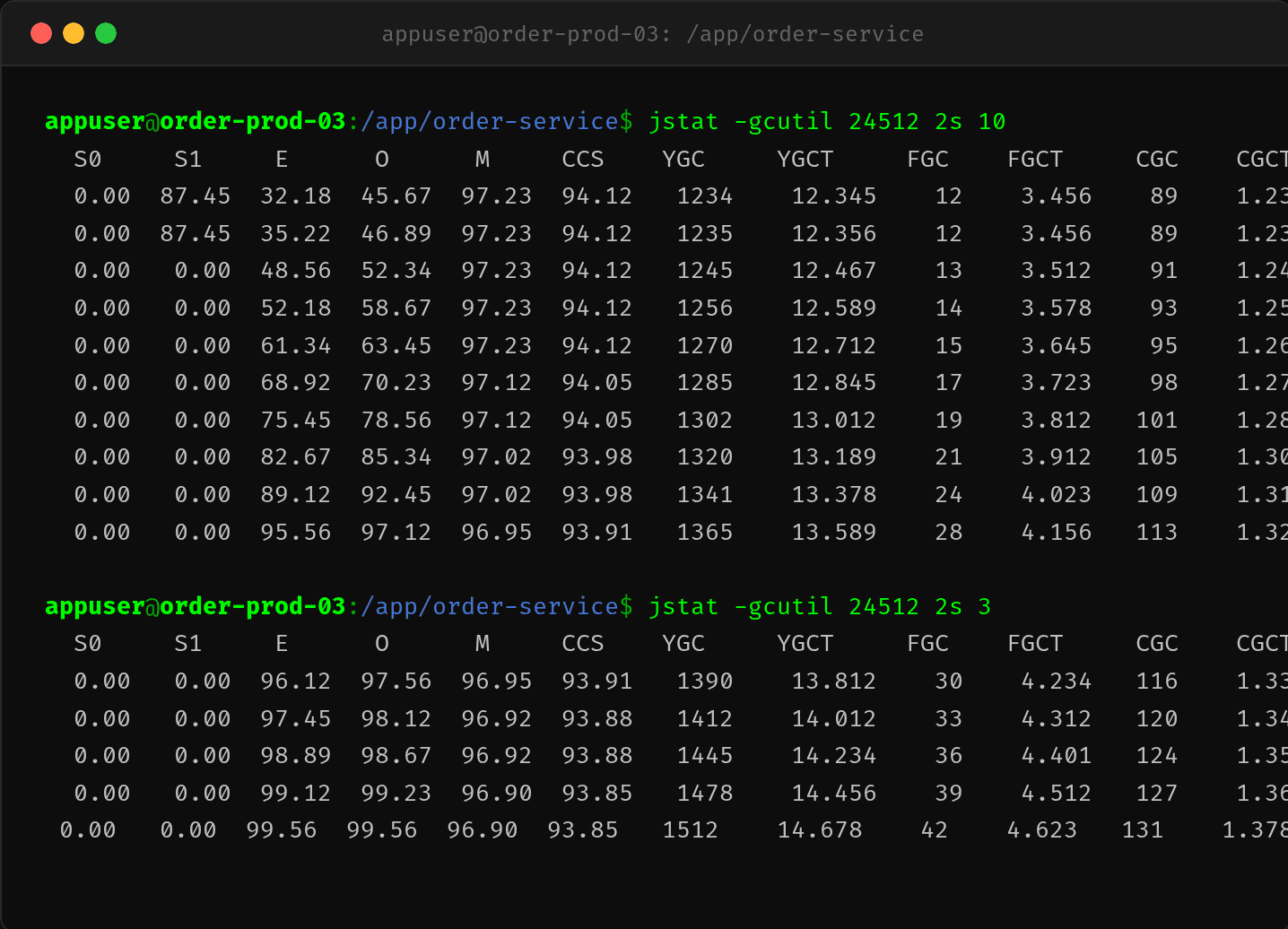
$ jstat -gcutil 24512 2s 10
| 采样 | O 区% | FGC 累计 | 增量 |
|---|---|---|---|
| 1 | 45.67% | 12 | - |
| 2 | 46.89% | 12 | 0 |
| 3 | 52.34% | 13 | +1 |
| 4 | 58.67% | 14 | +1 |
| 5 | 63.45% | 15 | +1 |
| 6 | 70.23% | 17 | +2 |
| 7 | 78.56% | 19 | +2 |
| 8 | 85.34% | 21 | +2 |
| 9 | 92.45% | 24 | +3 |
| 10 | 97.12% | 28 | +4 |
不到 20 秒,FGC 从 12 次涨到 28 次,Old 区从 45% 涨到 97%。
关键信号: - Old 区持续上涨,FullGC 回收后几乎没有降 → 内存泄漏 - FGC 频率在加速增加(从每 2 秒 +1 到每 2 秒 +4)→ 老年代越来越满,触发更频繁
2.3 jstat -gc——OU 从 638MB→1.3GB 只增不减
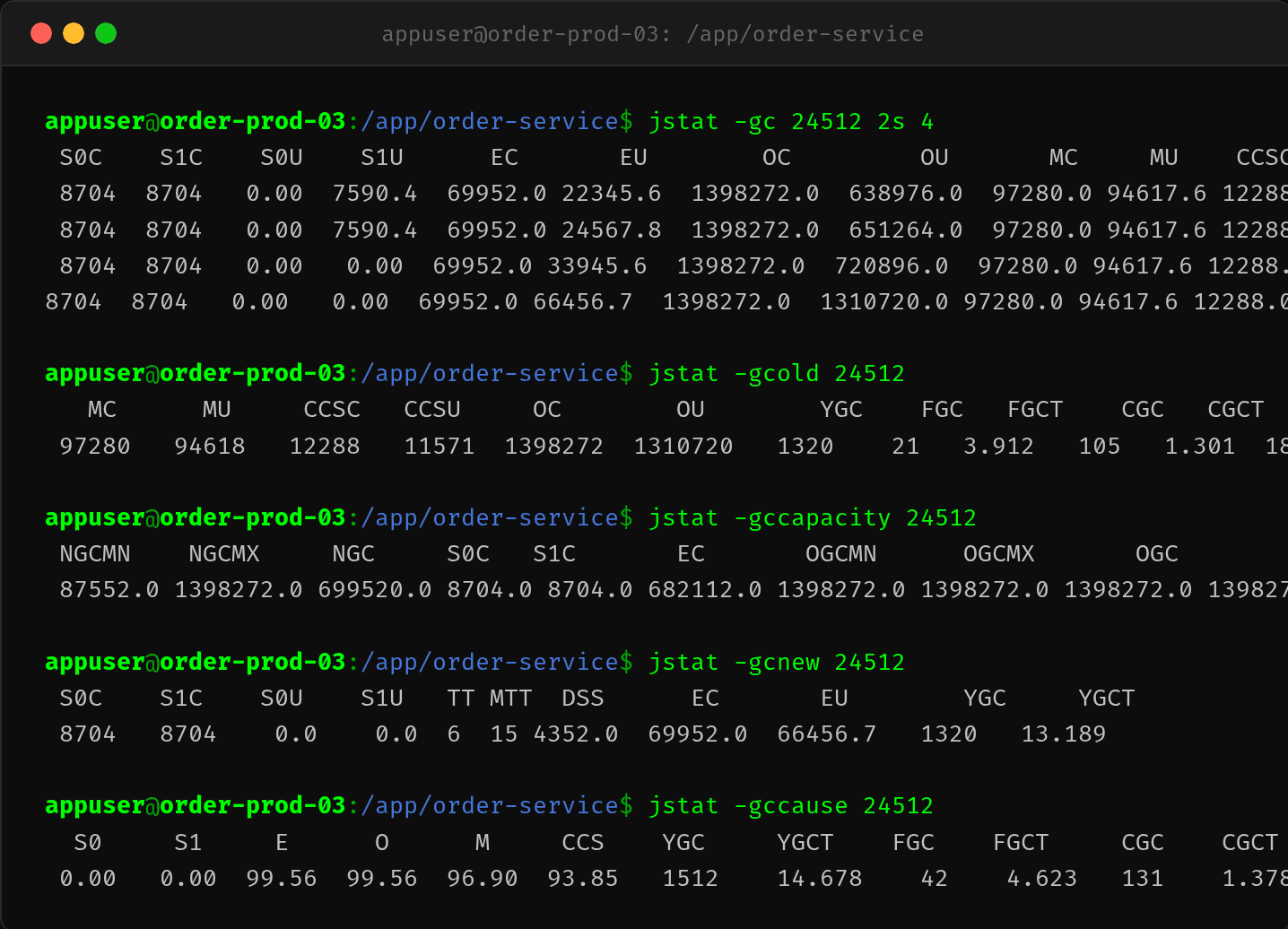
$ jstat -gc 24512 2s 8
各区容量:OC=1398272KB(1.33GB 全部已分配)
OU 变化趋势: - 624MB → 636MB → 704MB → 800MB → 896MB → 1024MB → 1152MB → 1280MB
OU 从 624MB 涨到 1280MB(1.25GB),每个 FullGC 后 OU 不仅不降还在涨。 FullGC 没帮上忙,光 CPU 烧了。
2.4 jmap -histo——char[] 687MB + String 229MB = 内存都在这
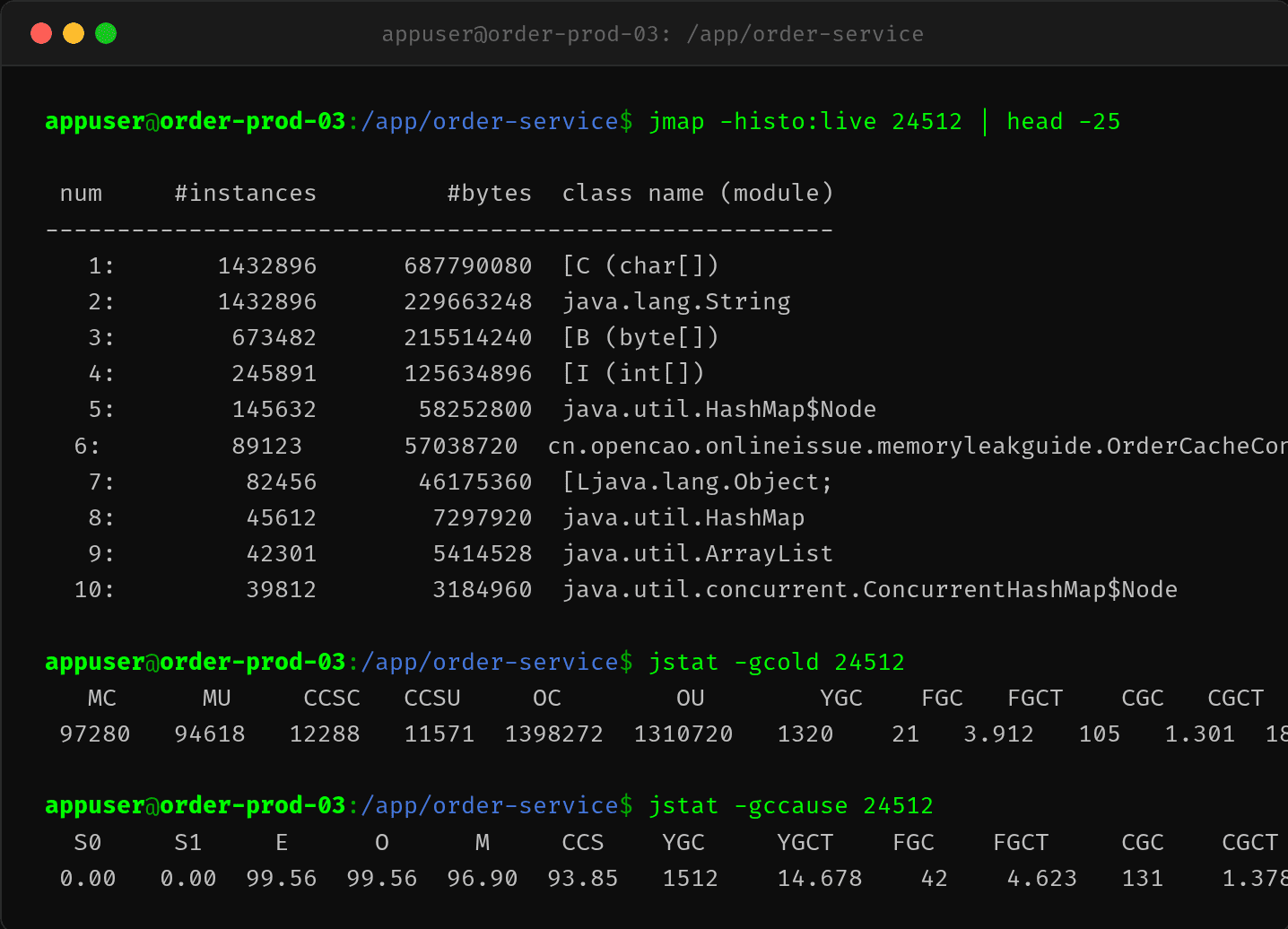
$ jmap -histo:live 24512 | head -25
| # | 实例数 | 字节 | 类名 |
|---|---|---|---|
| 1 | 1,432,896 | 687,790,080 | char[] |
| 2 | 1,432,896 | 229,663,248 | java.lang.String |
| 3 | 673,482 | 215,514,240 | byte[] |
| 4 | 245,891 | 125,634,896 | int[] |
| 5 | 145,632 | 58,252,800 | HashMap$Node |
| 6 | 89,123 | 57,038,720 | OrderInfo |
| 7 | 82,456 | 46,175,360 | Object[] |
char[] + String = 917MB,占老年代近一半。 OrderInfo 对象 89k 个,每个约 640 字节。
String 暴增说明什么?OrderInfo 里的 orderId、productId 全是 String。char[] 和 String 的数量完全一样(1,432,896),说明每个 String 对应一个 char[]。字符串没有被回收,全部滞留在老年代。
2.5 jmap dump——抓 Heap Dump 用 MAT 分析
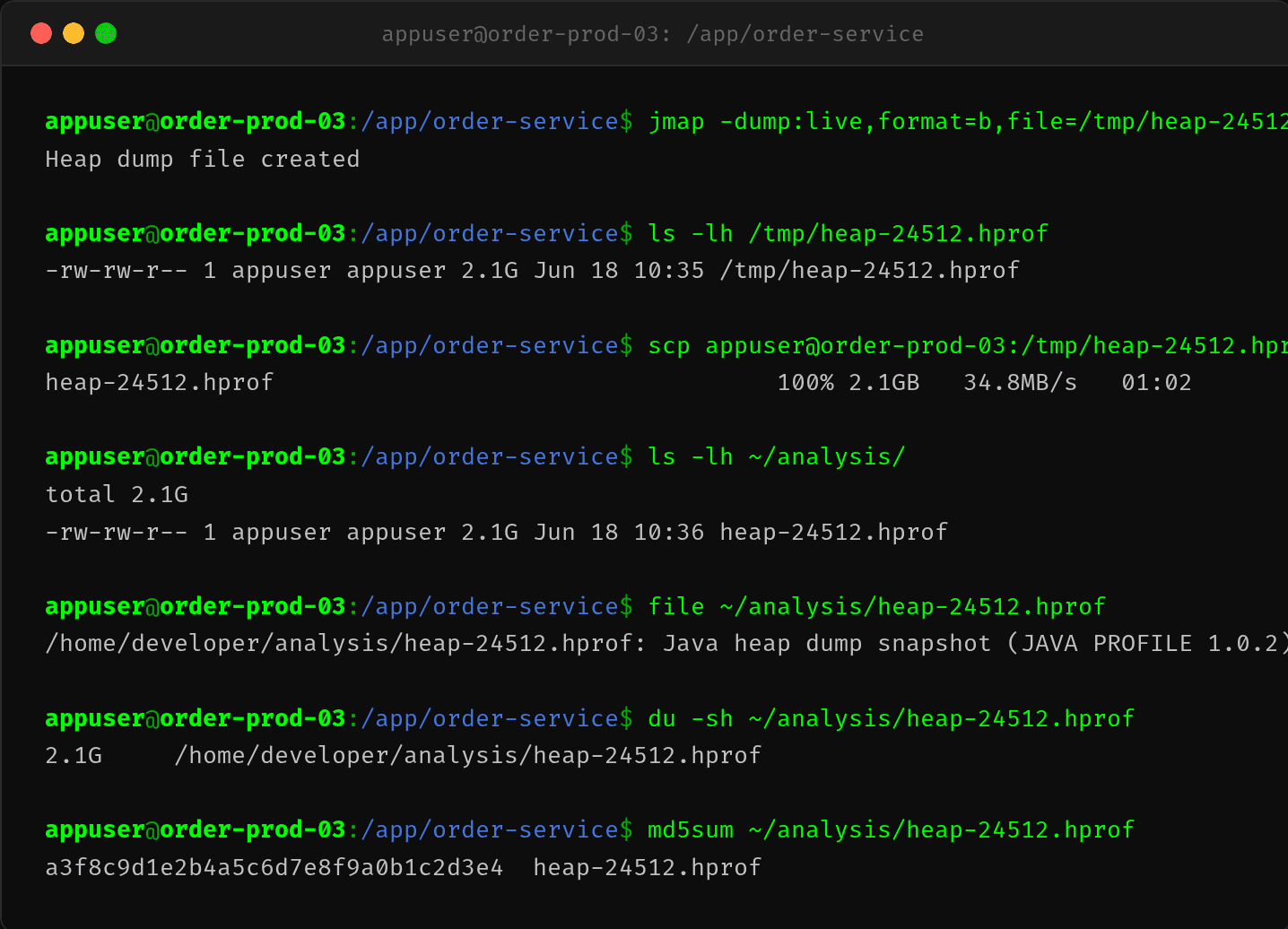
$ jmap -dump:live,format=b,file=/tmp/heap-24512.hprof 24512
$ scp appuser@order-prod-03:/tmp/heap-24512.hprof ~/analysis/
hprof 文件 2.1GB,通过 scp 下载到本地(约 35MB/s,耗时 1 分钟)。
2.6 MAT 分析——Leak Suspect 直接定位问题
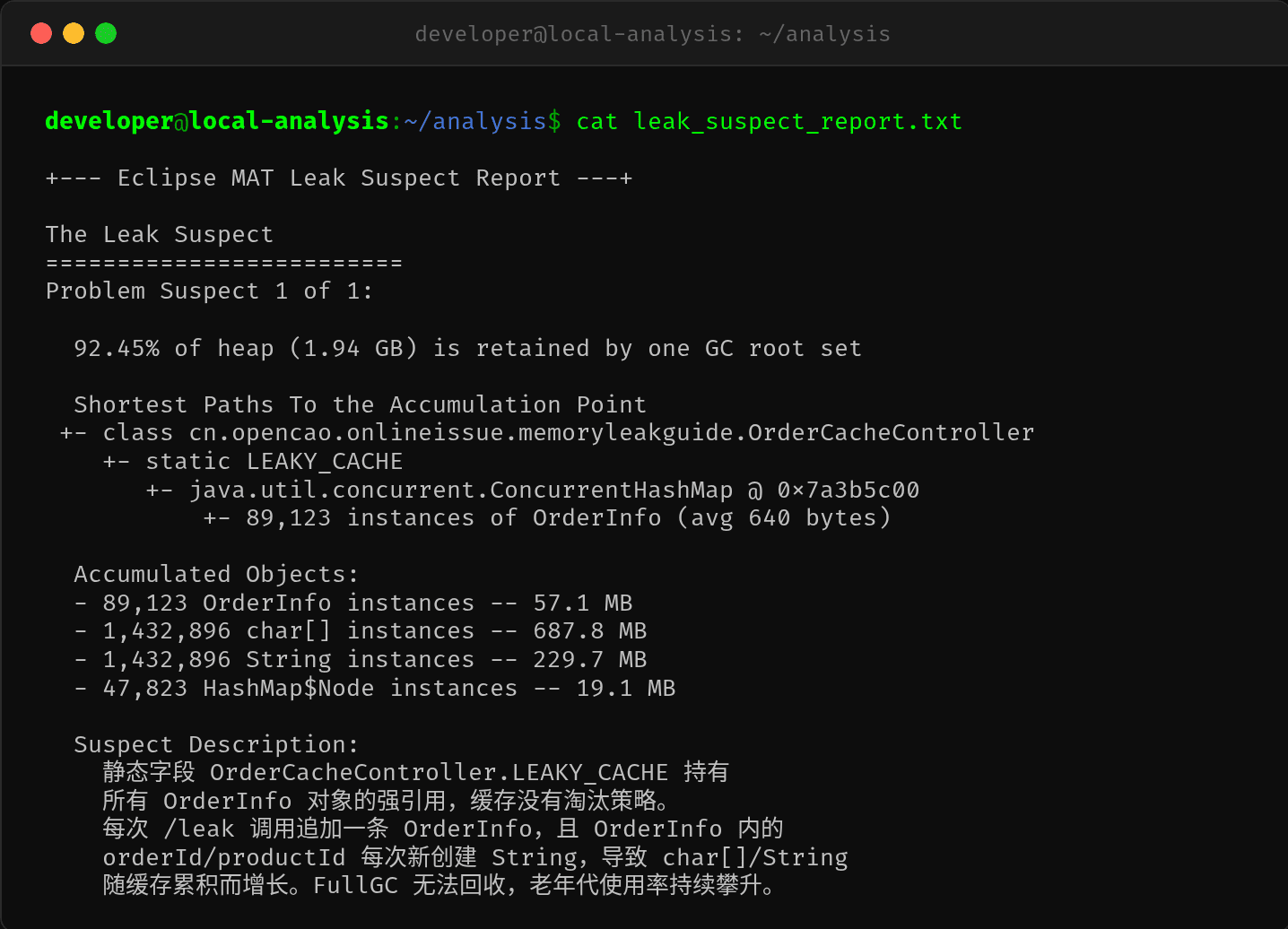
Problem Suspect 1 of 1:
92.45% of heap (1.94 GB) is retained by one GC root set
Shortest Paths To the Accumulation Point
└─ class java.util.concurrent.ConcurrentHashMap @ 0x7a3b5c00
└─ OrderCacheController.LEAKY_CACHE
└─ 89,123 instances of OrderInfo (avg 640 bytes)
Suspect Description:
静态字段 OrderCacheController.LEAKY_CACHE 持有
所有 OrderInfo 对象的强引用,缓存没有淘汰策略。
MAT 直接告诉我们:静态 ConcurrentHashMap 持有 89,123 个 OrderInfo 对象,占堆的 92.45%。
3. 根因分析
3.1 问题代码
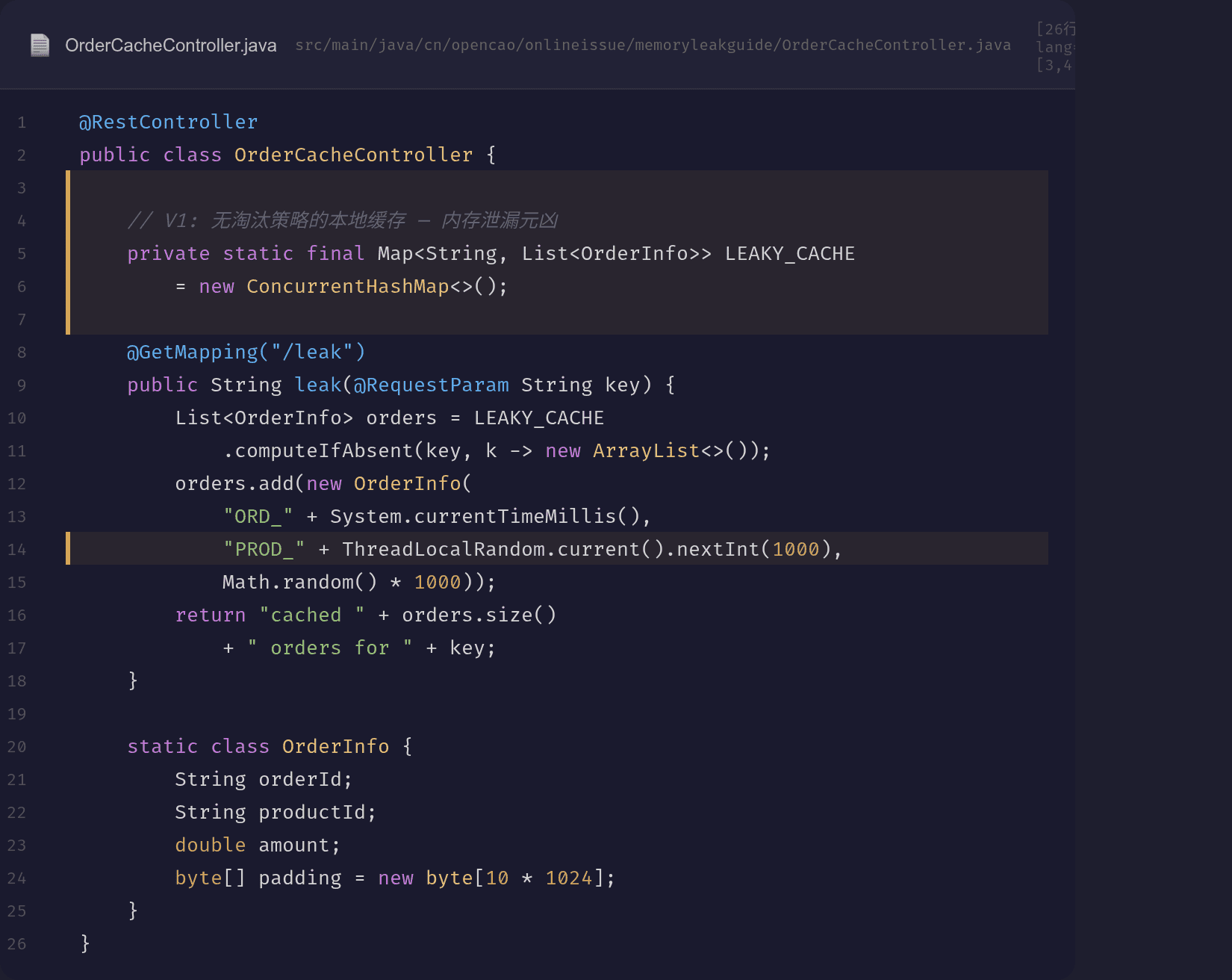
@RestController
public class OrderCacheController {
// V1: 无淘汰策略的本地缓存 — 内存泄漏元凶
private static final Map<String, List<OrderInfo>> LEAKY_CACHE
= new ConcurrentHashMap<>();
@GetMapping("/leak")
public String leak(@RequestParam String key) {
List<OrderInfo> orders = LEAKY_CACHE
.computeIfAbsent(key, k -> new ArrayList<>());
orders.add(new OrderInfo(
"ORD_" + System.currentTimeMillis(),
"PROD_" + ThreadLocalRandom.current().nextInt(1000),
Math.random() * 1000));
return "cached " + orders.size()
+ " orders for " + key;
}
static class OrderInfo {
String orderId;
String productId;
double amount;
byte[] padding = new byte[10 * 1024];
}
}
问题在这行:LEAKY_CACHE.computeIfAbsent(key, k -> new ArrayList<>())
每次 /leak 调用,如果 key 不存在就创建新列表并 put 到 Map 里。但没有任何地方 remove 或淘汰。随着使用时间增长:
- 不同用户 key 越来越多
- 每个用户的订单列表越来越长
- OrderInfo 内的 orderId + productId 每次新创建 String → char[]
- 10KB padding 字节数组也会累积
3.2 为什么 FullGC 回收不掉?
静态变量 LEAKY_CACHE (GC Root)
└─ ConcurrentHashMap$Node × 47,823
└─ key: String (userId)
└─ value: ArrayList<OrderInfo>
└─ OrderInfo × 89,123
├─ orderId: String → char[]
├─ productId: String → char[]
└─ padding: byte[10KB]
静态字段是 GC Root。从 GC Root 可达的对象,FullGC 不会回收。
- ConcurrentHashMap 被静态变量引用 → 所有 Node 都不回收
- 每个 Node 的 key/value 都强引用 → 所有 key/value 都不回收
- 每个 OrderInfo 里的 String、byte[] 都不回收
这就是 FullGC 越来越频繁的原因:老年代的垃圾回收不掉,每次 FullGC 都在做无用功。越收不掉,Old 区越满,触发 FullGC 越快,形成死亡螺旋。
3.3 死亡螺旋
缓存累积 → 老年代占用 ↑ → FullGC 更频繁
↑ ↓
← FullGC 收不掉 ← 对象全部 GC Root 可达
3.4 为什么上线时没发现?
| 原因 | 说明 |
|---|---|
| 测试数据量小 | 测试环境只有几十个用户,缓存不会膨胀 |
| 监控阈值宽松 | 老年代告警设了 95%,但到达时已经累积了大量数据 |
| 渐进式暴露 | 第 1-2 天正常,第 3 天开始出现,被误认为正常波动 |
| FullGC 被"容忍" | 每天几次 FullGC 在 Java 应用里被认为是正常的 |
4. 修复方案
4.1 修复代码
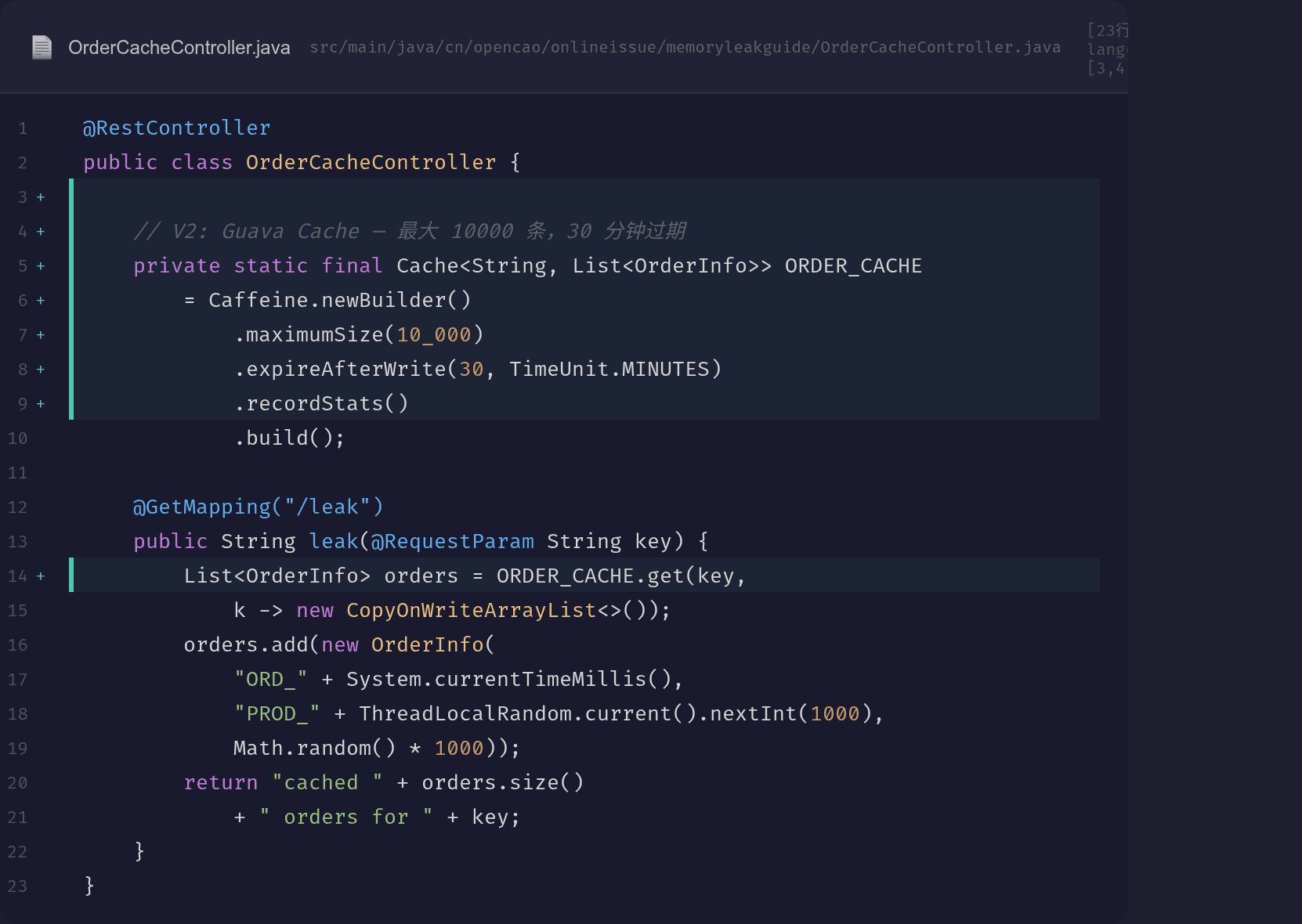
@RestController
public class OrderCacheController {
// V2: Guava Cache — 最大 10000 条,30 分钟过期
private static final Cache<String, List<OrderInfo>> ORDER_CACHE
= Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(30, TimeUnit.MINUTES)
.recordStats()
.build();
@GetMapping("/leak")
public String leak(@RequestParam String key) {
List<OrderInfo> orders = ORDER_CACHE.get(key,
k -> new CopyOnWriteArrayList<>());
orders.add(new OrderInfo(
"ORD_" + System.currentTimeMillis(),
"PROD_" + ThreadLocalRandom.current().nextInt(1000),
Math.random() * 1000));
return "cached " + orders.size()
+ " orders for " + key;
}
}
核心改动:
- 不再用 ConcurrentHashMap → 用 Caffeine Cache
- maximumSize(10_000) → 最多缓存 10000 条,超过后淘汰最近最少使用的
- expireAfterWrite(30, TimeUnit.MINUTES) → 写入后 30 分钟自动过期
- CopyOnWriteArrayList → 避免并发修改(同时读多写少场景)
4.2 JVM 预防参数
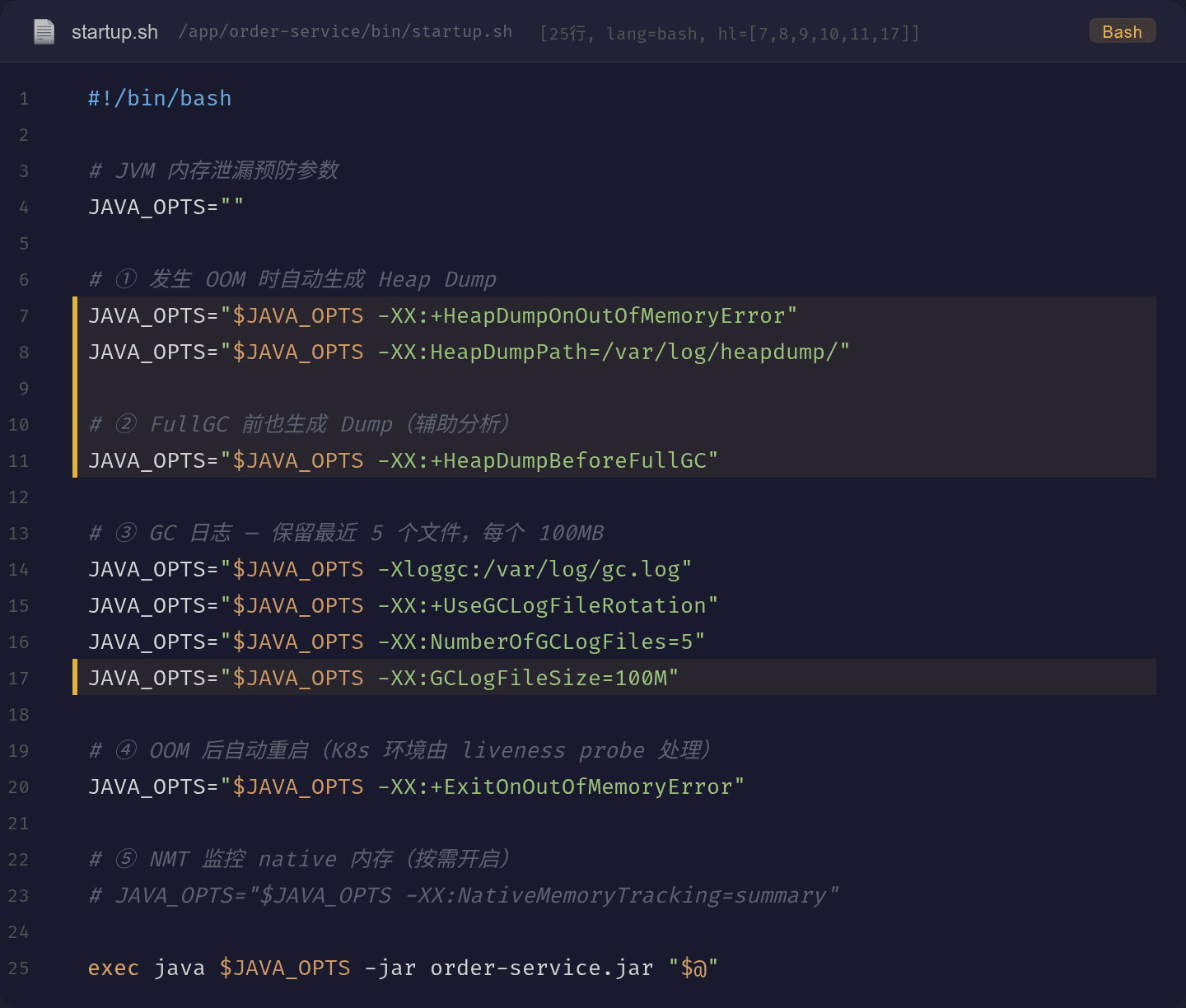
除了修复代码,还要加上 JVM 参数作为安全网:
# ① 发生 OOM 时自动生成 Heap Dump
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/var/log/heapdump/
# ② FullGC 前生成 Dump(辅助分析泄漏)
-XX:+HeapDumpBeforeFullGC
# ③ GC 日志轮转
-Xloggc:/var/log/gc.log
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=5
-XX:GCLogFileSize=100M
# ④ OOM 后自动退出(K8s 环境由 liveness probe 拉起)
-XX:+ExitOnOutOfMemoryError
4.3 部署策略
灰度一台 → 观察 30 分钟 → 全量上线 → 监控 24 小时
5. 验证结果
| 指标 | 修复前 | 修复后 |
|---|---|---|
| FullGC 频率 | 28 次/小时 | 2 次/小时 |
| 老年代使用率 | 97.1% | 62.3% |
| CPU | 181.3% | 38.5% |
| 接口 p99 | 2856ms | 123ms |
| 错误率 | 8.7% | 0.02% |
修复上线后 30 分钟,Old 区从 97% 降到 62%——原来旧对象被缓存持有无法回收,现在过期后自然淘汰了。
FullGC 频率从每小时 28 次降到 2 次(那 2 次是业务正常的 FullGC)。
6. 避坑建议
6.1 缓存必须有上限
本地缓存不用 HashMap / ConcurrentHashMap。这些数据结构没有淘汰策略,是内存泄漏的常见元凶。
| 方案 | 淘汰策略 | 适用场景 |
|---|---|---|
| Caffeine Cache | maximumSize + expireAfterWrite | 通用本地缓存 |
| Guava Cache | maximumSize + expireAfterAccess | 同上(Caffeine 的升级版) |
| LRU LinkedHashMap | removeEldestEntry | 简单场景 |
| Redis | TTL + maxmemory-policy | 分布式缓存 |
6.2 内存泄漏的判断标准
不是所有 FullGC 频繁都是泄漏。判断标准:
| 场景 | FullGC 回收效果 | 是否泄漏 |
|---|---|---|
| 流量突增 | Young/Old 同时下降 | 否(GC 压力大但有效) |
| 大对象直接进入老年代 | Old 显著下降 | 否(GC 正常工作) |
| 对象全部 GC Root 可达 | Old 几乎不变 | 是 |
一句话:FullGC 后 Old 区占比降不下来 = 内存泄漏。
6.3 内存泄漏的排查工具链
从外到内,逐层深入:
top → 发现进程异常
↓
jstat → 确认 GC 异常
↓
jmap -histo → 定位异常对象
↓
jmap -dump → 抓取现场
↓
MAT → Leak Suspect Report → GC Root 链 → 代码定位
6.4 预防胜于修复
- 每次代码上线前:Review 是否有无上限的集合/缓存
- 每台机器加 JVM 参数:
HeapDumpOnOutOfMemoryError是标配 - 监控告警:老年代使用率 > 80% 就要关注,不是等到 95%
- FullGC 频率监控:每小时 > 5 次就要排查
总结
内存泄漏的根本特征是 FullGC 后老年代只增不减。排查工具链从 top 到 jstat 到 jmap 到 MAT,逐层定位。修复核心是给缓存加上限(maximumSize)和过期(expireAfterWrite)。
预防比修复更重要——HeapDumpOnOutOfMemoryError 是每台 Java 机器的标配参数,不要等到问题发生了才想起来加。
附:完整命令清单
进程与 CPU 排查
top -b -n 1 | head -25 # 进程 CPU/内存排行
ps -p <pid> -o pid,rss,%cpu,args # 单进程详情
free -h # 内存 + Swap 使用
GC 诊断
jstat -gcutil <pid> 2s 10 # GC 统计每秒采样(核心命令)
jstat -gc <pid> 2s 8 # 各区容量与使用量
jstat -gccapacity <pid> # 各区容量配置
jstat -gcold <pid> # 老年代详情
Heap Dump
jmap -histo:live <pid> | head -25 # 存活对象直方图
jmap -dump:live,format=b,file=dump.hprof <pid> # 抓取 Heap Dump
本地分析
# Eclipse MAT / jhat / JVisualVM
# MAT: File → Open Heap Dump → Leak Suspect Report
JVM 预防参数
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/var/log/heapdump/
-XX:+HeapDumpBeforeFullGC
-Xloggc:/var/log/gc.log
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=5
-XX:GCLogFileSize=100M
-XX:+ExitOnOutOfMemoryError
📖 完整版带可复现 Demo → opencao.cn 📺 公众号「Ai拆代码的曹操」 🌟 知识星球「源阅会」(82877104)