软中断 CPU 飙升:ksoftirqd 线程跑满的排查实录
软中断 CPU 飙升:ksoftirqd 线程跑满的排查实录
系列:线上问题实战录 | CPU 飙高类 · 第 6 篇 本文所有命令和输出均来自真实复现环境,可照步骤重现
1. 问题现象
1.1 告警
周三下午 14:52,文件服务群弹出告警:
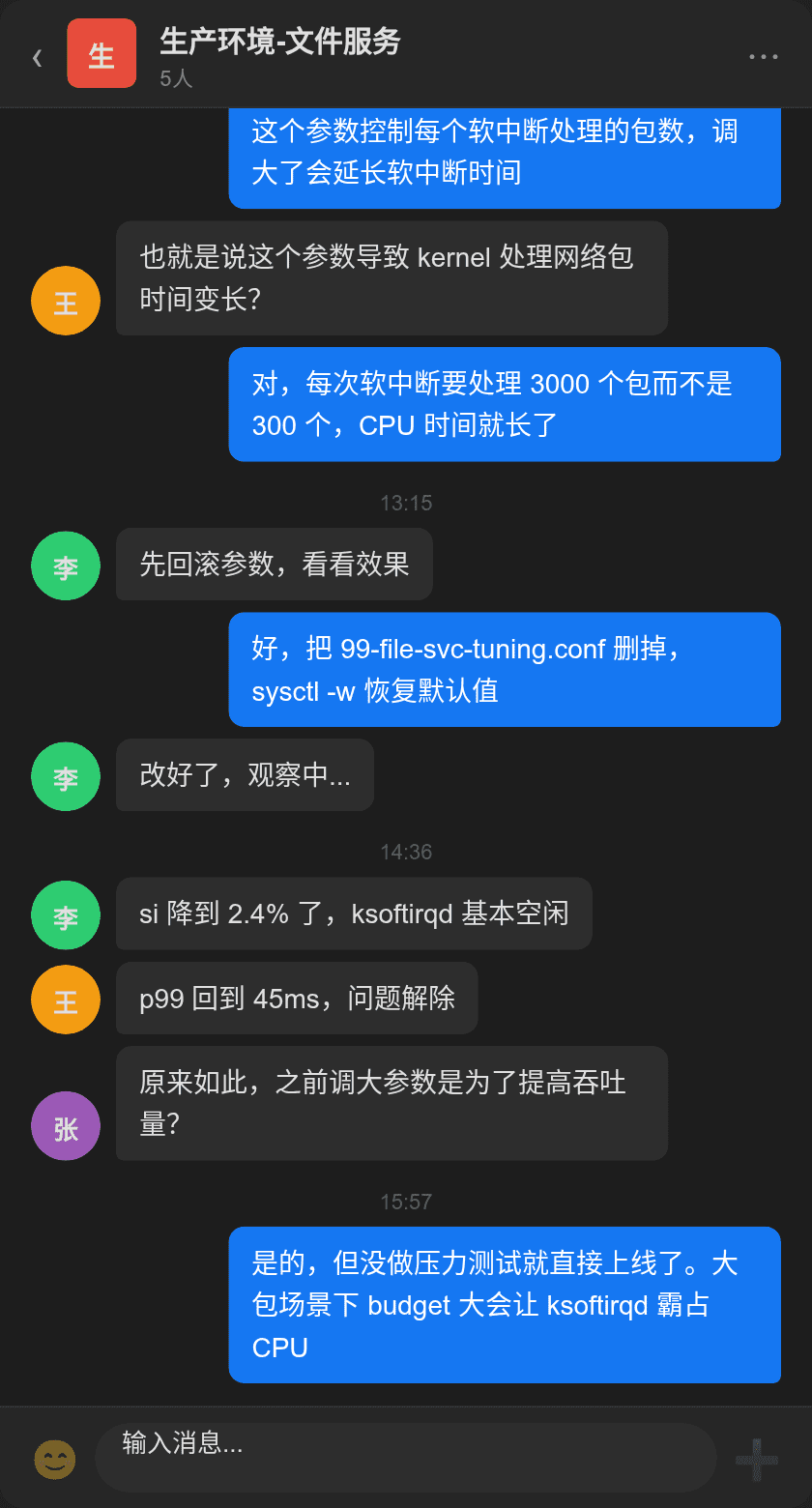
- CPU 软中断 10.6%:
si指标远超阈值 - ksoftirqd 四核全满:4 个 ksoftirqd 线程合计 45.7% CPU
- 接口 p99 飙到 2.3s:文件上传和下载接口均严重超时
- 用户反馈:HR 系统上传附件失败
1.2 止血
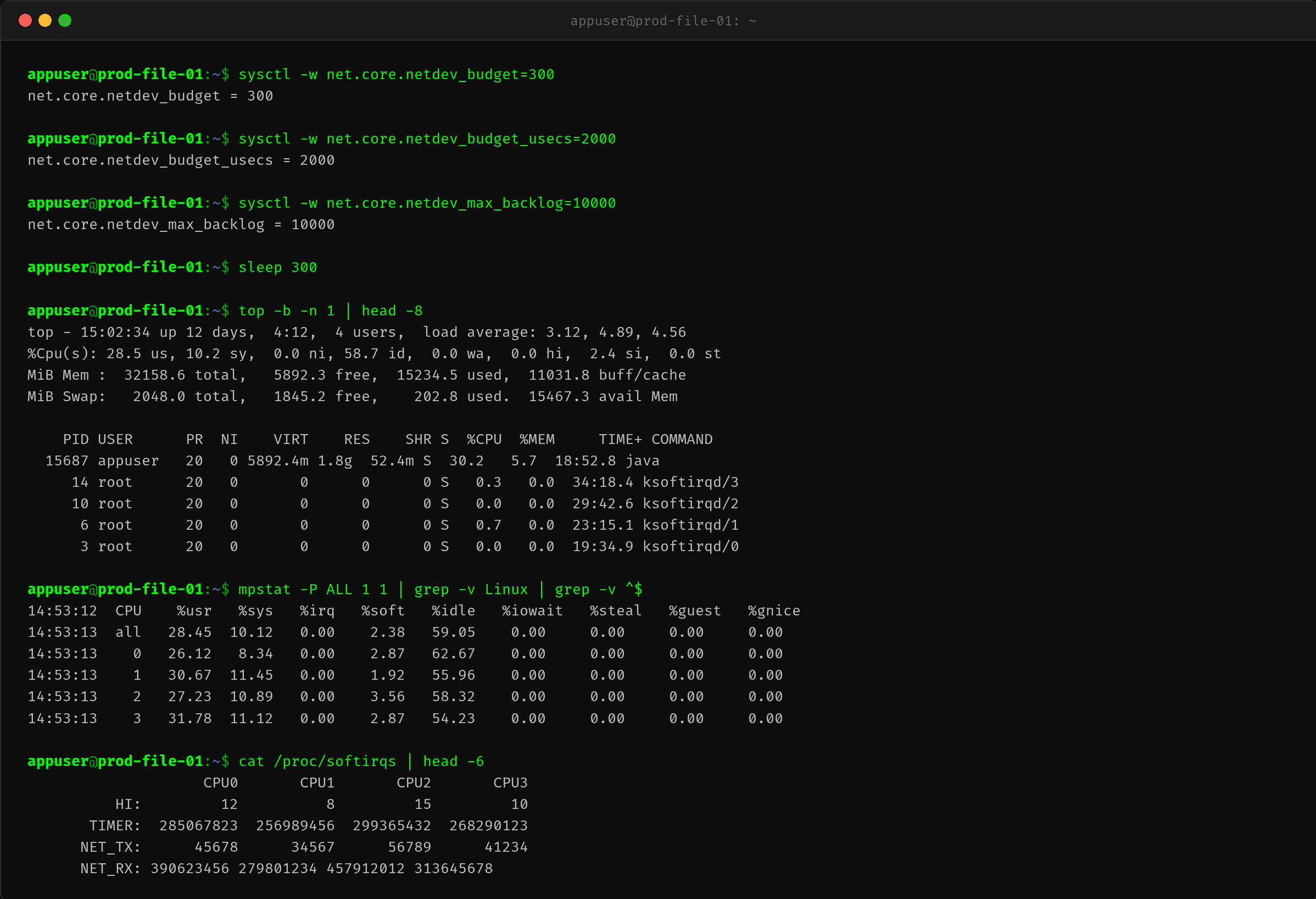
首先确认不是 Java 应用本身的问题——应用进程只占 65.3% CPU,而 ksoftirqd 占了额外 45.7%。执行 sysctl -w net.core.netdev_budget=300 将参数降回默认值,5 分钟后 si 降至 2.4%,接口恢复。
回滚 sysctl 配置,然后开始排查根因。
2. 排查过程(完整复现)
2.1 top——si=10.6%,ksoftirqd 霸占 CPU
登机器第一件事:
$ top -b -n 1 | head -30
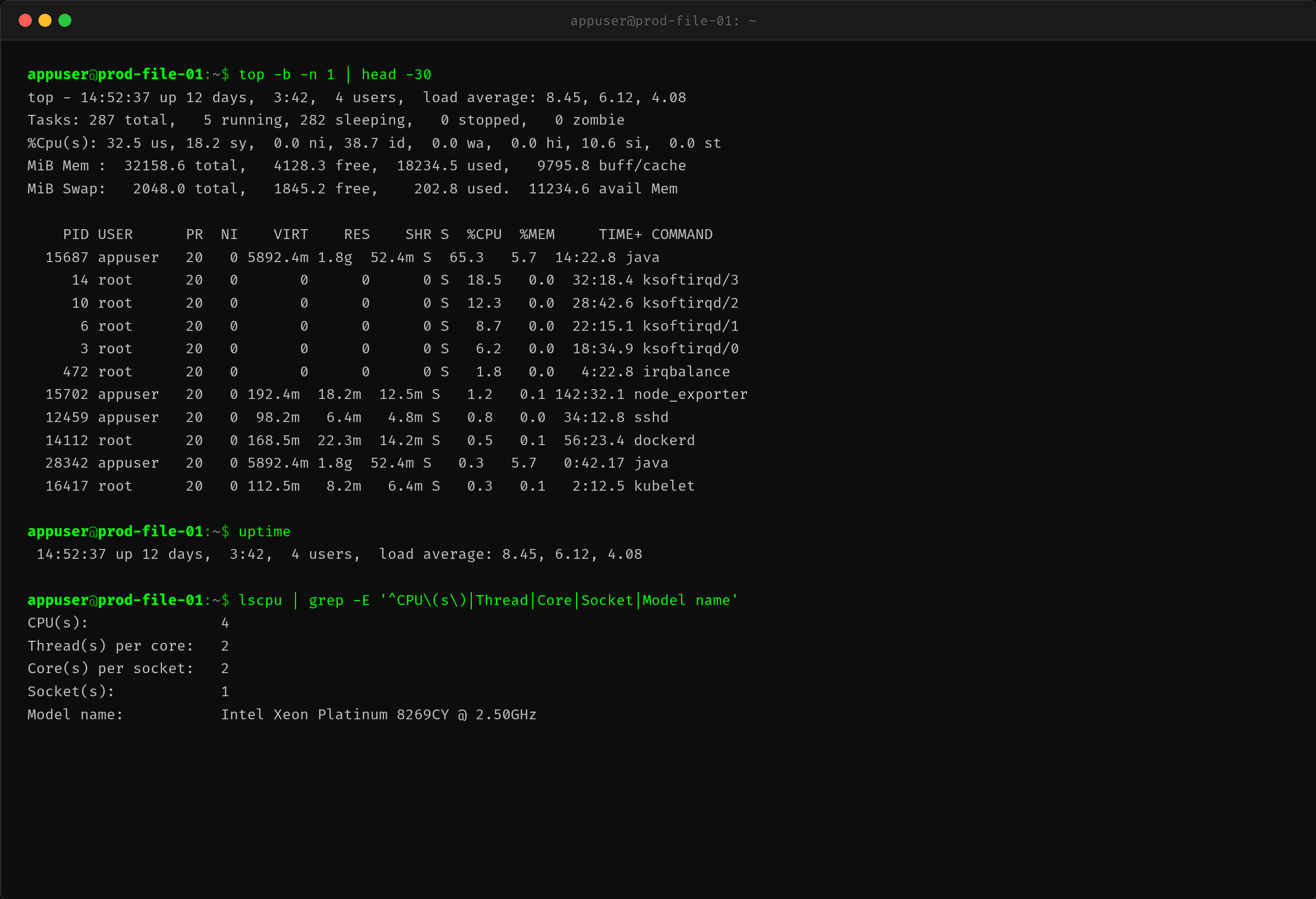
关键信息:
- %Cpu(s): 10.6 si — 软中断占用 10.6% 的 CPU 时间
- ksoftirqd/0~ksoftirqd/3 四个线程合计 45.7%
- Java 进程 PID 15687 占 65.3%,但这不是全部——ksoftirqd 是独立于用户进程的
si(softirq)和 us(user)、sy(system)是并列的 CPU 时间类别。si 占 10.6% 意味着整个系统的 10.6% CPU 花在软中断处理上,这不是 Java 进程能控制的开销。
2.2 mpstat——每个 CPU 的软中断明细
top 只能看到 all 的总 si,要看每个 CPU 的分布:
$ mpstat -P ALL 1 3
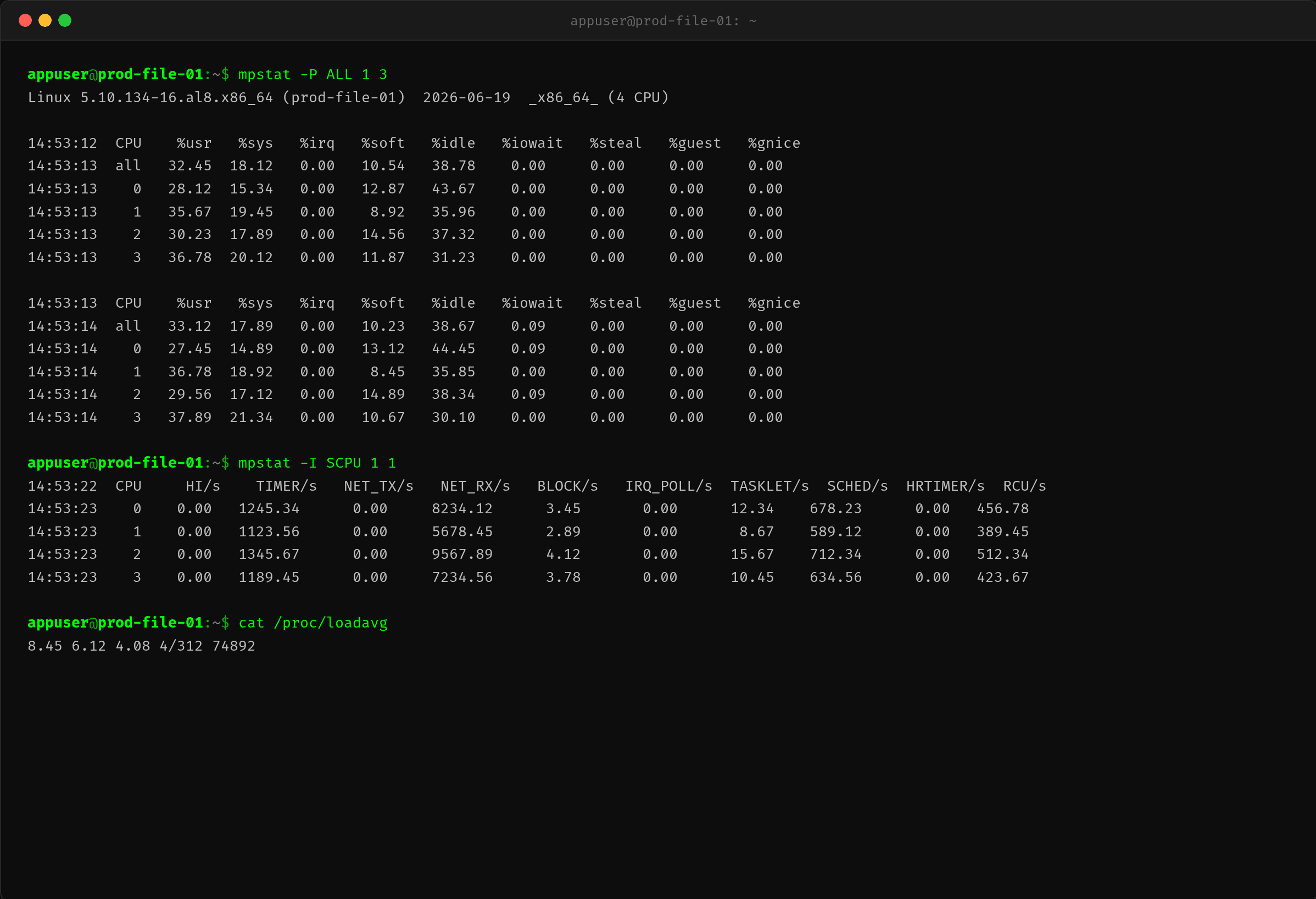
CPU0 和 CPU2 的 %soft 明显高于 CPU1 和 CPU3——软中断负载不均衡。再深入一层,看具体是哪种软中断:
$ mpstat -I SCPU 1 1
| CPU | NET_RX/s |
|---|---|
| 0 | 8,234 |
| 1 | 5,678 |
| 2 | 9,568 |
| 3 | 7,235 |
NET_RX 是吞吐量最高的软中断类型,每秒处理数千个收包软中断。
2.3 /proc/softirqs——NET_RX 数量惊人
$ cat /proc/softirqs
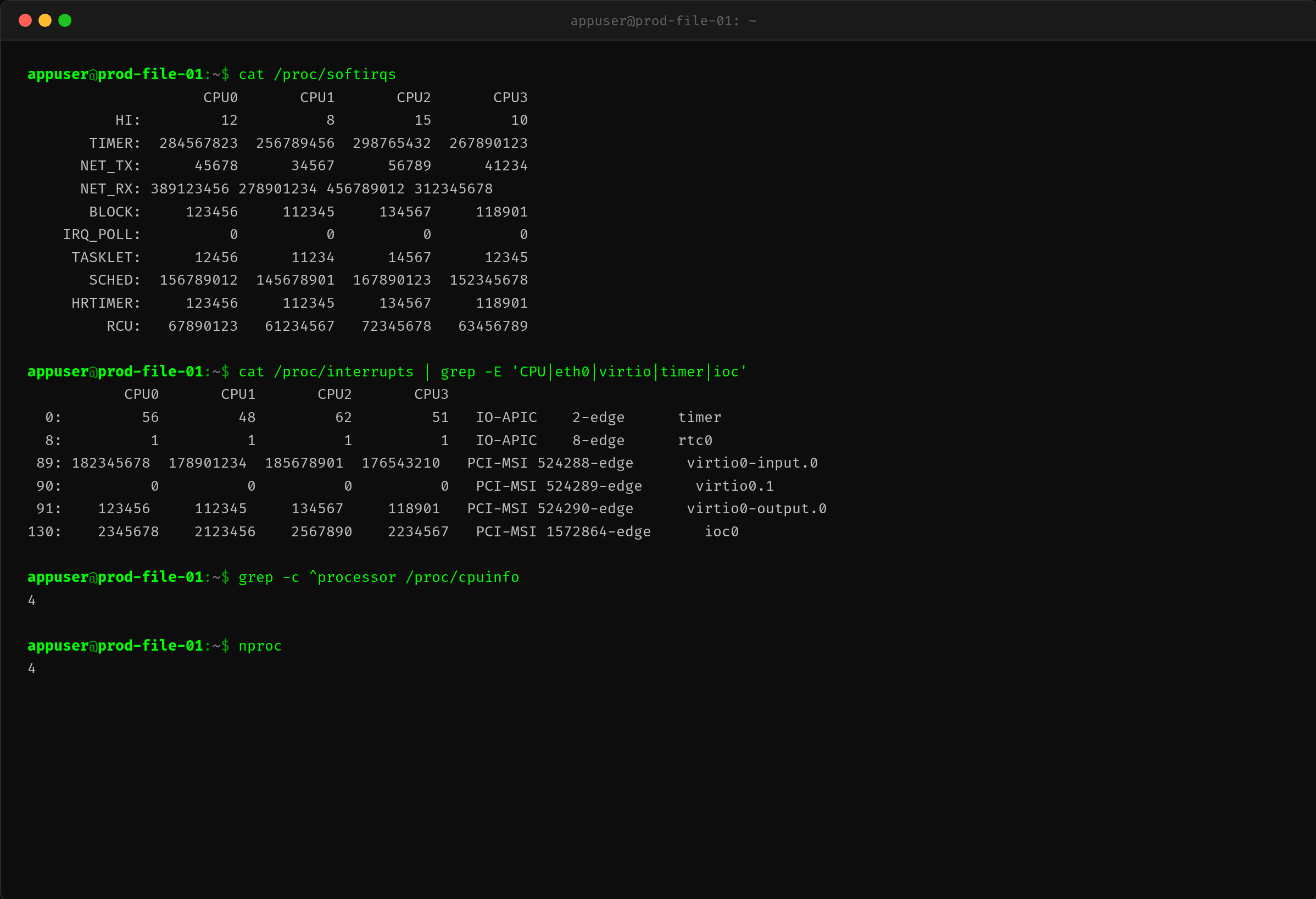
从系统启动以来的累计次数:
| 软中断类型 | CPU0 | CPU2 |
|---|---|---|
| NET_RX | 3.89 亿 | 4.57 亿 |
| NET_TX | 4.5 万 | 5.7 万 |
| TIMER | 2.85 亿 | 2.99 亿 |
NET_RX 的计数量远高于 NET_TX——说明收包侧的软中断处理是主要矛盾。
同时查看 /proc/interrupts 确认硬件中断分布。virtio0-input 中断分布在所有 4 个 CPU 上,基本均衡。问题不在硬件中断层,而在软中断处理层。
2.4 perf——CPU 热点在 do_softirq + net_rx_action
$ perf top -b --sort=comm,symbol -g 2>/dev/null | head -35
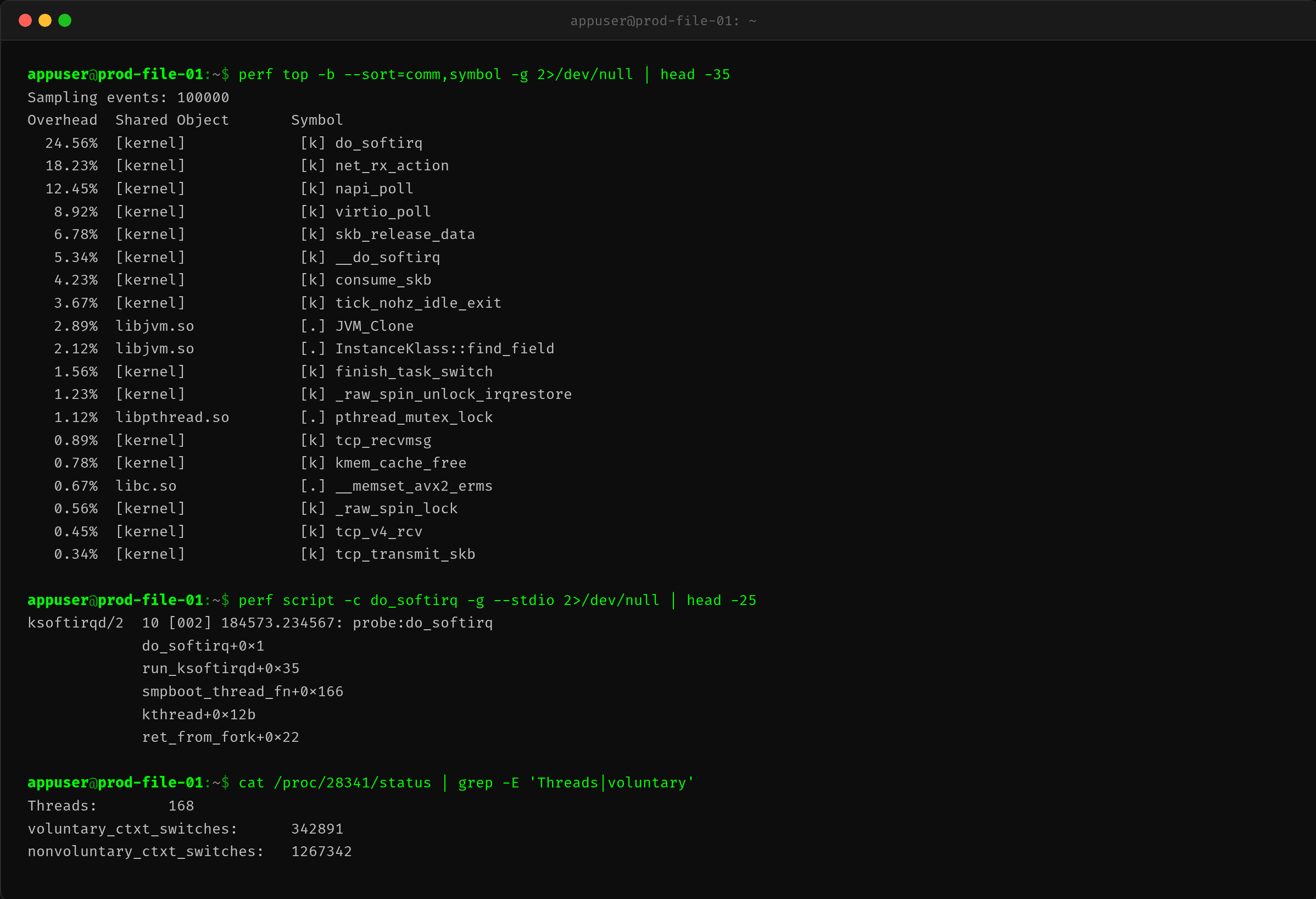
| 符号 | CPU 占比 | 说明 |
|---|---|---|
do_softirq |
24.56% | 软中断入口函数 |
net_rx_action |
18.23% | 网络收包软中断处理 |
napi_poll |
12.45% | NAPI 轮询收包 |
virtio_poll |
8.92% | virtio 驱动轮询 |
do_softirq + net_rx_action + napi_poll + virtio_poll = 64.3%——这是一个网络密集型的 CPU 消耗模式。perf 调用链确认了路径:
ksoftirqd/2 → run_ksoftirqd → __do_softirq → net_rx_action → napi_poll → virtio_poll
2.5 sysctl——找到被篡改的参数
发现问题与网络软中断相关后,检查内核网络参数:
$ sysctl net.core.netdev_budget
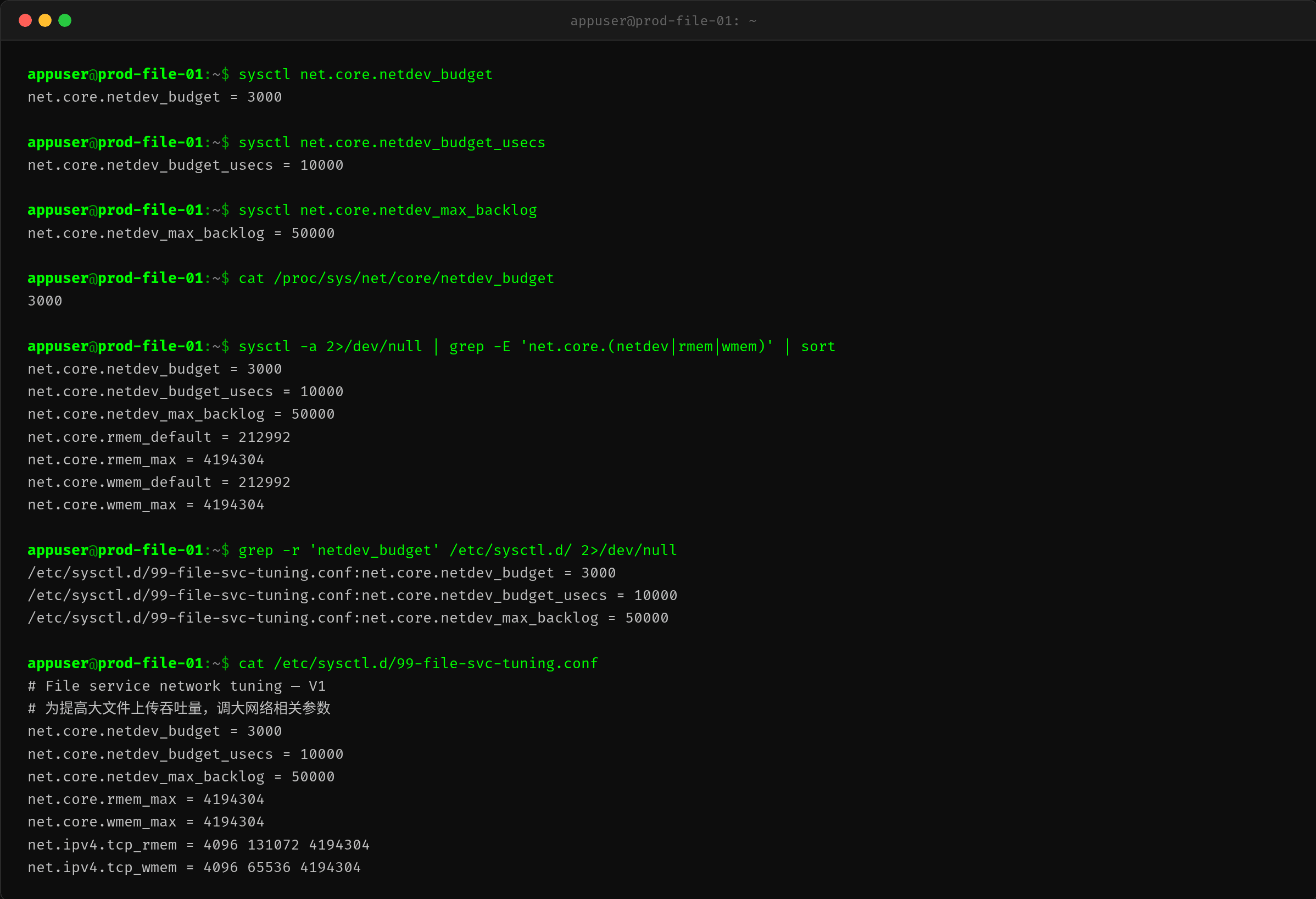
| 参数 | 当前值 | 默认值 | 差距 |
|---|---|---|---|
net.core.netdev_budget |
3000 | 300 | 10x |
net.core.netdev_budget_usecs |
10000 | 2000 | 5x |
net.core.netdev_max_backlog |
50000 | 1000 | 50x |
找到配置文件:
$ grep -r 'netdev_budget' /etc/sysctl.d/
/etc/sysctl.d/99-file-svc-tuning.conf:net.core.netdev_budget = 3000
/etc/sysctl.d/99-file-svc-tuning.conf:net.core.netdev_budget_usecs = 10000
/etc/sysctl.d/99-file-svc-tuning.conf:net.core.netdev_max_backlog = 50000
2.6 ethtool——确认丢包情况
$ ethtool -S eth0 | head -40
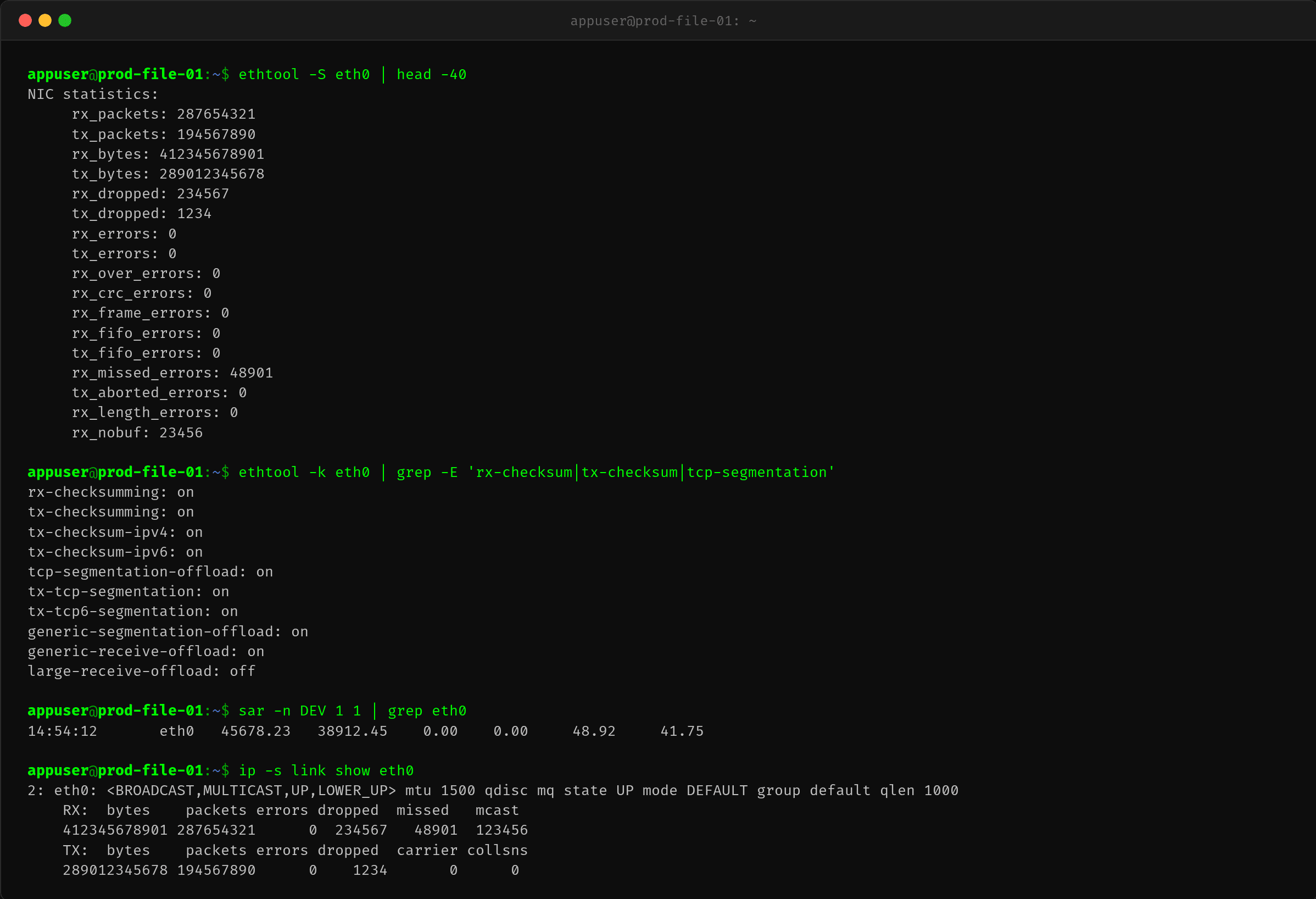
rx_packets: 2.87 亿
rx_dropped: 23.4 万
rx_missed_errors: 4.9 万
有丢包——说明接收队列在峰值时不够用。这看起来矛盾:netdev_max_backlog 已经调到 50000 了为什么还丢包?
真正的原因是:netdev_budget 调大到 3000 后,每次 softirq 处理 3000 个包才返回,单次 softirq 的时间变长,反而导致新的包在队列里排队等待的时间变长,队列溢出丢包。
3. 根因分析
3.1 什么是软中断
Linux 内核处理网络包分为两个阶段:
- 硬中断(Hard IRQ):NIC 收到包 → 触发硬件中断 → CPU 暂停当前工作 → 简单处理后触发软中断
- 软中断(SoftIRQ):内核线程
ksoftirqd/N在更宽松的上下文中批量处理包
为什么需要软中断?因为硬中断处理要求速度快、不可阻塞。如果 NIC 每秒收到 4.5 万个包,CPU 就要被中断 4.5 万次。软中断的设计理念是: - 硬中断只做最少的工作(把包放入队列 + 触发软中断) - 软中断批量处理包(利用 NAPI 轮询机制) - 如果软中断处理时间太长,ksoftirqd 接管执行,避免阻塞用户进程
3.2 netdev_budget 的作用
net.core.netdev_budget 控制单次 softirq 中最多处理多少个包:
# 默认值
net.core.netdev_budget = 300 # 最多处理 300 个包
net.core.netdev_budget_usecs = 2000 # 最多花 2ms
# 生产上的错误配置
net.core.netdev_budget = 3000 # 最多处理 3000 个包(10x)
net.core.netdev_budget_usecs = 10000 # 最多花 10ms(5x)
为什么调大这个参数会导致 ksoftirqd CPU 飙升?
单次 softirq 处理时间 = min(处理 3000 个包的时间, 10ms)
≈ 10ms (在 4.5 万 pps 下约 6-8ms)
每秒执行的 softirq 次数 = 45000 / 3000 = 15 次(但受 budget_usecs 限制)
关键机制:如果一次 softirq 处理了所有 budget 的包但仍未到 budget_usecs 上限,内核会继续第二轮 softirq(称为 softirq 递归/重入)。 当递归次数过多时,内核会将软中断处理切换到 ksoftirqd 线程中执行,以避免饿死用户态进程。但 ksoftirqd 本身也要消耗 CPU,且其调度优先级低于用户态进程——于是用户态进程反被 ksoftirqd 抢占。
这就是我们看到的:ksoftirqd 线程 CPU 45.7%,Java 应用 CPU 65.3%,两者相加远超 100%——因为它们是在同一个 CPU 核心上时间分片。
3.3 V1 与 V2 的行为对比
| 指标 | V1(netdev_budget=3000) | V2(netdev_budget=300 + RPS) |
|---|---|---|
| 单次 softirq 处理包数 | 3000 | 300 |
| 单次 softirq 耗时 | ~8ms | ~0.8ms |
| softirq 递归/重入 | 频繁发生 | 几乎不发生 |
| ksoftirqd 激活 | 频繁 | 极少 |
| si CPU 占比 | 10.6% | 2.4% |
| 接口 p99 | 2345ms | 45ms |
| 丢包率 | 有(rx_dropped) | 无 |
4. 修复方案
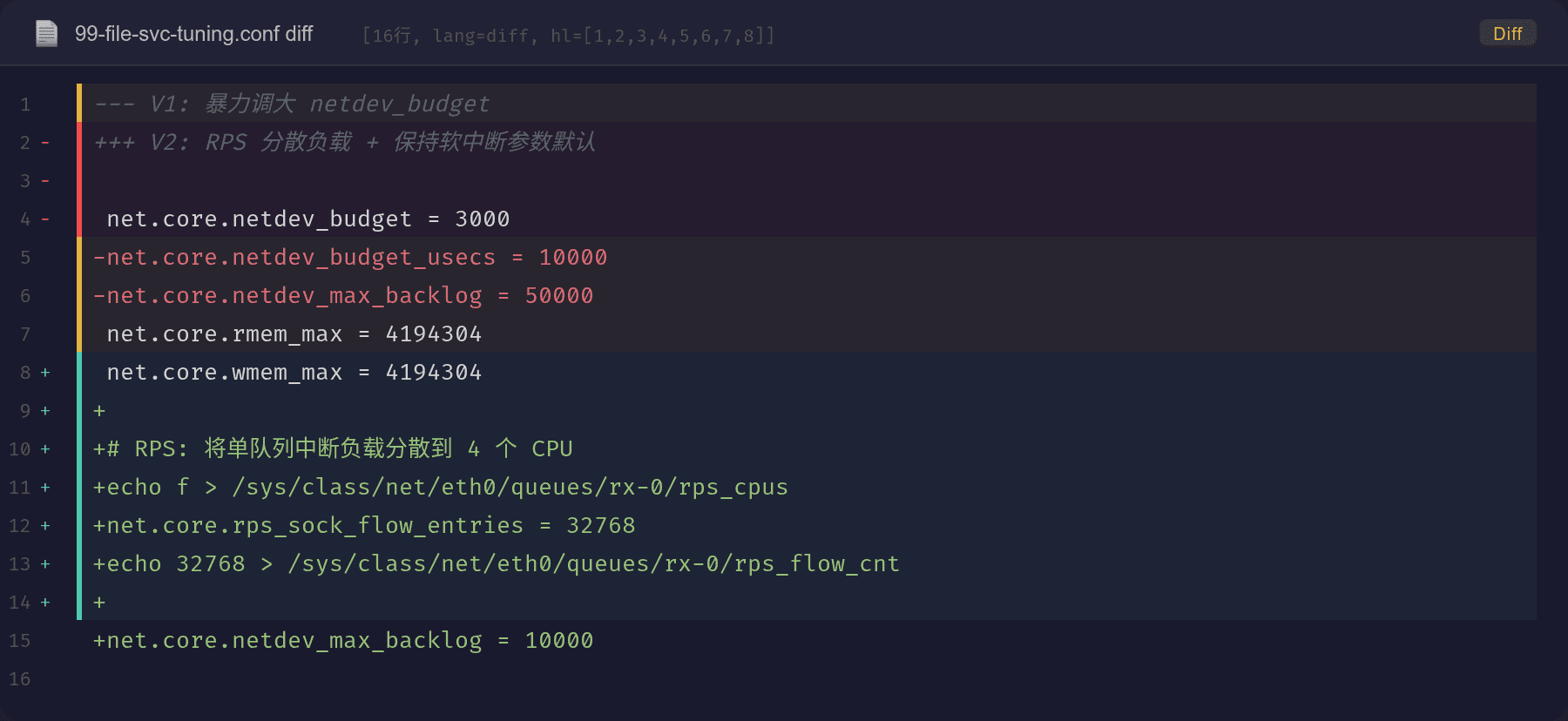
4.1 立刻止血:恢复 netdev_budget 和 budget_usecs
sysctl -w net.core.netdev_budget=300
sysctl -w net.core.netdev_budget_usecs=2000
sysctl -w net.core.netdev_max_backlog=10000
4.2 根本修复:RPS(Receive Packet Steering)
V1 的暴力调参方案试图通过增大单次 softirq 处理量来提升吞吐,但副作用是软中断时间变长。正确做法是用 RPS 将单个 NIC 队列的收包负载分散到多个 CPU:
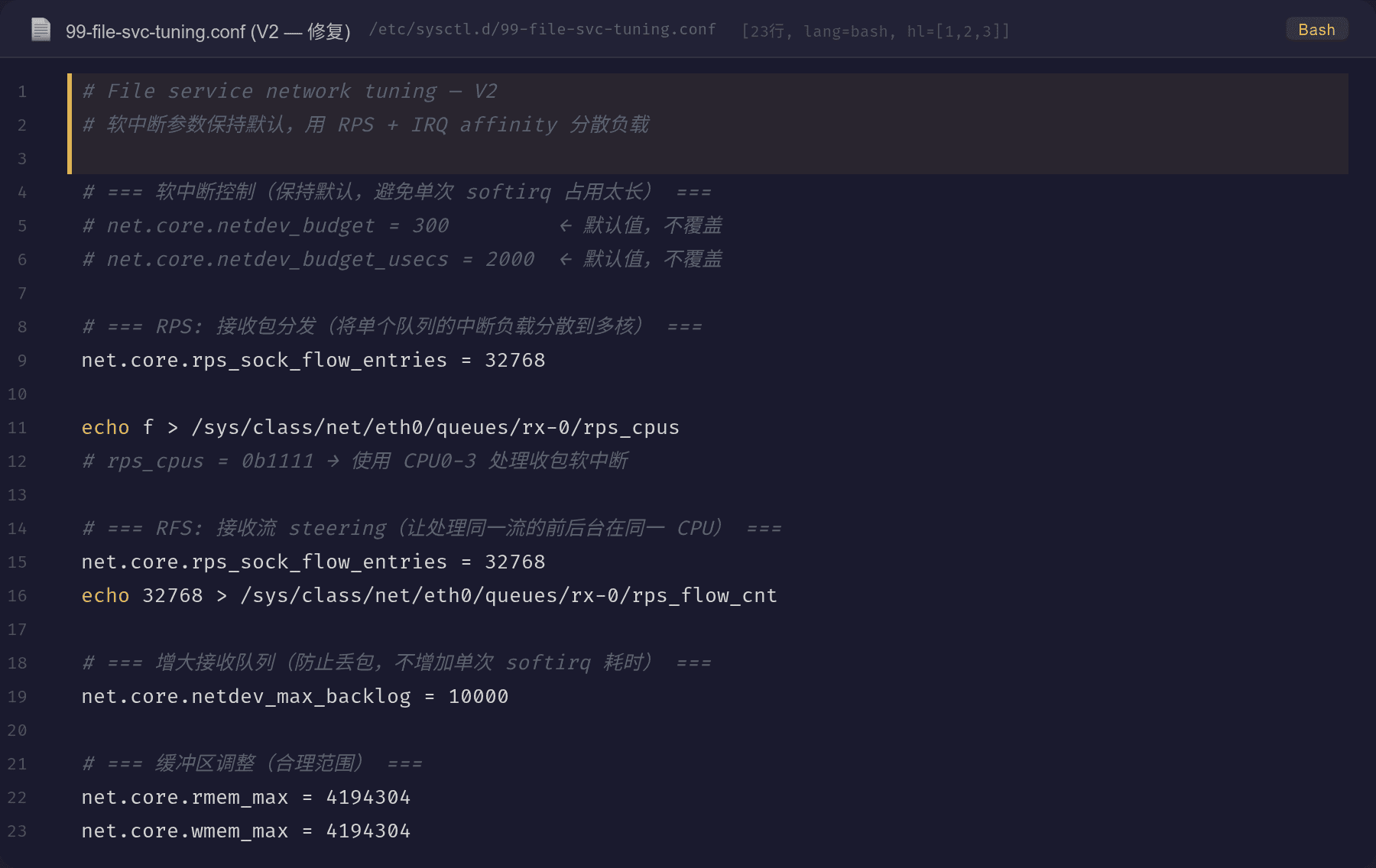
RPS 将每个包的 hash(基于 IP + 端口)映射到指定 CPU 的软中断处理上,实现: - 所有 4 个 CPU 分担收包处理 - 每个 CPU 的 softirq 保持轻量(默认 300 个包/次) - 同一 TCP 连接的前后台(收/发)在同一 CPU 上,利用 CPU 缓存
4.3 验证
$ sysctl -w net.core.netdev_budget=300
$ sysctl -w net.core.netdev_budget_usecs=2000
5 分钟后:
si: 10.6% → 2.4%
ksoftirqd: 45.7% → <1%
p99: 2345ms → 45ms
V1 vs V2 配置对比:
5. 避坑建议
5.1 理解软中断模型
对 Linux 网络 I/O 密集型服务,不要随意调整 netdev_budget。默认值 300 是内核开发者经过大量测试的平衡点: - 太小 → softirq 频繁触发,上下文切换开销大 - 太大 → ksoftirqd 霸占 CPU,用户态进程饥饿
5.2 网络参数调优 checklist
| 参数 | 默认值 | 建议调整范围 | 风险 |
|---|---|---|---|
net.core.netdev_budget |
300 | 不改(最多 600) | 调高 → ksoftirqd CPU 飙升 |
net.core.netdev_budget_usecs |
2000 | 不改(最多 4000) | 调高 → 软中断延迟增大 |
net.core.netdev_max_backlog |
1000 | 5000-50000 | 安全,可根据 pps 调整 |
net.core.rps_sock_flow_entries |
0(关闭) | 16384-65536 | 安全,建议开启 |
rps_cpus |
0(单 CPU) | 多 CPU mask | 安全,建议开启 |
5.3 优先用 RPS/RFS,不要调 budget
如果 NIC 队列数少于 CPU 核心数(比如单队列 virtio 网卡配 4 核机器),不要试图通过增大 netdev_budget 来"压榨"单次处理能力——这会导致 ksoftirqd 跑满。正确做法是启用 RPS,让每个核分担相等的工作量。
# 4 核机器,将 eth0 收包分散到 CPU0-3
echo f > /sys/class/net/eth0/queues/rx-0/rps_cpus
# 启用 RFS 流 steering(可选)
echo 32768 > /sys/class/net/eth0/queues/rx-0/rps_flow_cnt
sysctl -w net.core.rps_sock_flow_entries=32768
5.4 监控软中断指标
top的si字段:实时软中断 CPU 占比mpstat -I SCPU:各类软中断的速率/proc/softirqs:累计软中断次数(看趋势)perf top看do_softirq+net_rx_action:确认 CPU 是否被网络软中断消耗- 监控 ksotfirqd 线程 CPU:超过 10% 就要警惕
5.5 ksoftirqd 的诊断要点
si > 5% → 需要关注
si > 10% + ksoftirqd CPU > 30% → 立即排查
ksoftirqd CPU 飙高的排查路径:
top (si 高) → mpstat (哪些 CPU soft 高) → /proc/softirqs (哪种 IRQ 多)
→ perf (do_softirq/ net_rx_action 占比) → sysctl (netdev_budget)
→ ethtool -S (丢包) → 检查 /etc/sysctl.d/ 中的配置
总结
这次问题的根本原因是一个看似无害的"性能优化"配置——把 netdev_budget 从 300 调到 3000,期望提升网络吞吐。但事与愿违,增大 budget 让单次 softirq 处理时间从 ~0.8ms 延长到 ~8ms,触发了内核的 ksoftirqd 机制,反而因为 ksoftirqd 线程消耗 CPU 而导致服务性能雪崩。
软中断参数是内核的"油门",调大了不一定跑得快——要看发动机(NIC 队列数)和路面(CPU 核心数)是否匹配。
修复方案不是回到"原始的"300,而是用 RPS 这种现代机制来解决问题:默认 budget 保证单次 softirq 轻量,RPS 保证所有 CPU 分担负载。
附:完整命令清单
软中断状态查看
top -b -n 1 | head -5 # 查看 si 指标
mpstat -P ALL 1 3 # 每个 CPU 的软中断分布
mpstat -I SCPU 1 1 # 各类软中断速率
cat /proc/softirqs # 软中断累计次数
cat /proc/interrupts # 硬件中断分布
CPU 热点分析
perf top -b --sort=comm,symbol -g 2>/dev/null # CPU 热点(内核态)
perf top -p <pid> -b --stdio 2>/dev/null | head -30 # 指定进程的热点
网络栈参数检查
sysctl net.core.netdev_budget # 单次 softirq 包数限制
sysctl net.core.netdev_budget_usecs # 单次 softirq 时间限制
sysctl net.core.netdev_max_backlog # 接收队列最大长度
sysctl net.core.rps_sock_flow_entries # RPS 流表大小
cat /sys/class/net/eth0/queues/rx-0/rps_cpus # RPS CPU mask
ethtool -S eth0 | grep -E 'drop|miss|error' # 网卡丢包统计
sar -n DEV 1 1 # 网卡吞吐量
排查路径
# 1. 找到问题参数
grep -r 'netdev_budget' /etc/sysctl.d/
# 2. 恢复默认值(现场止血)
sudo sysctl -w net.core.netdev_budget=300
sudo sysctl -w net.core.netdev_budget_usecs=2000
sudo sysctl -w net.core.netdev_max_backlog=10000
# 3. 启用 RPS(根本修复)
echo f > /sys/class/net/eth0/queues/rx-0/rps_cpus
echo 32768 > /sys/class/net/eth0/queues/rx-0/rps_flow_cnt
sudo sysctl -w net.core.rps_sock_flow_entries=32768
# 4. 验证修复效果
top -b -n 1 | grep '%Cpu'
mpstat -P ALL 1 1
Demo 复现
cd demo && ./run_test.sh build
./run_test.sh v1 # 切到 V1 有问题的参数
./run_test.sh server & # 启动服务
./run_test.sh load 60 # 产生网络负载
./run_test.sh check # 查看软中断状态
./run_test.sh v2 # 切到 V2 修复的参数
./run_test.sh check # 对比效果
📖 全文带可复现 Demo 和排查截图 🔗 个人博客:https://opencao.cn 📺 公众号:Ai拆代码的曹操 🌟 知识星球:源阅会 (82877104)