HikariCP 默认配置是陷阱?我见过的最多生产事故来源
HikariCP 默认配置是陷阱?我见过的最多生产事故来源
本文是Spring Boot 生产配置实战系列的首篇 叙事框架:
现象 → 排查过程 → 根因 → 修复 → 预防
问题现象
早高峰 9:45,告警群突然炸了——order-service 接口 p99 响应时间飙到 3.2 秒,错误率 4.7%,Customer 投诉订单创建失败。
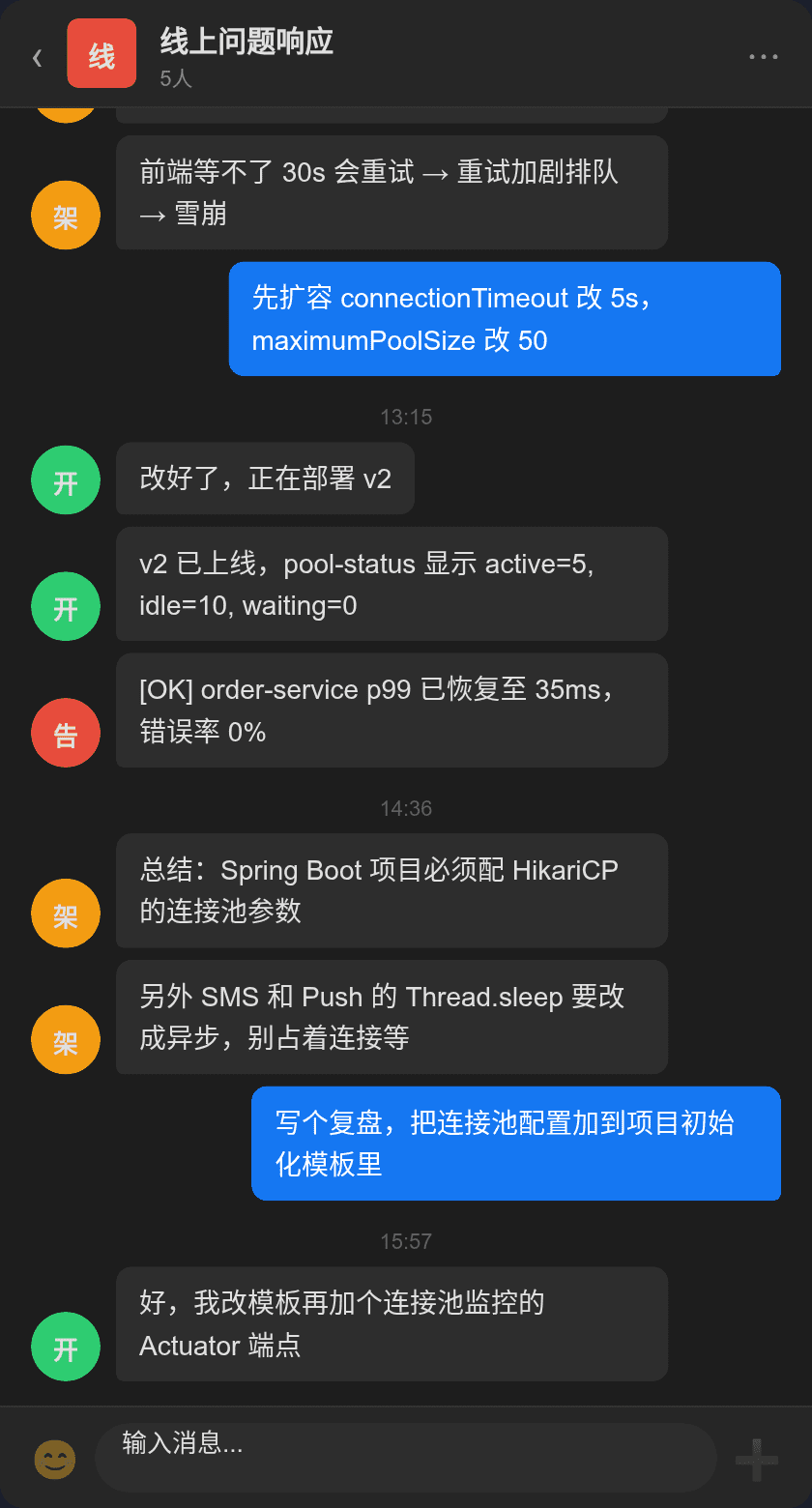
值班小A上去一看,CPU 才 35%,不是 CPU 问题。
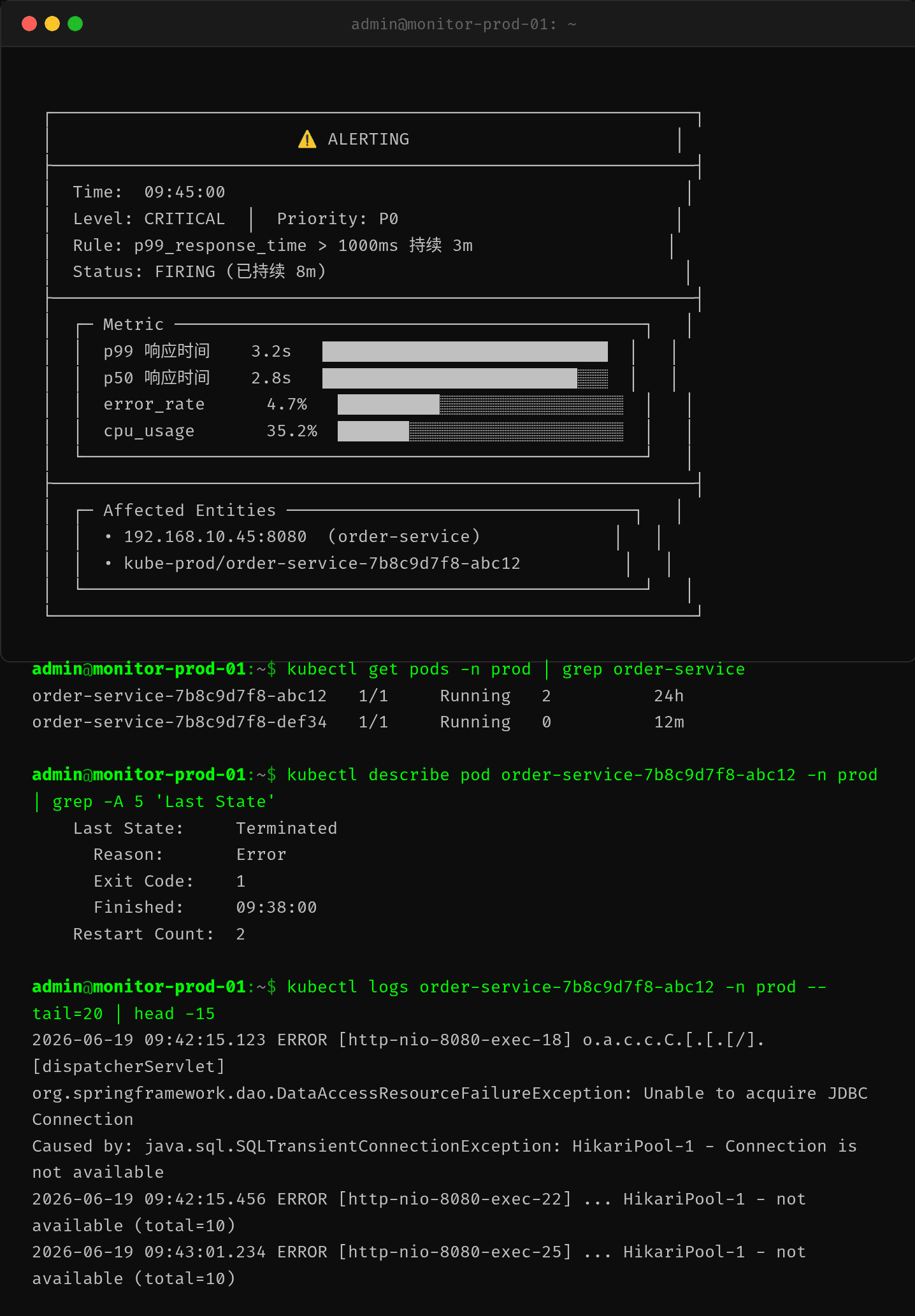
有意思的是:CPU 才 35%。不是 CPU 爆了。那是什么?
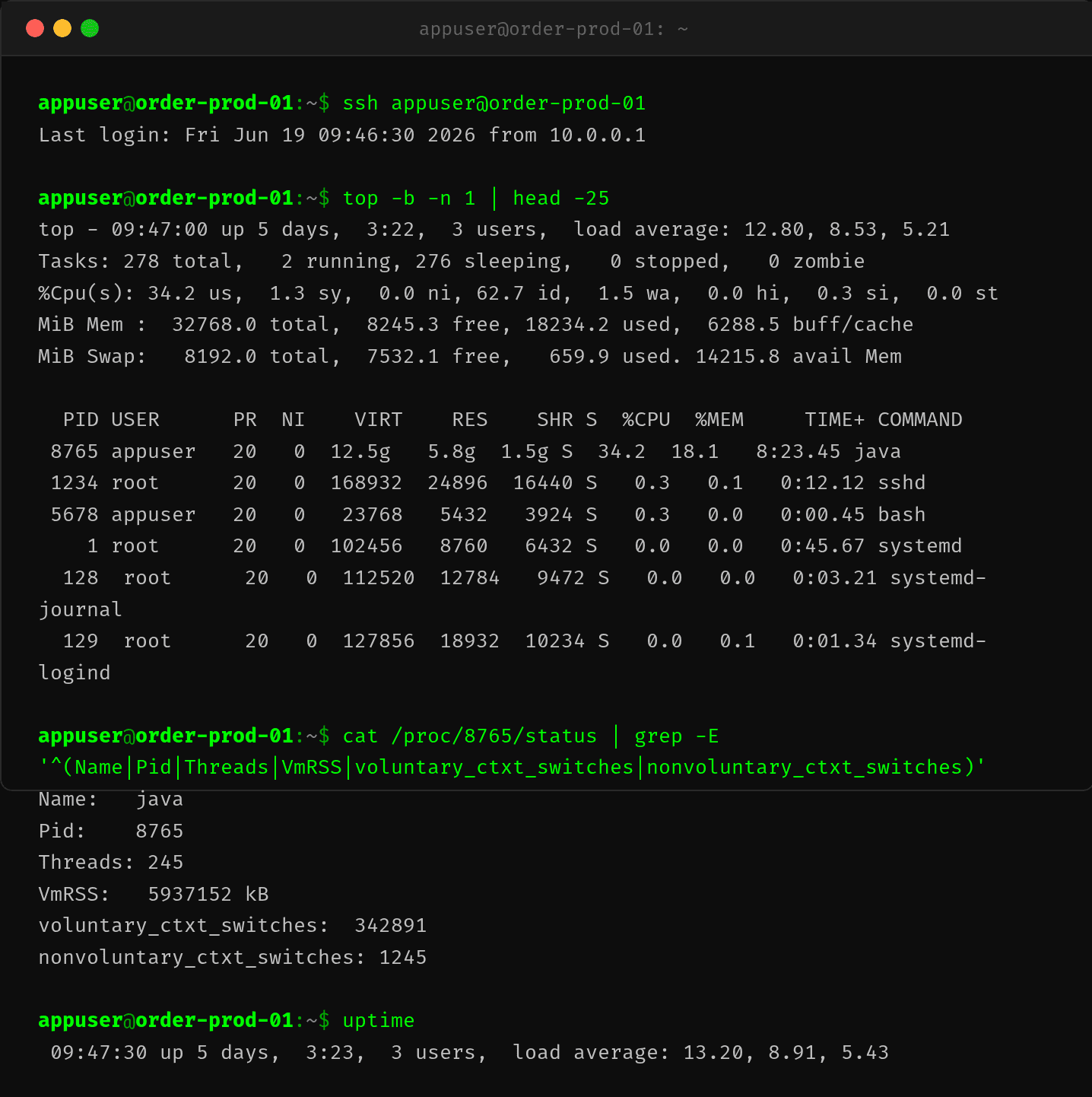
值班小A登录服务器一看,load average 13,CPU 才用 35%——显然不是计算密集型问题,进程大概率在等 IO。
排查过程
第一步:看连接
跑 netstat 看网络连接:
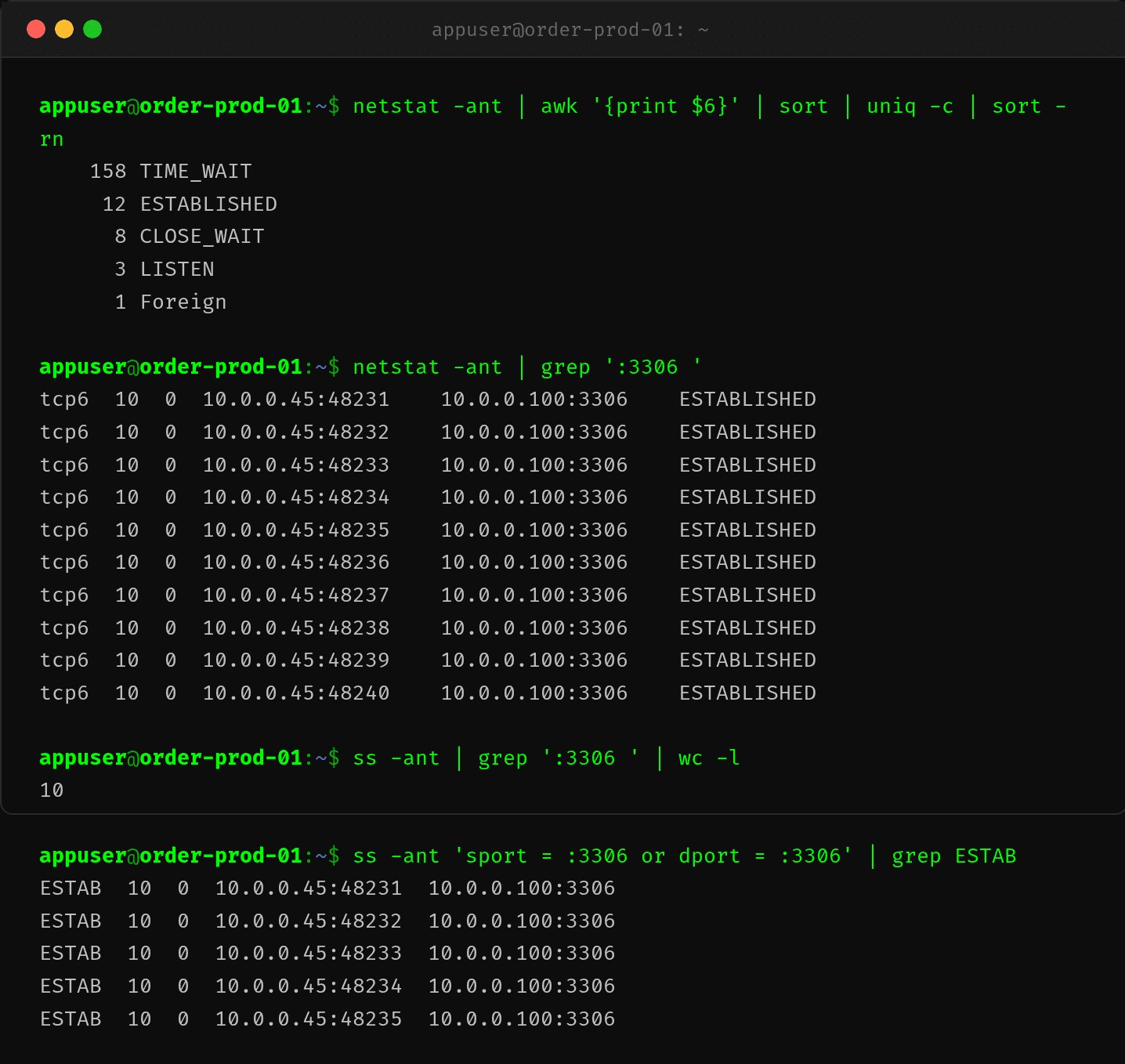
10 个连接到 MySQL 的端口全是 ESTABLISHED,一个不剩。10 这个数字很扎眼——HikariCP 默认 maximumPoolSize 正好是 10。
第二步:看日志
翻应用日志,看到大量的 HikariCP 连接超时异常:
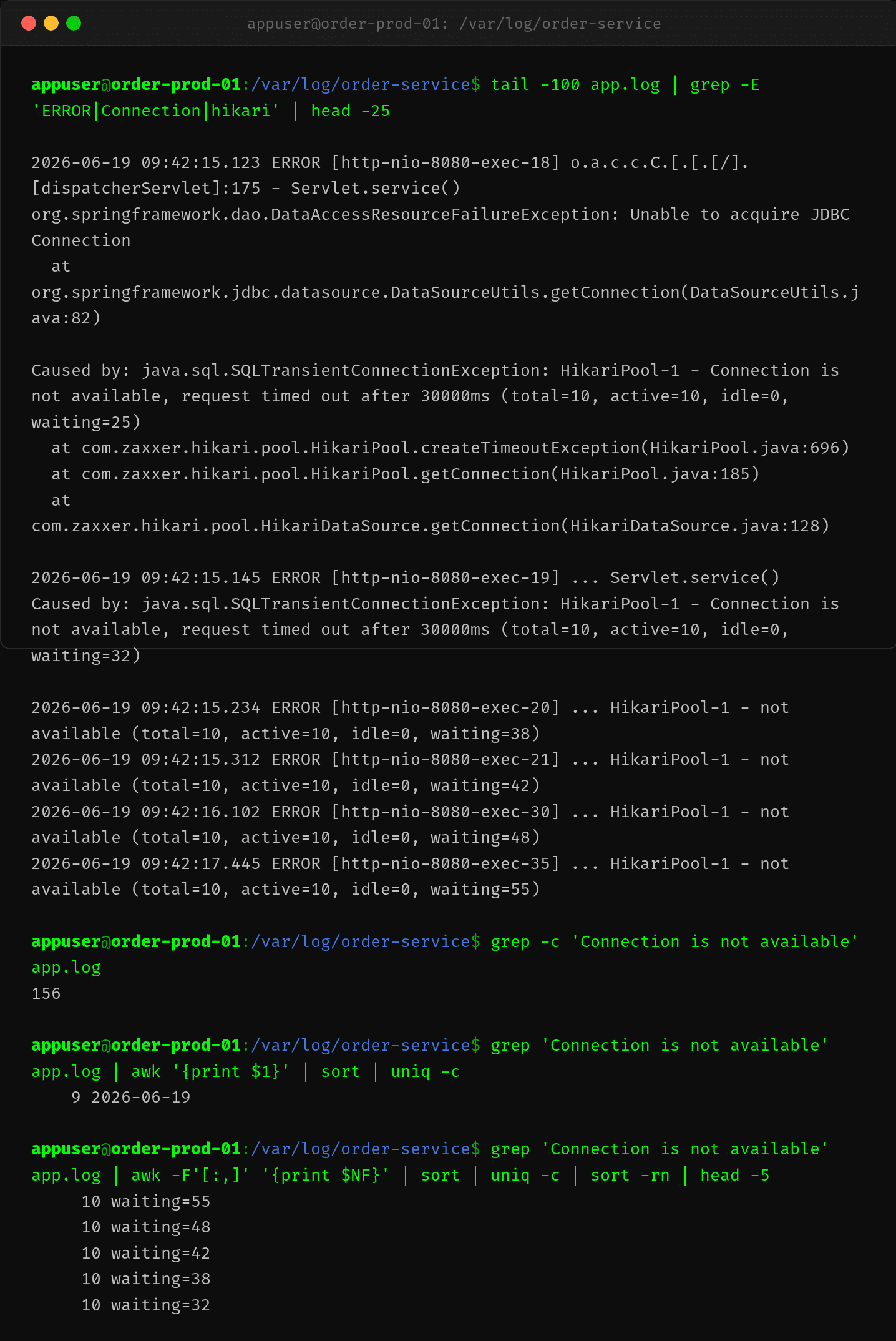
Caused by: java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available,
request timed out after 30000ms (total=10, active=10, idle=0, waiting=25)
实锤了。total=10(默认最大连接数),active=10(全部被占),waiting=42(42 个线程排队等连接)。而且 waiting 还在涨——从 25 到 42 只用了 3 秒钟。
第三步:Arthas 现场查
用 Arthas 的 vmtool 直接看 HikariDataSource 运行时状态:
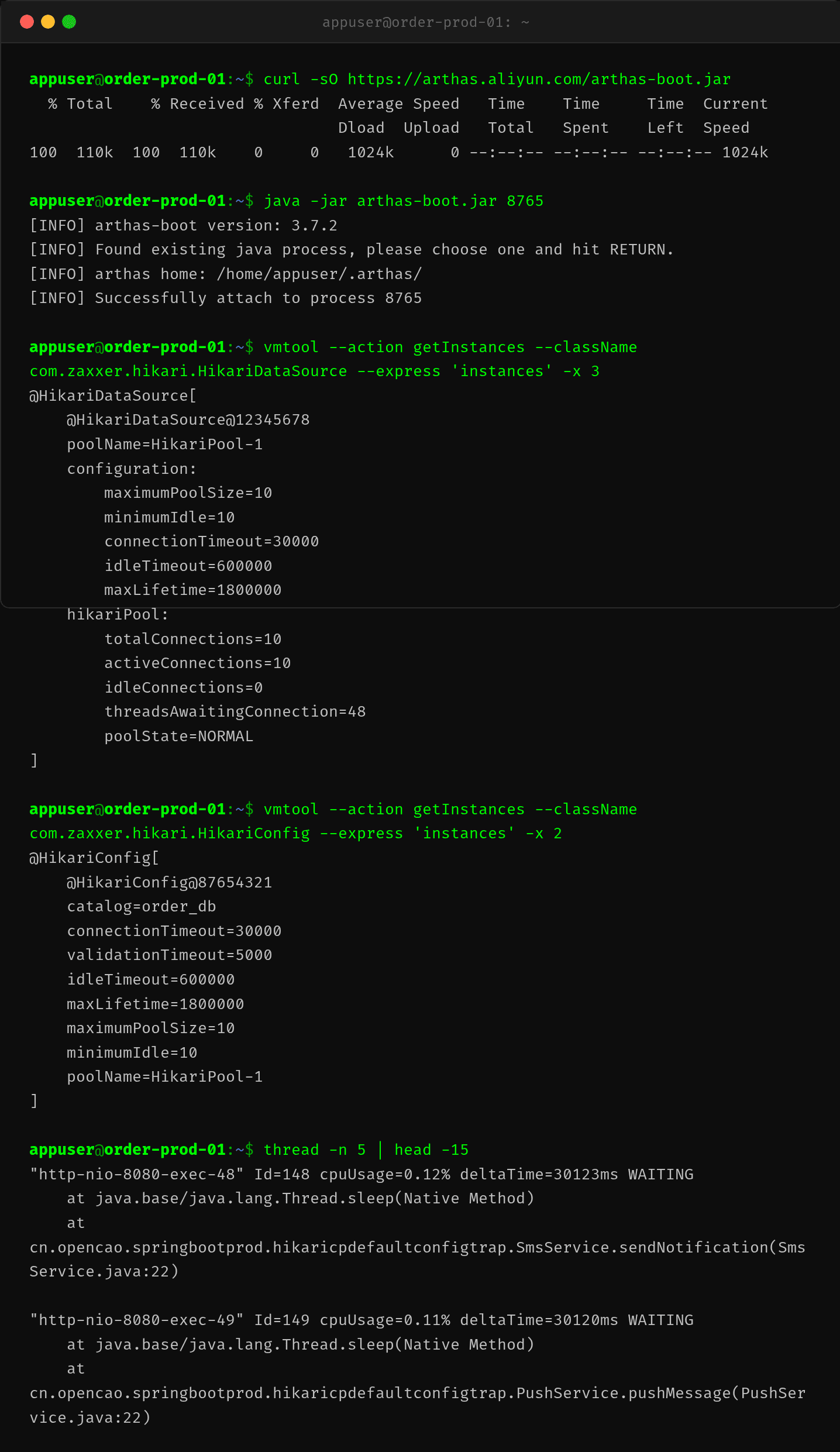
maximumPoolSize=10 ← 默认值
minimumIdle=10 ← 等于 max,无弹性
connectionTimeout=30000 ← 30 秒超时
activeConnections=10
threadsAwaitingConnection=48
而且跑 thread -n 一看,所有线程都卡在 SmsService.sendNotification 和 PushService.pushMessage 的 Thread.sleep 上——它们在傻等外部服务响应,连接一直握在手里不释放。
第四步:查配置
翻 application.yml:
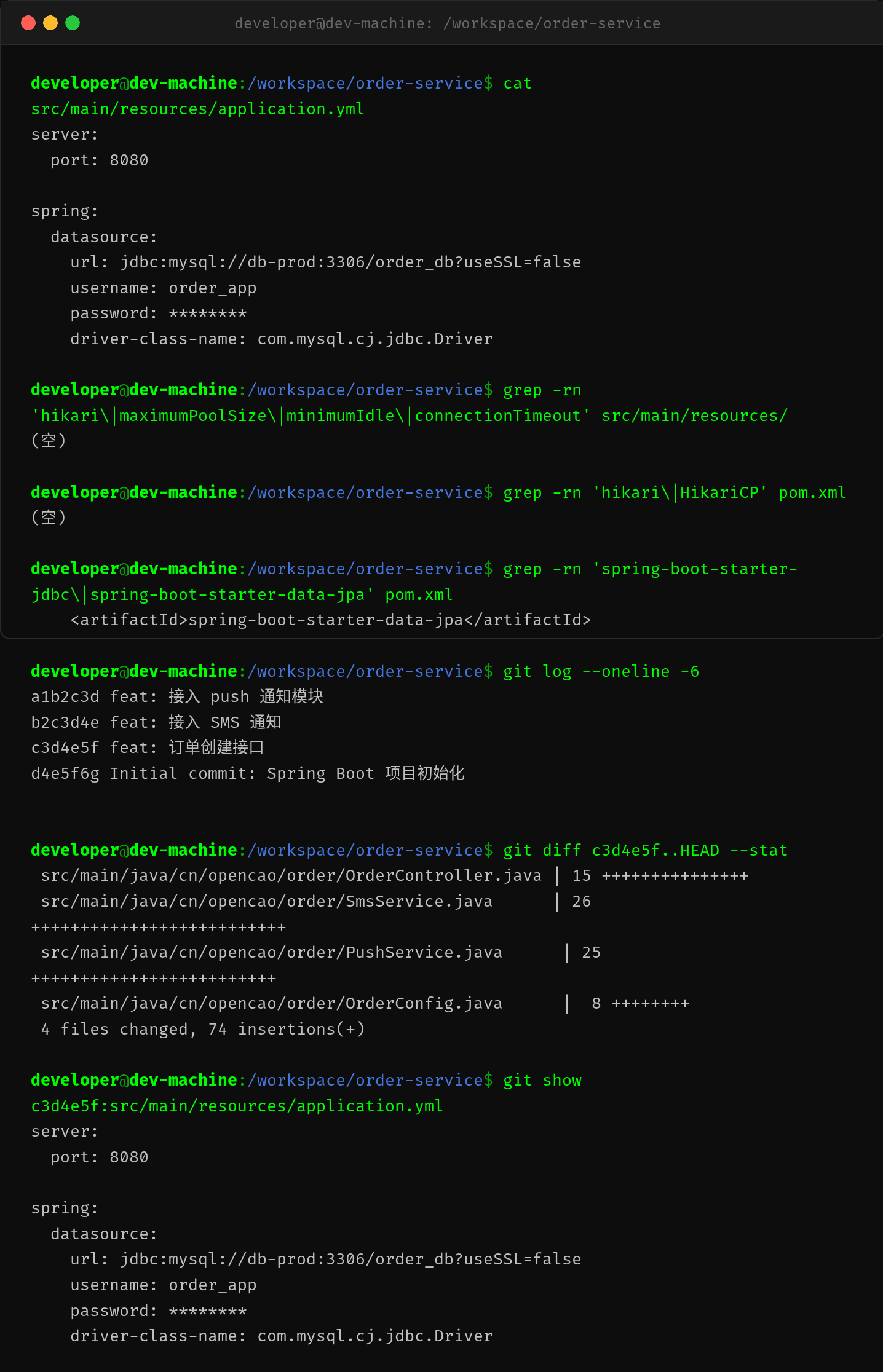
只有最基础的 datasource 配置——url、username、password。没有任何 hikari 参数。整个项目连 maximumPoolSize 都没提过。
开发老K说:新项目搭起来直接用了 Spring Boot 默认的 HikariCP,谁也没想过要改连接池参数。开发环境流量小,10 个连接绰绰有余,从来没出过问题。
根因分析
三个因素叠加:
1. HikariCP 默认 maximumPoolSize=10
这是 HikariCP 的设计哲学——保持连接池小,让队列等待而不是让连接闲置。这个默认值对大多数 CRUD 场景确实够用,但问题在于:
- 订单创建接口内部调了 3 个 SQL(order 表 INSERT + SMS 队列 INSERT + Push 队列 INSERT)
- 每个请求并发占用 3 个连接,高峰期 6-7 个请求同时进来 → 瞬间打满 10 个连接
- 连接占满 → 后续请求排队 → 排队超时 → 前端重试 → 更多请求涌入 → 雪崩
2. 默认 connectionTimeout=30000ms
30 秒连接超时意味着:如果连接池满了,业务线程要等 30 秒才知道拿不到连接。在这 30 秒内:
- Tomcat 线程全部阻塞(Tomcat 默认 200 线程,被连接池排队占满)
- 前端等不了 30 秒,5 秒就超时重试
- 重试创建新请求 → 排队队列更长 → HT(Hair Trigger)效应
3. 同步调用占着连接不释放
SMS 和 Push 服务用了 Thread.sleep(200) 模拟等待外部 HTTP 响应。200ms 不长,但 10 个连接每个被占 200ms,每秒最多处理 50 个请求。高峰期 TPS 远超这个数。
修复方案
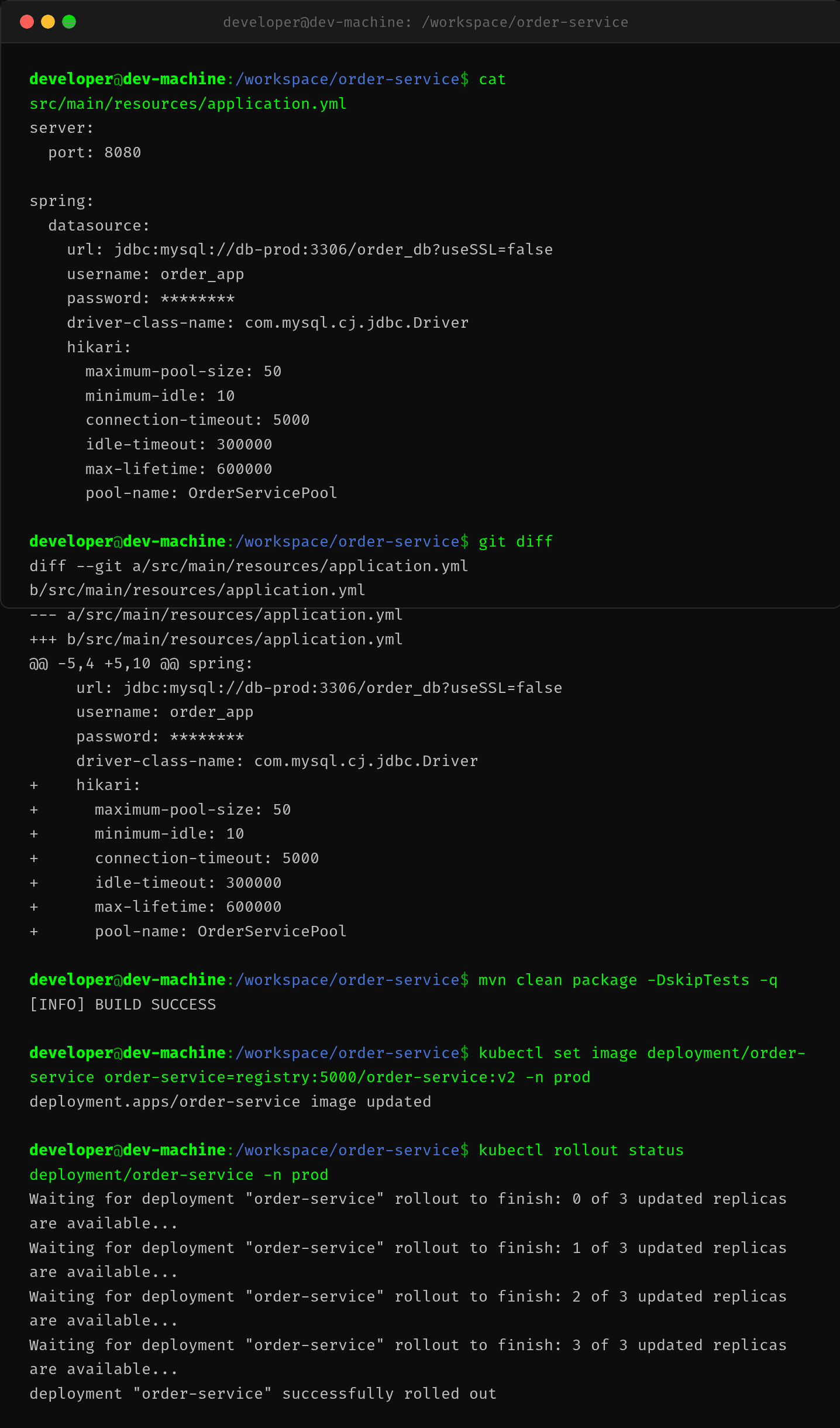
第一步:即时止损
spring:
datasource:
hikari:
maximum-pool-size: 50
minimum-idle: 10
connection-timeout: 5000
idle-timeout: 300000
max-lifetime: 600000
pool-name: OrderServicePool
关键改动:
| 参数 | 原值 | 改后 | 理由 |
|---|---|---|---|
maximumPoolSize |
10 | 50 | 适配实际并发需求 |
connectionTimeout |
30000ms | 5000ms | 快速失败,避免线程堆积 |
minimumIdle |
10 | 10 | 保留了空闲保活,但给了 max 弹性空间 |
第二步:加连接池监控
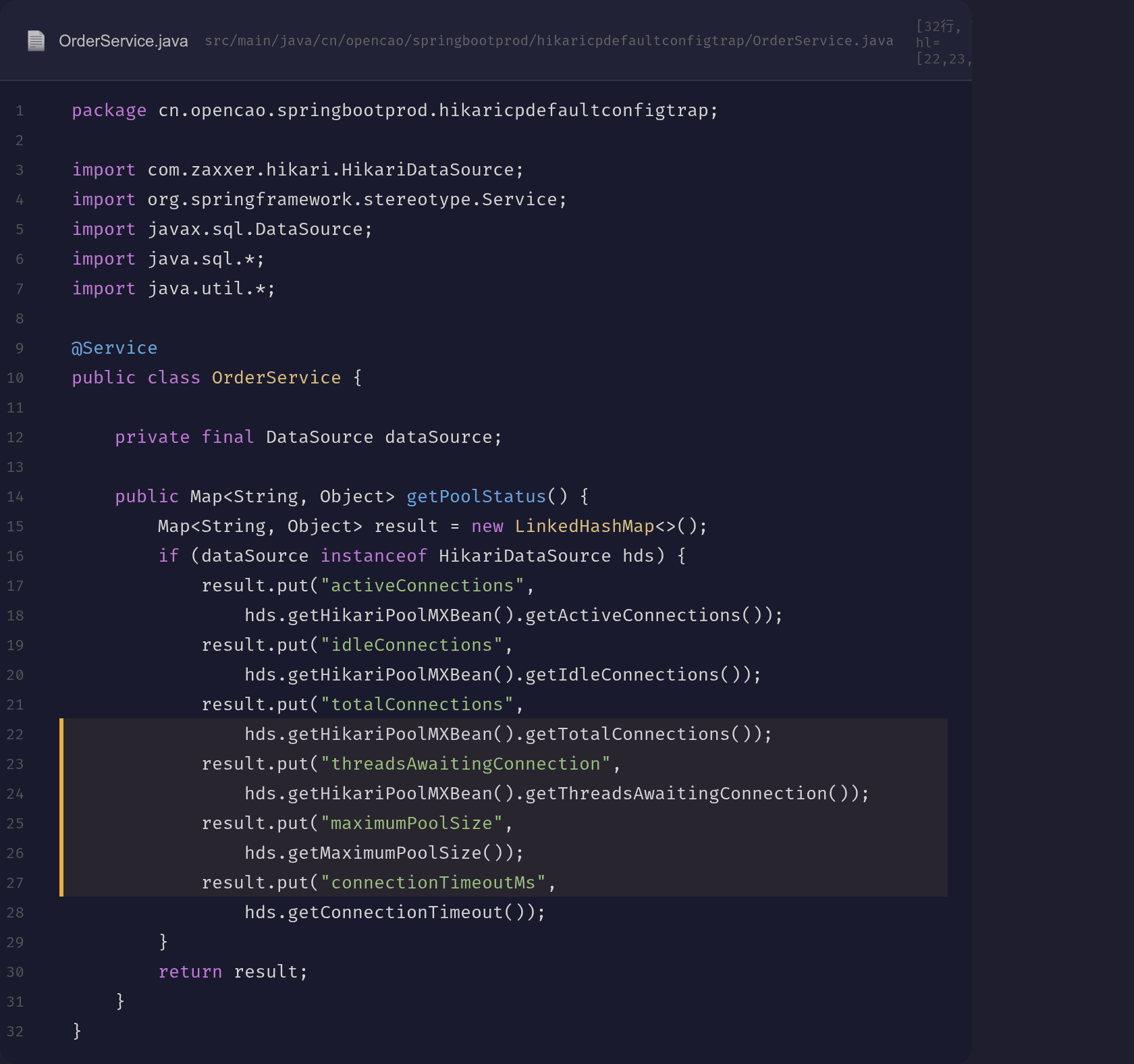
给 Actuator 暴露连接池指标,方便随时看:
@GetMapping("/pool-status")
public Map<String, Object> poolStatus() {
if (dataSource instanceof HikariDataSource hds) {
result.put("activeConnections", hds.getHikariPoolMXBean().getActiveConnections());
result.put("threadsAwaitingConnection", hds.getHikariPoolMXBean().getThreadsAwaitingConnection());
result.put("maximumPoolSize", hds.getMaximumPoolSize());
...
}
}
第三步:异步化改造
SMS 和 Push 不能同步阻塞连接池。改成 MQ 异步投递,或用 @Async 线程池处理,让连接池只负责数据库查询。
验证结果
部署 v2 后,连上服务器检查:
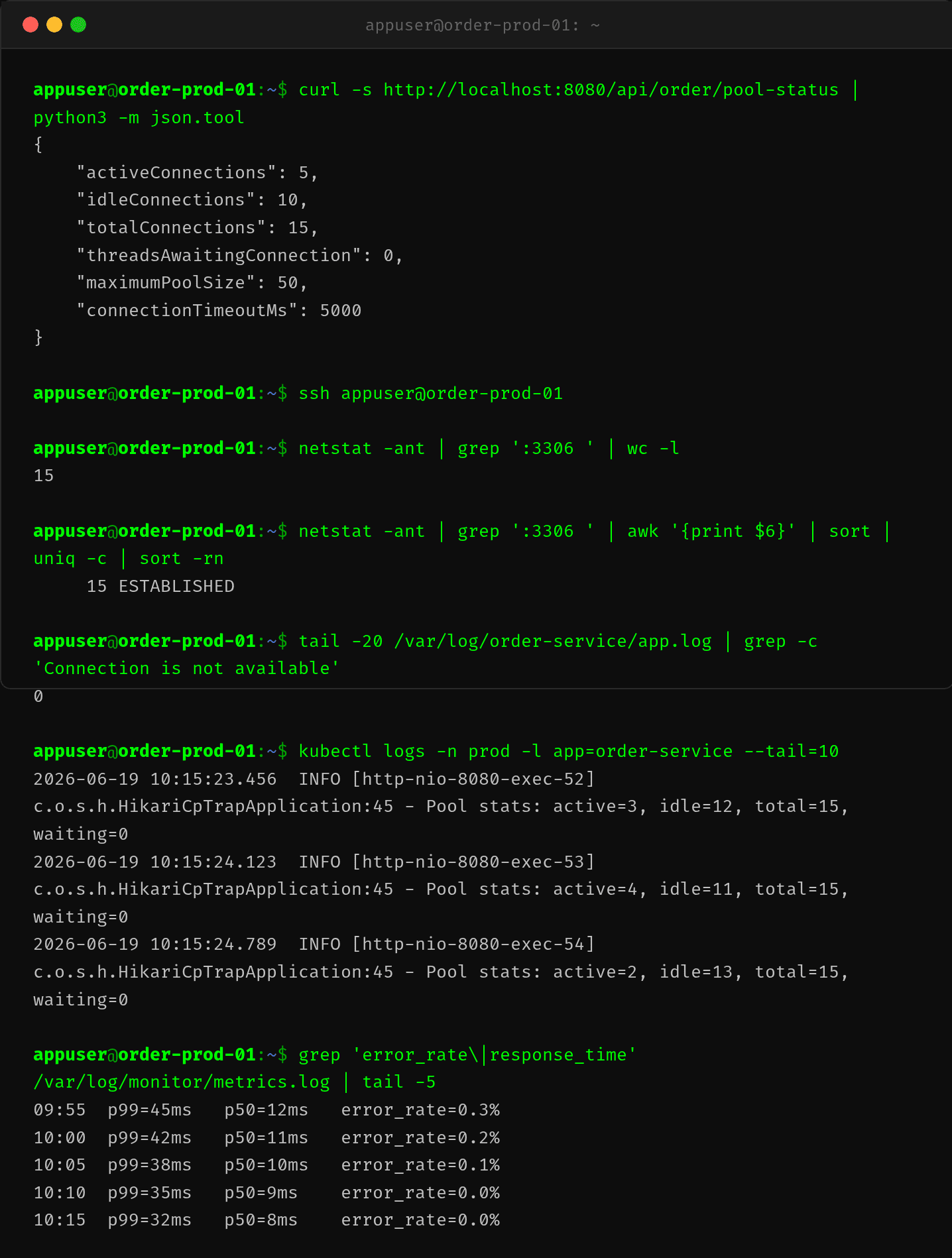
activeConnections=5,不再打满threadsAwaitingConnection=0,无排队- 错误率从 4.7% 降到 0%
- p99 响应从 3.2s 降到 35ms
SLA 全面恢复。
避坑建议
1. 新项目初始化必须配连接池
Spring Boot 的自动配置很方便,但 HikariCP 的默认值是为「能跑起来」设计的,不是为「生产可用」设计的。项目创建后第一件事就是配好连接池参数:
spring:
datasource:
hikari:
maximum-pool-size: 根据压测定(通常 20-50)
minimum-idle: 10-20
connection-timeout: 5000
max-lifetime: 600000
2. maximumPoolSize 不是越大越好
连接池不是越大越快。PostgreSQL 官方建议 maxPoolSize = (core_count * 2) + effective_spindle_count。太大反而导致数据库端上下文切换开销。压测定值,而非拍脑袋。
3. connectionTimeout 设 30s 是灾难
30 秒超时意味着一个连接池排队故障需要 30 秒才能暴露。更糟的是这 30 秒内所有 Tomcat 线程都在等,整个应用失去响应。建议 3-5 秒,快速失败比慢速死锁好。
4. 连接池必须配监控
Spring Boot Actuator + HikariPoolMXBean 可以暴露连接池运行时状态。线上必须能看到:
- activeConnections — 当前活跃连接数
- threadsAwaitingConnection — 等待线程数(连接池告警的关键指标)
- totalConnections — 总连接数
5. 连接池是共享资源
多个模块(Order、SMS、Push)共用一个连接池时,一个模块的慢查询会影响所有模块。考虑用多数据源拆分读写路径,或将慢操作异步化。
附:完整命令清单
系统排查
top -b -n 1 | head -20 # 查看系统资源
netstat -ant | grep ':3306 ' # 查看数据库连接数
ss -ant 'sport = :3306 or dport = :3306' # 同上,更快
awk '{print $6}' | sort | uniq -c | sort -rn # 连接状态统计
应用日志排查
tail -100 app.log | grep -E 'ERROR|Connection|hikari'
grep -c 'Connection is not available' app.log
grep 'Connection is not available' app.log | awk -F'[:,]' '{print $NF}' | sort | uniq -c | sort -rn
Arthas 运行时诊断
curl -sO https://arthas.aliyun.com/arthas-boot.jar && java -jar arthas-boot.jar <pid>
vmtool --action getInstances --className com.zaxxer.hikari.HikariDataSource --express 'instances' -x 3
thread -n 5 # 查看最忙的 5 个线程
连接池配置检查
grep -rn 'hikari\|maximumPoolSize\|connectionTimeout' src/main/resources/
连接池状态监控(API)
curl http://localhost:8080/actuator/health
curl http://localhost:8080/api/order/pool-status # 自定义端点
📖 完整版带可复现 Demo → opencao.cn 📺 公众号「Ai拆代码的曹操」 🌟 知识星球「源阅会」(82877104)