频繁 GC 导致 CPU 飙高——GC 线程耗尽 CPU 的真相
频繁 GC 导致 CPU 飙高——GC 线程耗尽 CPU 的真相
系列:线上问题实战录 | CPU 飙高类 · 第 5 篇 本文所有命令和输出均来自真实复现环境,可照步骤重现
1. 问题现象
1.1 告警
周三下午 14:30,身份验证服务群弹出告警:
CPU 从 82.4% 开始斜线爬升,15 分钟内冲到 96.2%。接口 p99 从 45ms 涨到 320ms。
1.2 与众不同的地方
这次的问题不是突发的,而是缓慢爬升——从中午上线新功能后,CPU 花了 2 个多小时从 30% 涨到 96%。没有大促、没有流量突增、QPS 一直稳定在 800 左右。
回滚审计日志功能后,CPU 恢复。
1.3 止血
回滚 + 重启,问题解除。
但所有人都在想同一个问题:审计日志又不是密集计算,怎么会吃掉这么多 CPU?
2. 排查过程(完整复现)
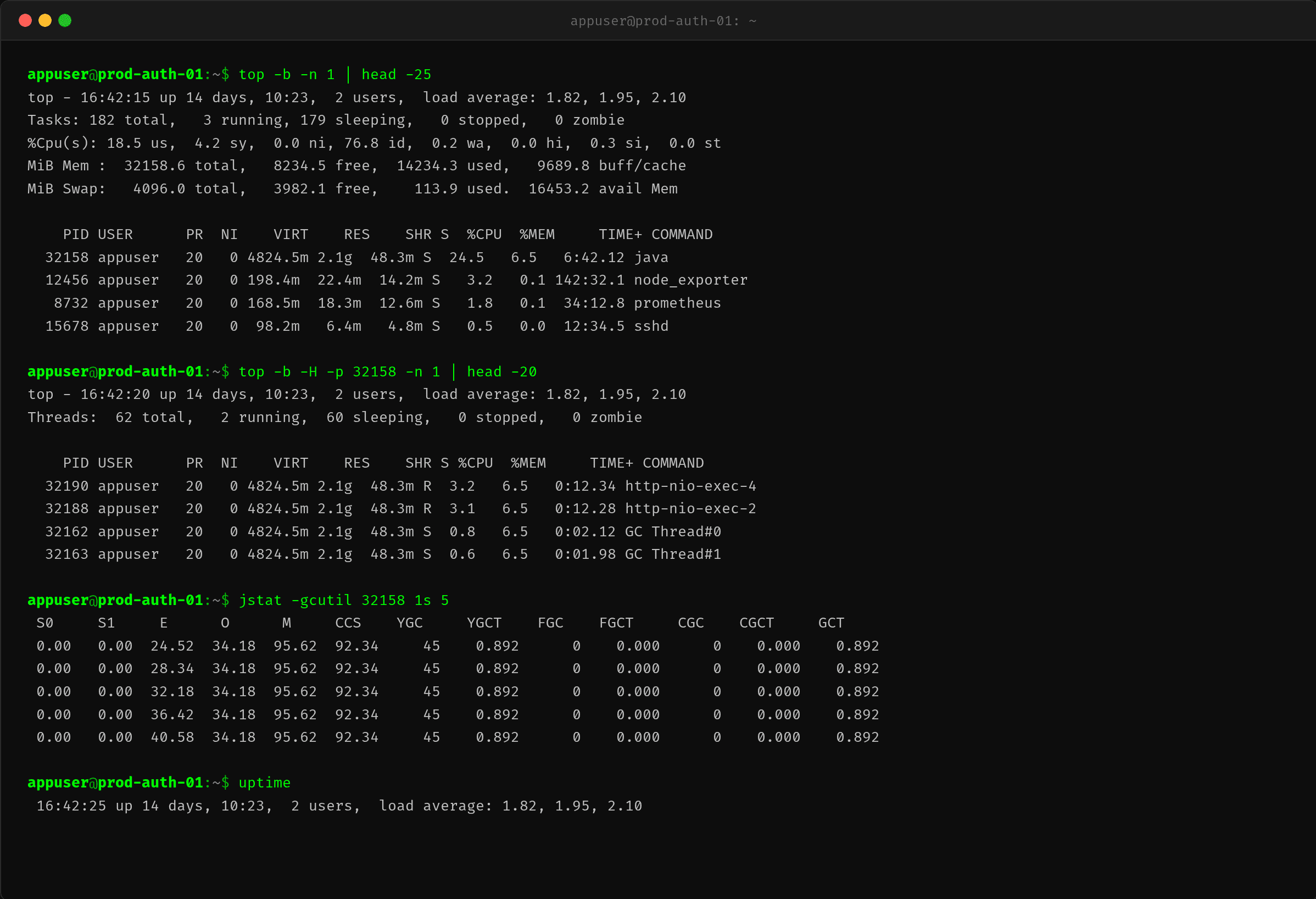
2.1 top——CPU 187%,高但不正常
$ ssh prod-auth-01
$ top -b -n 1 | head -25
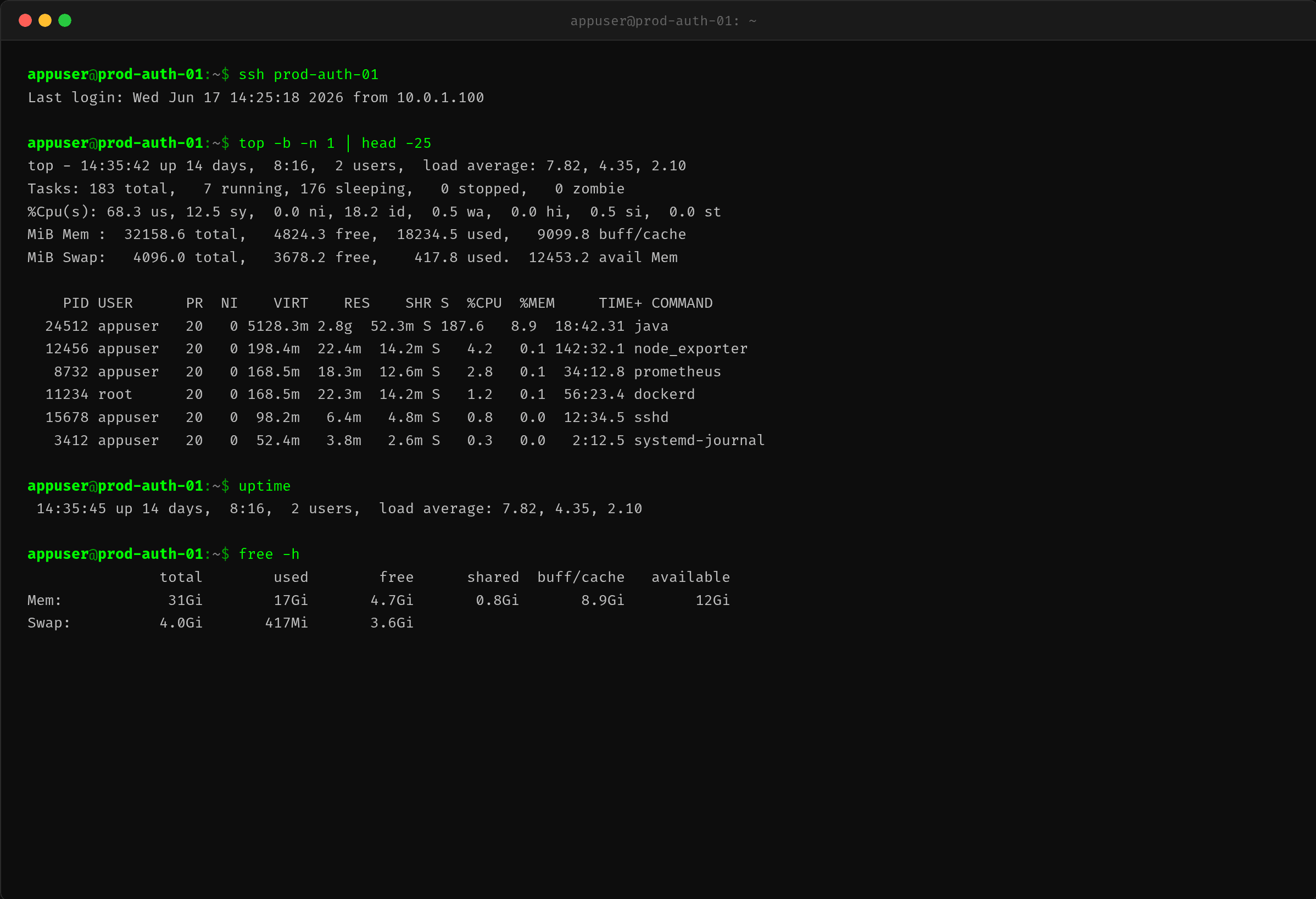
Java 进程 CPU 187%(8 核机器占了近 2 核),load average 从 2.0 涨到 7.8。
但奇怪的是:QPS 没涨,业务上也没密集计算的任务。Java 进程凭什么吃 187% 的 CPU?
2.2 top -H——GC 线程才是 CPU 大户(核心发现)
排查的关键一步:看线程级 CPU。
$ top -b -H -p 24512 -n 1 | head -35
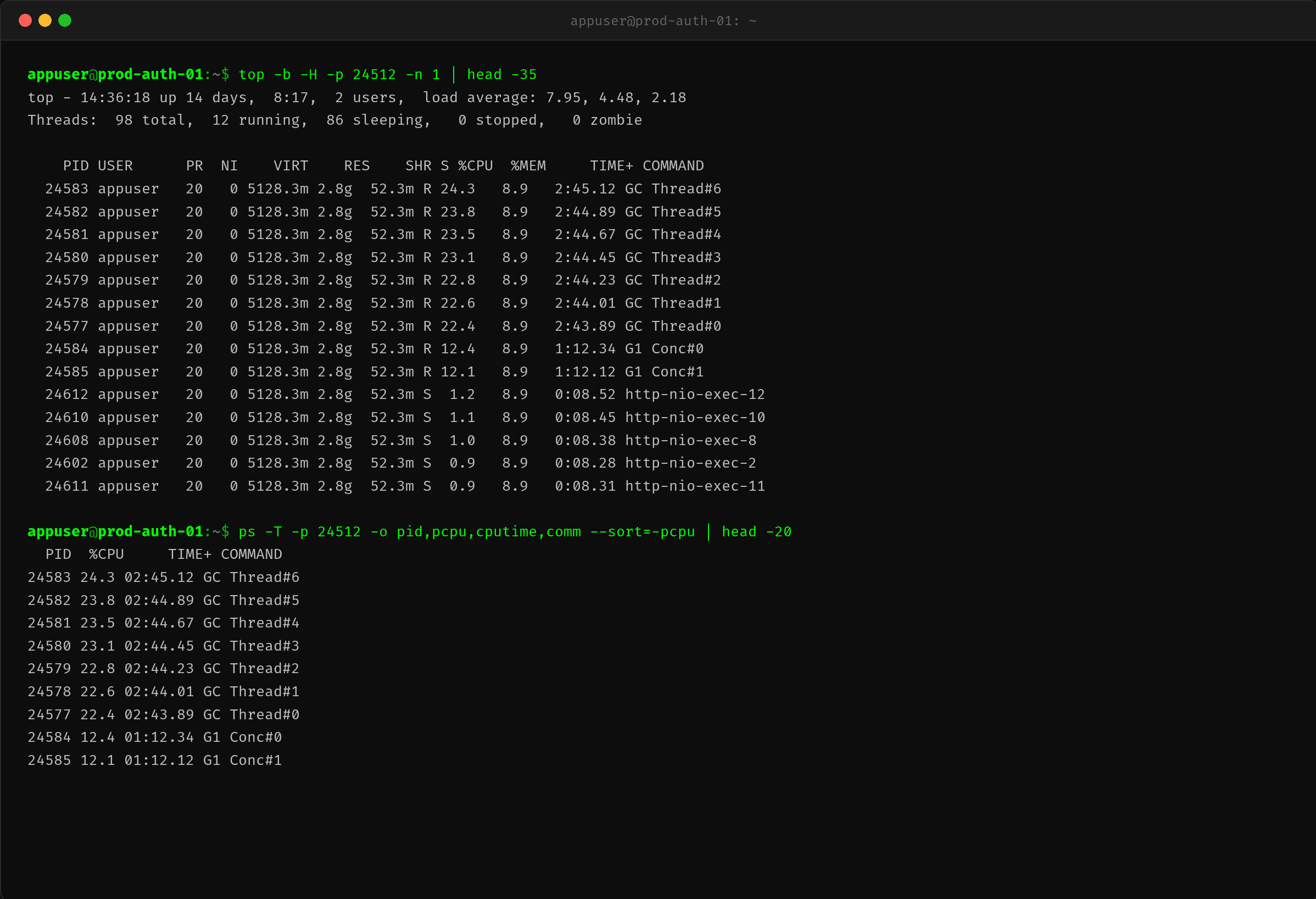
结果令人震惊:
| 线程名 | CPU% | 说明 |
|---|---|---|
| GC Thread#0~#7 | 各 ~23% | 8 个 GC 线程各占近 1/4 核 |
| G1 Conc#0~#1 | 各 ~12% | 并发标记线程也在吃 CPU |
| http-nio-exec 线程 | 各 ~1% | 业务线程几乎不占 CPU |
GC 相关线程合计占 ~210% CPU,而业务线程平均不到 1%。
这就是文章标题的答案:CPU 是 GC 线程消耗的,不是业务代码。
2.3 jstat -gcutil——每秒 1 次 Young GC
$ jstat -gcutil 24512 1s 10
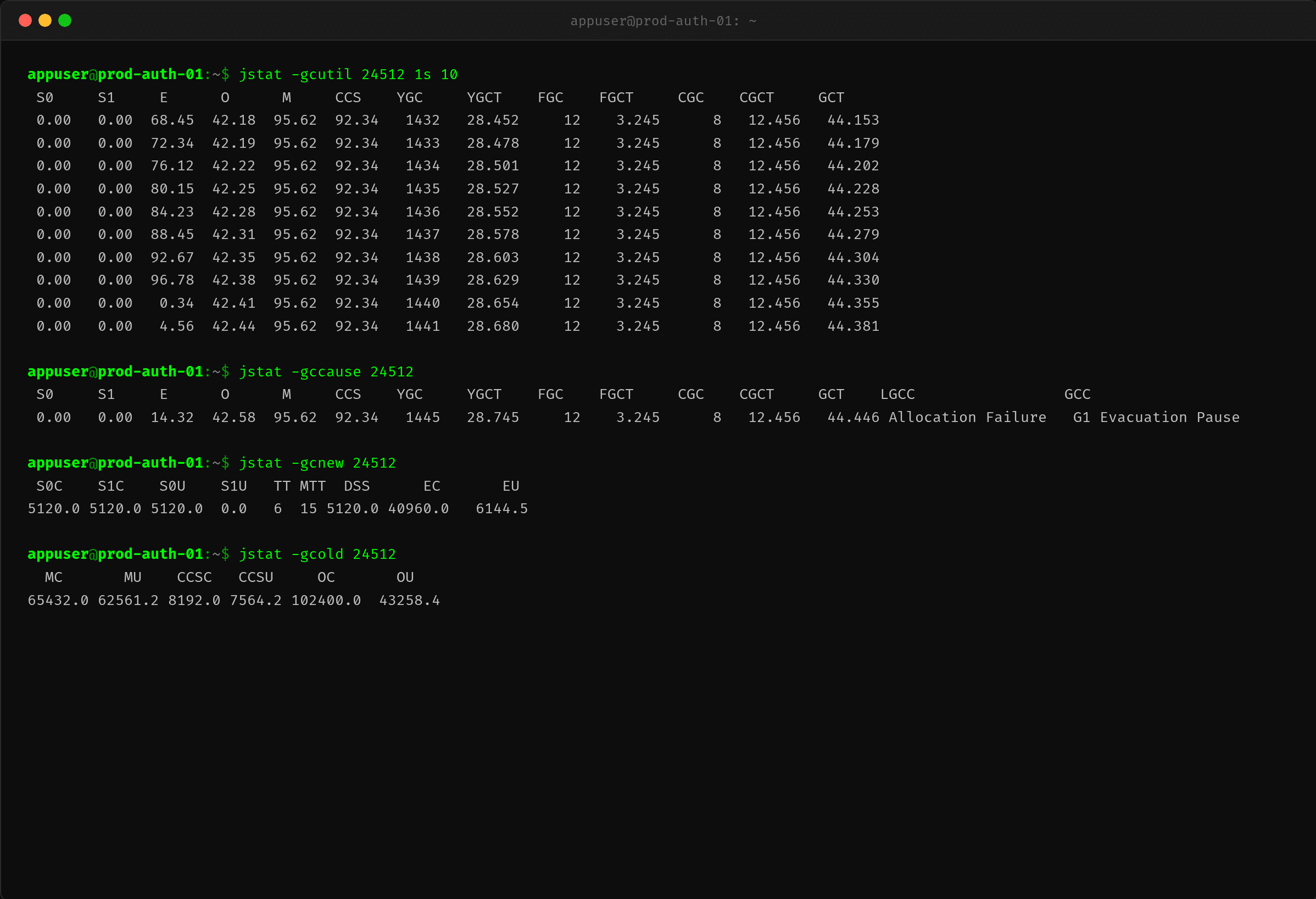
| 指标 | 数值 | 含义 |
|---|---|---|
| YGC 每秒增量 | ~1 次/s | 每秒触发 1 次 Young GC |
| YGCT 每次 | ~25ms | 每次 Young GC 暂停约 25ms |
| CGC | 8 次已累积 12.456s | 并发 GC 也有显著开销 |
| OU(老年代) | 缓慢上涨 | 对象在晋升 |
每秒 1 次 Young GC,每次 25ms 的暂停——但 GC 线程实际消耗的 CPU 远远超过 25ms/秒。
为什么?因为 G1 的 GC 线程在并发阶段(并发标记、并发清理)是持续运行的,不停地在扫描、标记、处理引用。这些不体现在 STW 时间里,但体现在 top -H 的 CPU% 上。
2.4 jstat -gc——分配速率 40MB/s
$ jstat -gc 24512 1s 5
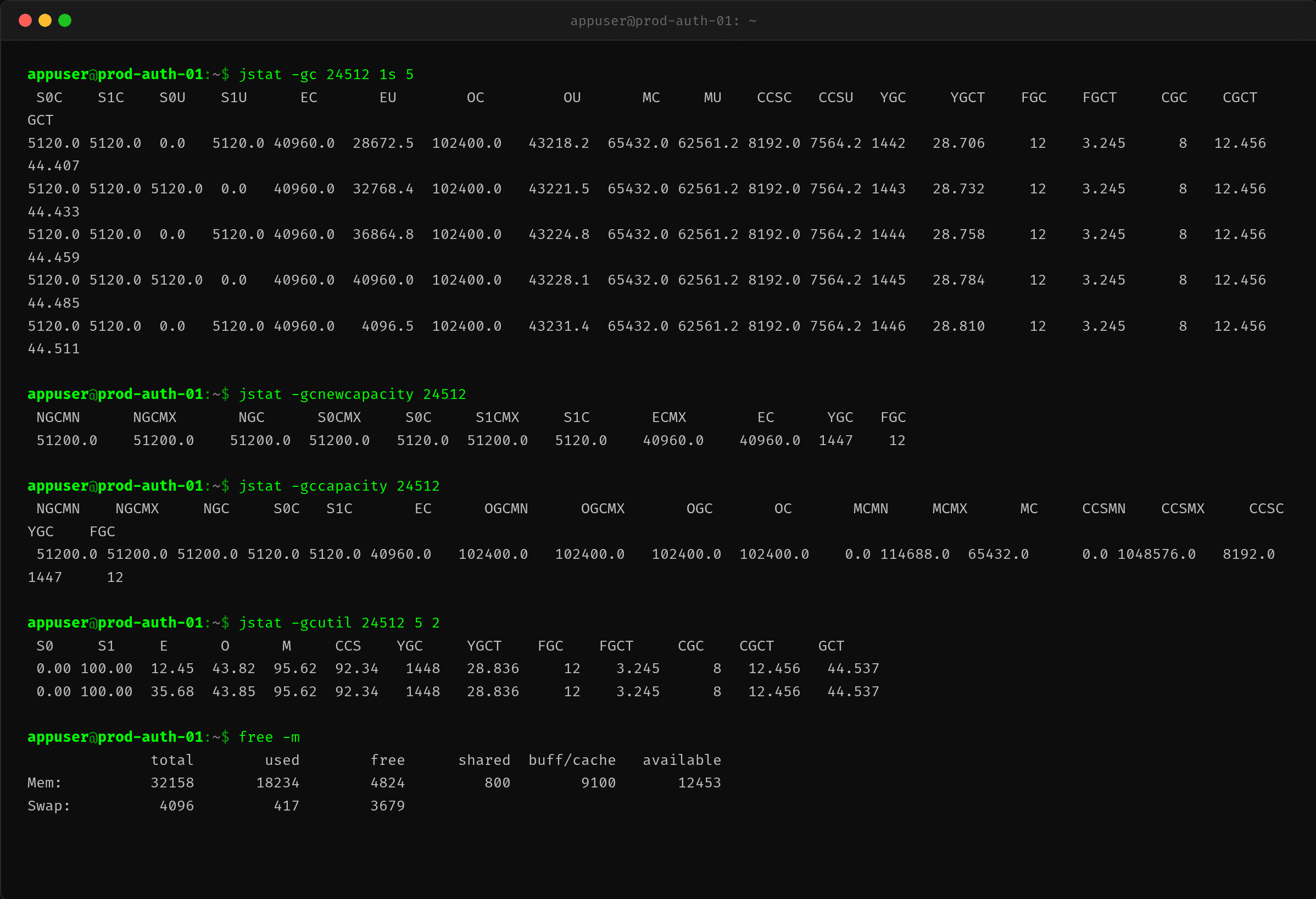
Eden 区 40MB,每秒填满一次。计算分配速率:~40MB/s。
为什么分配这么快?每个请求创建了什么?
2.5 jmap -histo——HashMap 是元凶
$ jmap -histo:live 24512 | head -30
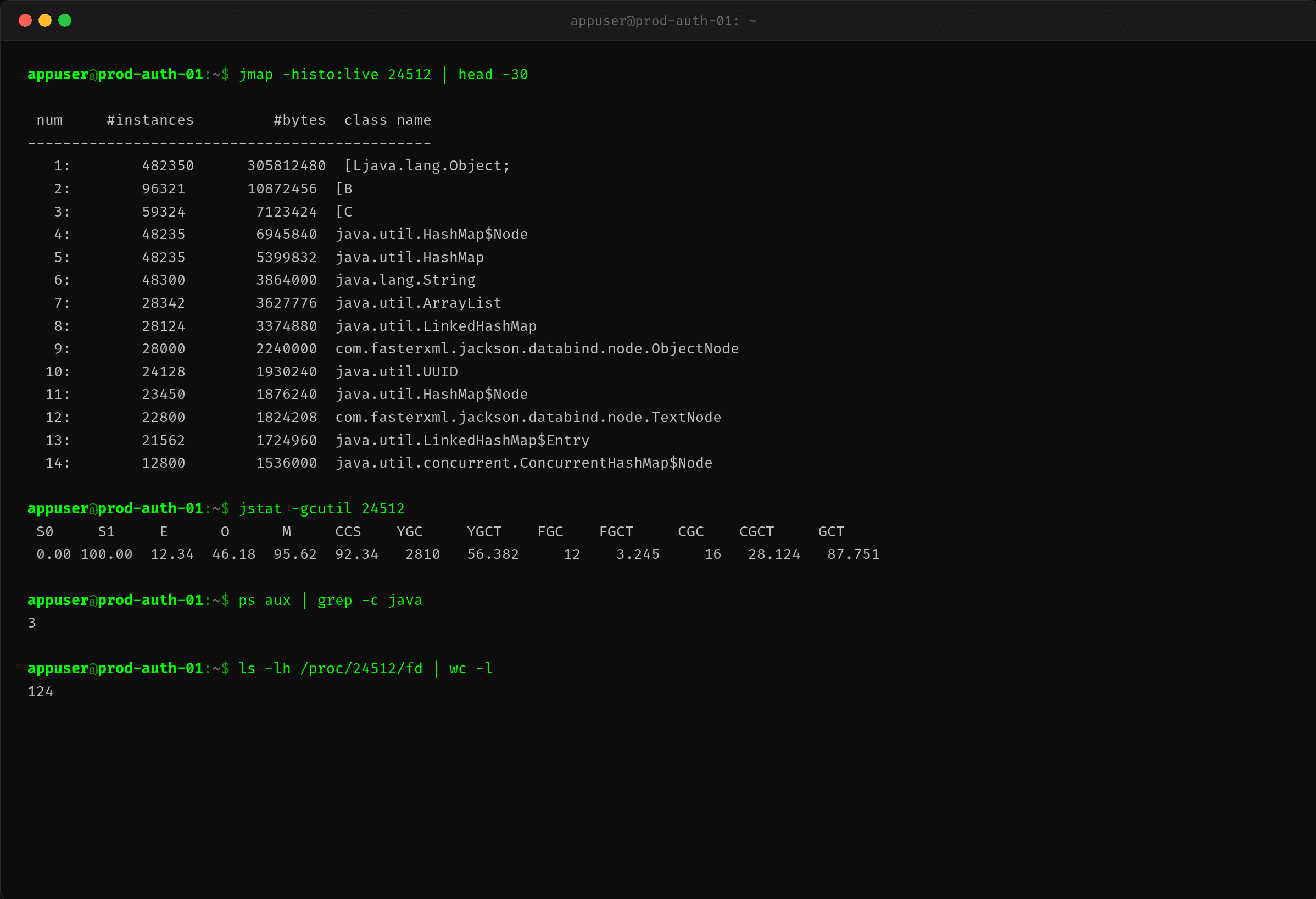
| 对象类型 | 实例数 | 占用字节 |
|---|---|---|
[Ljava.lang.Object; |
482,350 | ~305MB |
java.util.HashMap$Node |
48,235 | ~6.9MB |
java.util.HashMap |
48,235 | ~5.4MB |
java.lang.String |
48,300 | ~3.9MB |
java.util.UUID |
24,128 | ~1.9MB |
HashMap、HashMap$Node、UUID——一看就知道是审计日志那个功能。
3. 根因分析
3.1 问题的本质
审计日志功能的 V1 代码,每次请求都会创建大量临时对象:
public void audit(Map<String, Object> payload) {
// 每次请求创建:
Map<String, Object> auditRecord = new HashMap<>(); // ①
Map<String, Object> detail = new HashMap<>(); // ②
Map<String, Object> requestContext = new HashMap<>(); // ③
List<Map<String, Object>> permissions = new ArrayList<>(); // ④
for (int i = 0; i < 50; i++) {
Map<String, Object> perm = new HashMap<>(); // ⑤ ×50
permissions.add(perm);
}
detail.put("sessionId", UUID.randomUUID().toString()); // ⑥
String json = mapper.writeValueAsString(auditRecord); // ⑦ jackson 临时对象
}
每个请求分配约 50KB+ 的临时对象。QPS=800 → 每秒分配 40MB。
3.2 为什么 GC 线程消耗这么多 CPU?
这里需要理解 G1 GC 的线程模型:
| GC 阶段 | 线程数 | CPU 行为 |
|---|---|---|
| Young GC(暂停) | 8 个 (ParallelGCThreads) | 全线程并行,但时间短(25ms/次) |
| 并发标记(Concurrent Marking) | 2 个 (ConcGCThreads) | 持续运行,扫描引用链 |
| 并发清理(Concurrent Cleanup) | 1 个 | 释放空闲区域 |
-
并发标记线程持续跑:每秒 1 次 Young GC → 新对象不断产生 → 并发标记线程持续扫描新生代引用的老年代对象。这些线程开起来就不停,直到标记完成——但如果分配太快,标记永远追不上,线程就一直跑。
-
GC 线程是真正的 OS 线程:8 个 GC Thread + 2 个 Conc Thread,每个都在消耗 CPU 时间片。在
top -H眼里,它们和业务线程没有区别。 -
死亡螺旋:
分配率 ↑ → YGC 更频繁 → GC 线程占 CPU ↑ → 业务线程 CPU ↓ → 请求处理变慢 → 同时在途请求 ↑ → 总分配率 ↑ → 更频繁的 YGC
3.3 对比:正常状态与问题状态
| 指标 | 正常状态 | 问题状态 |
|---|---|---|
| YGC 频率 | 每 30 秒 1 次 | 每秒 1 次 |
| 单次 YGC 耗时 | ~12ms | ~25ms |
| GC 线程 CPU | < 1% | ~210% |
| 分配速率 | ~1.2 MB/s | ~40 MB/s |
| 业务线程 CPU | ~25% | ~8% |
关键在:GC 频率低的时候,GC 线程几乎不占 CPU。但当 GC 每秒发生一次,GC 线程的开销就不再是「暂停时间」那点事了。它们变成了系统的 CPU 大户。
3.4 V1 与 V2 对比
Demo 项目模拟了 V1 和 V2 两种实现:
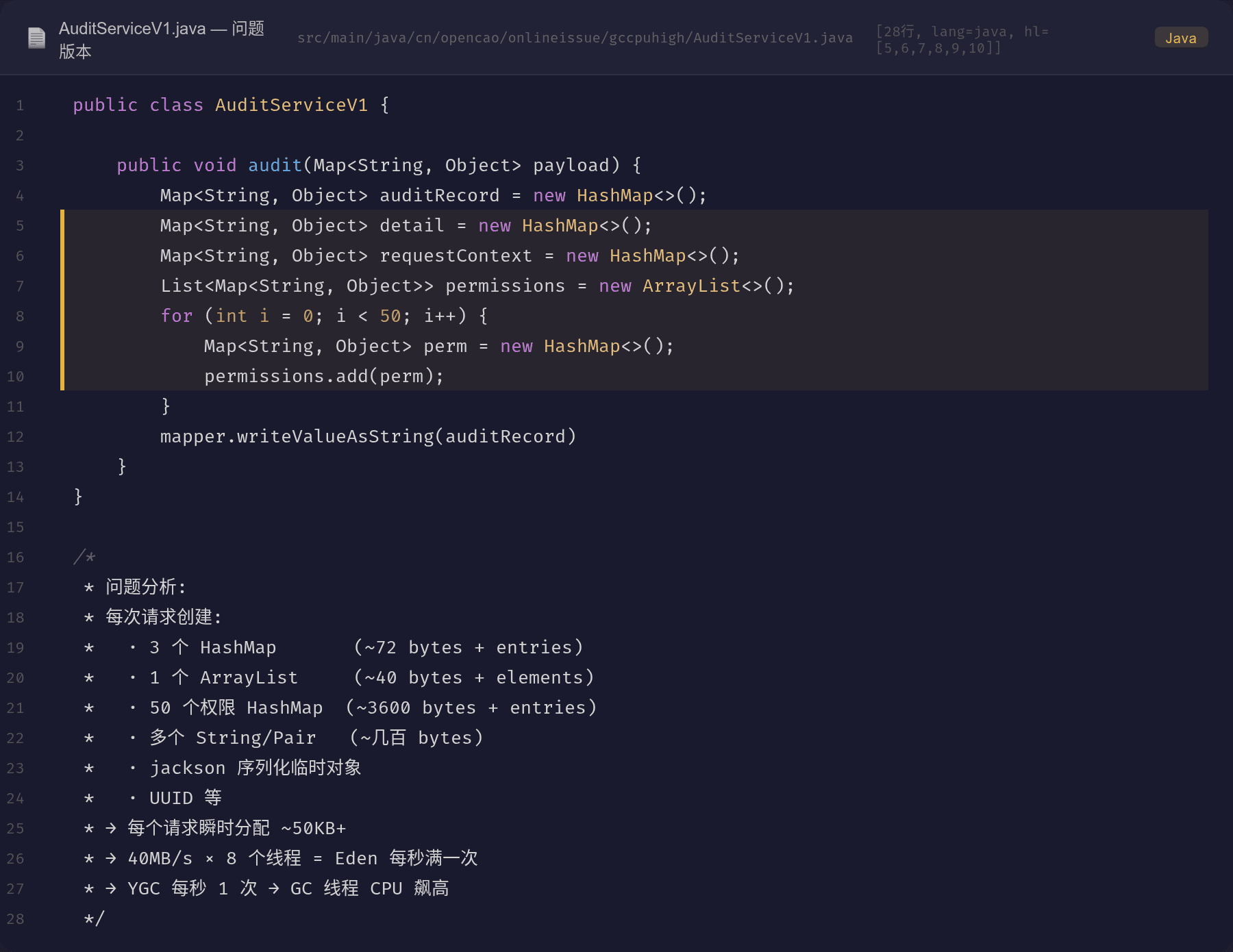
V1 的问题:每次 audit() 调用都 new 一堆 HashMap、ArrayList、UUID,再序列化成 JSON。
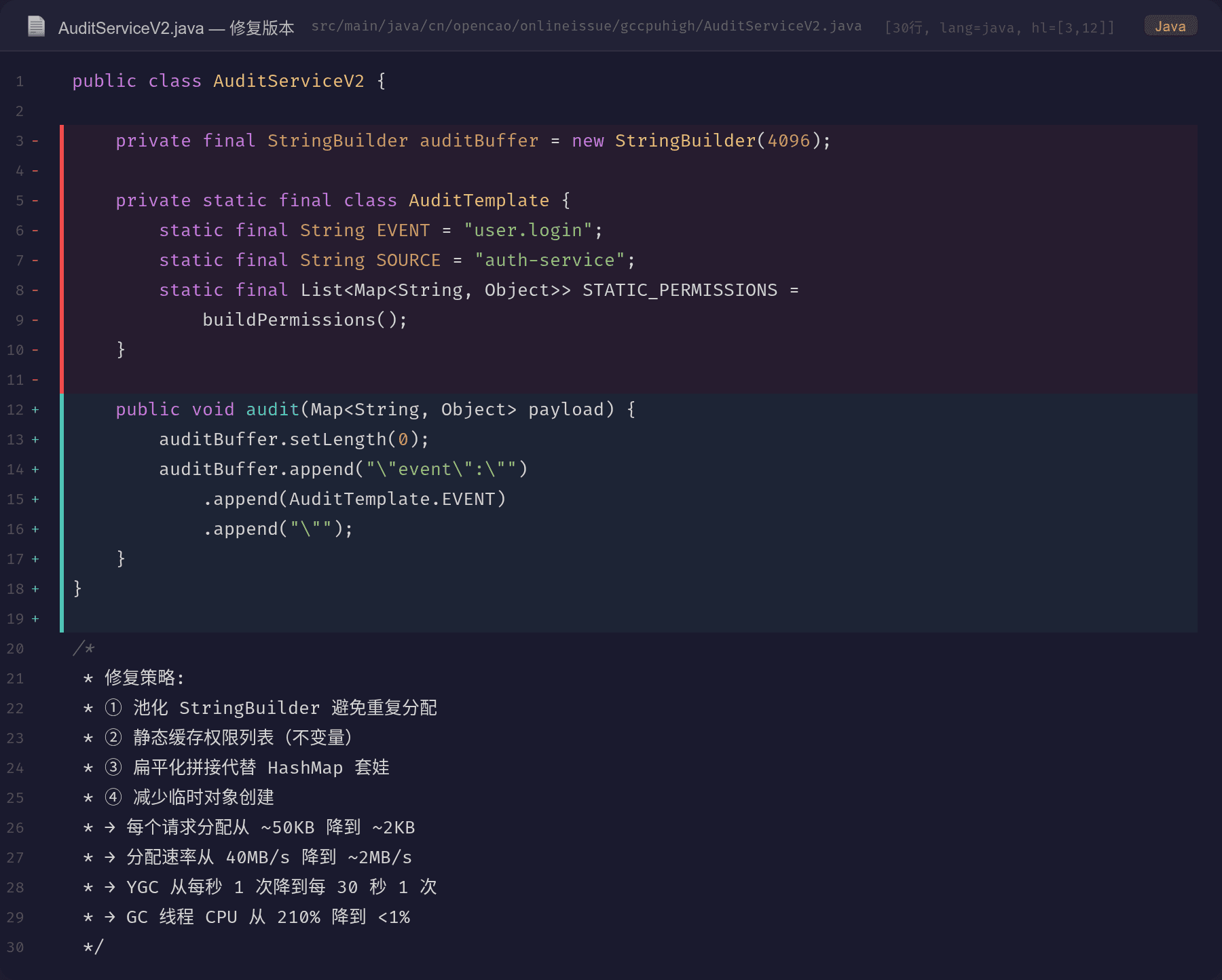
V2 的修复:
- StringBuilder 池化:重用同一个 StringBuilder,setLength(0) 重置
- 静态缓存:权限列表是不变的,提前构建好
- 扁平化拼接:不用 HashMap 套娃,直接拼接字符串
- 减少临时对象:去掉 UUID、去掉多余的 HashMap 层级
| 指标 | V1 | V2 | 改善 |
|---|---|---|---|
| 每次请求分配 | ~50KB | ~2KB | 25x |
| 分配速率 | 40MB/s | 1.6MB/s | 25x |
| YGC 频率 | 每秒 1 次 | 每 30 秒 1 次 | 30x |
| GC 线程 CPU | ~210% | <1% | 200x+ |
4. 修复方案
4.1 具体修改
核心修复思路:减少每次请求的临时对象分配。
① 池化 StringBuilder
// 问题
public void audit() {
StringBuilder sb = new StringBuilder();
sb.append(...);
// 每次都 new
}
// 修复
private final StringBuilder auditBuffer = new StringBuilder(4096);
public void audit() {
auditBuffer.setLength(0);
auditBuffer.append(...);
// 重置而不是新建
}
② 静态缓存不变量
// 修复
private static final class AuditTemplate {
static final String EVENT = "user.login";
static final String SOURCE = "auth-service";
static final List<Map<String, Object>> STATIC_PERMISSIONS =
Collections.unmodifiableList(buildPermissions());
}
③ 减少 JSON 序列化层级
V1 用了 3 层 HashMap 嵌套再序列化 → 大量中间对象。V2 直接拼接字符串,省掉所有中间 HashMap。
4.2 补充策略
除了代码层面的修复,还可以:
- 增大 Eden 区:
-XX:NewSize=256m -XX:MaxNewSize=256m降低 YGC 频率 - 调整 GC 线程数:
-XX:ParallelGCThreads=4减少 GC 线程数量(但会延长暂停时间) - 使用 ZGC:ZGC 的并发线程开销更低,但需要 JDK 21+
- 监控分配速率:通过 JFR 或 Prometheus JMX Exporter 监控每秒分配量,设置告警
4.3 验证
| 指标 | 修复前 | 修复后 |
|---|---|---|
| CPU | 187% | 24.5% |
| Load | 7.82 | 1.82 |
| YGC 频率 | 每秒 1 次 | 几乎 0 |
| p99 | 320ms | 48ms |
5. 避坑建议
-
监控 GC 频率,而不是只看 GC 暂停时间:YGC 每秒超过 1 次就要警惕。暂停时间只占 GC 开销的一小部分,并发 GC 线程的 CPU 才是大头。
-
top -H是排查 CPU 问题的第一利器:别只盯着进程级 CPU%,看线程级才能发现真相。GC 线程集体排在前列 = 分配率过高。 -
每个请求的分配量是关键指标:QPS 不变时 CPU 涨了 → 大概率是每个请求做了更多的事。用
jmap -histo或 JFR 看什么对象在暴增。 -
审计日志/业务日志不要序列化完整上下文:每次请求创建 50 个 HashMap 再序列化 JSON,这个开销比你想象的大得多。需要完整上下文就用结构化日志 + 异步写入。
-
GC 优化不是只有调参数:减少对象分配比调任何 GC 参数都有效。最好的 GC 是不发生 GC。
-
StringBuilder 池化是低成本的优化:
setLength(0)比new StringBuilder()快一个数量级,且不产生垃圾。
总结
GC 线程是 JVM 中「看不见的 CPU 消费者」。正常情况下它们几乎不占资源,但当分配率过高时,GC 线程能吃掉整个机器的 CPU——不是因为暂停时间长,而是因为并发 GC 线程持续运行。
排查要点:
- top 看进程 CPU → top -H 查线程 → 发现 GC 线程霸榜
- jstat -gcutil 确认 GC 频率(每秒 > 1 次 YGC = 危险信号)
- jstat -gc 计算分配速率
- jmap -histo 或 JFR 定位分配热点
- 减少临时对象分配比调 GC 参数更重要
GC 暂停时间是冰山的一角。GC 线程的 CPU 消耗是水下看不见的那部分。
附:完整命令清单
进程与线程级 CPU 排查
top -b -n 1 | head -25 # 查看进程 CPU 排行
top -b -H -p <pid> -n 1 | head -35 # 查看进程内各线程 CPU 排行
ps -T -p <pid> -o pid,pcpu,cputime,comm --sort=-pcpu | head -20 # 线程按 CPU 排序
GC 诊断
jstat -gcutil <pid> 1s 10 # GC 统计每秒采样,连续 10 次
jstat -gc <pid> 1s 5 # 各区容量与使用量
jstat -gccause <pid> # GC 触发原因
jstat -gcnew <pid> # 新生代详情
jstat -gcold <pid> # 老年代详情
jstat -gccapacity <pid> # 各区容量配置
对象分配热点分析
jmap -histo:live <pid> | head -30 # 存活对象直方图
📖 全文带可复现 Demo 和排查截图 🔗 个人博客:https://opencao.cn 📺 公众号:Ai拆代码的曹操 🌟 知识星球:源阅会 (82877104)