容器 CPU Throttling:受限 CPU 下的性能抖动
容器 CPU Throttling:受限 CPU 下的性能抖动
本文是线上问题实战录系列的第 12 篇 叙事框架:
现象 → 排查过程 → 根因 → 修复 → 预防
问题现象
某日早高峰,支付服务的告警突然响起——接口 P99 从正常的 50ms 飙到 823ms,大量用户反馈支付超时。
告警群消息如下:
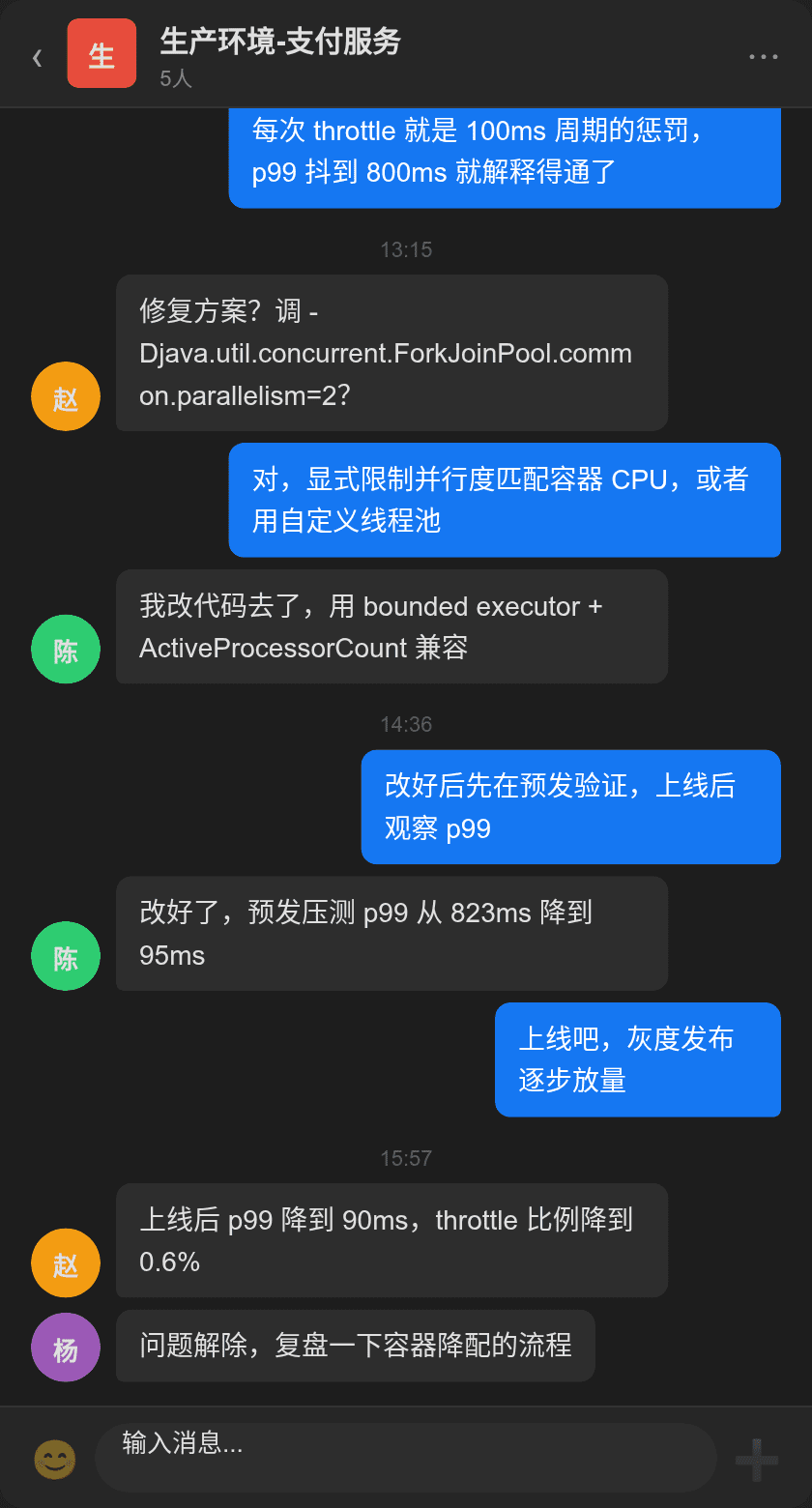
第一直觉是流量上涨。但打开监控一看,QPS 没变,和昨天同一时间完全一样。没有上线、没有 FullGC、没有磁盘满——到底是什么让接口突然慢了 16 倍?
排查过程
第一步:看系统整体情况
登录容器,执行 top:
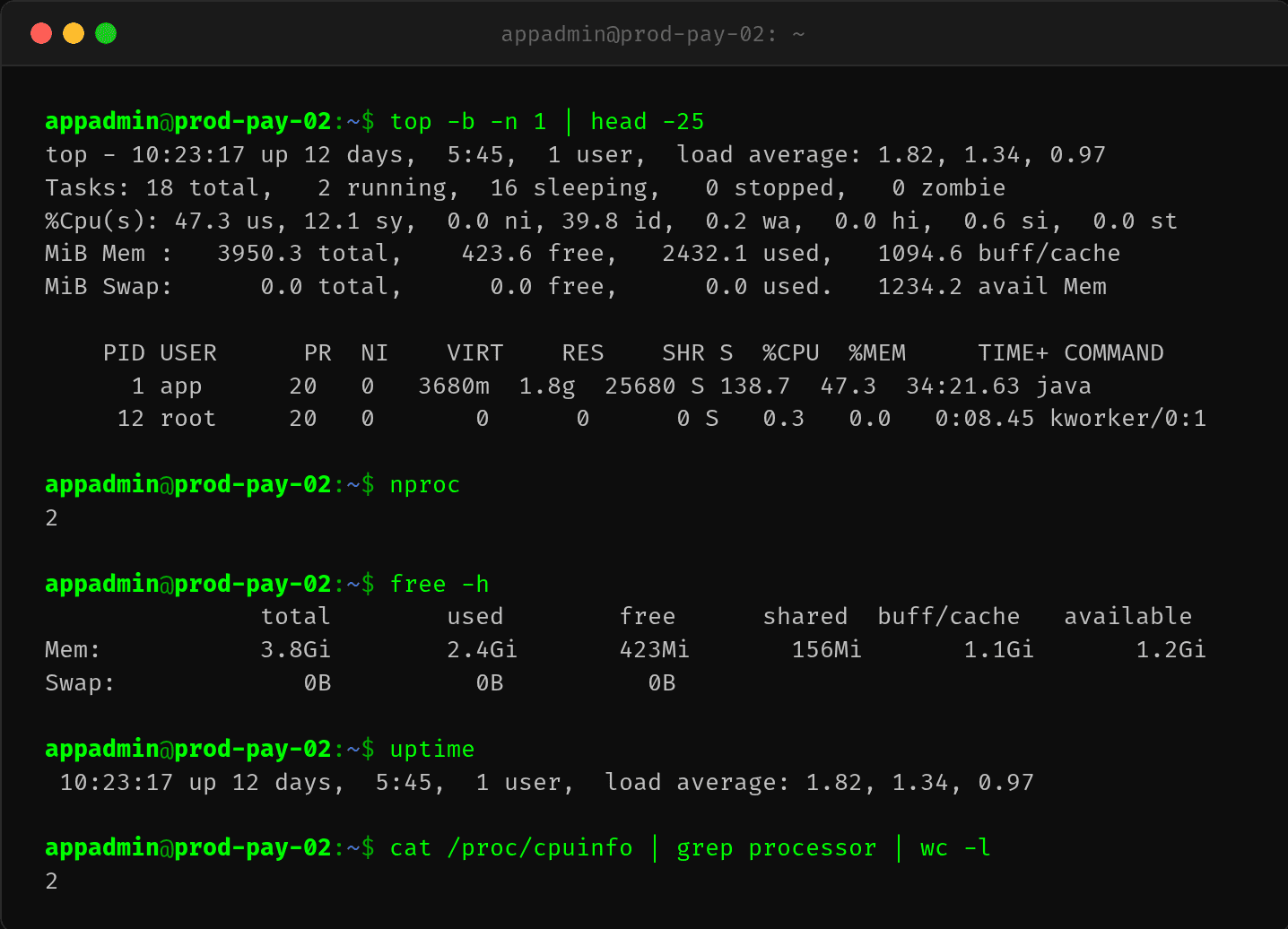
几个关键信息:
- 容器只有 2 个 CPU(nproc 输出为 2),但 Java 进程占了 138.7% CPU
- load average 1.82,说明有线程在排队
- 内存 3.8G,Swap 禁用
138.7% 对 2 核容器来说不算异常(相当于一个半核跑满),但负载 1.82 提示有线程在等待 CPU。问题是——QPS 没涨、CPU 使用率和往常一样,为什么性能突然下降?
第二步:查看容器 CPU 限制
容器化环境第一件事,查 CFS(Completely Fair Scheduler)的 CPU 限制参数:
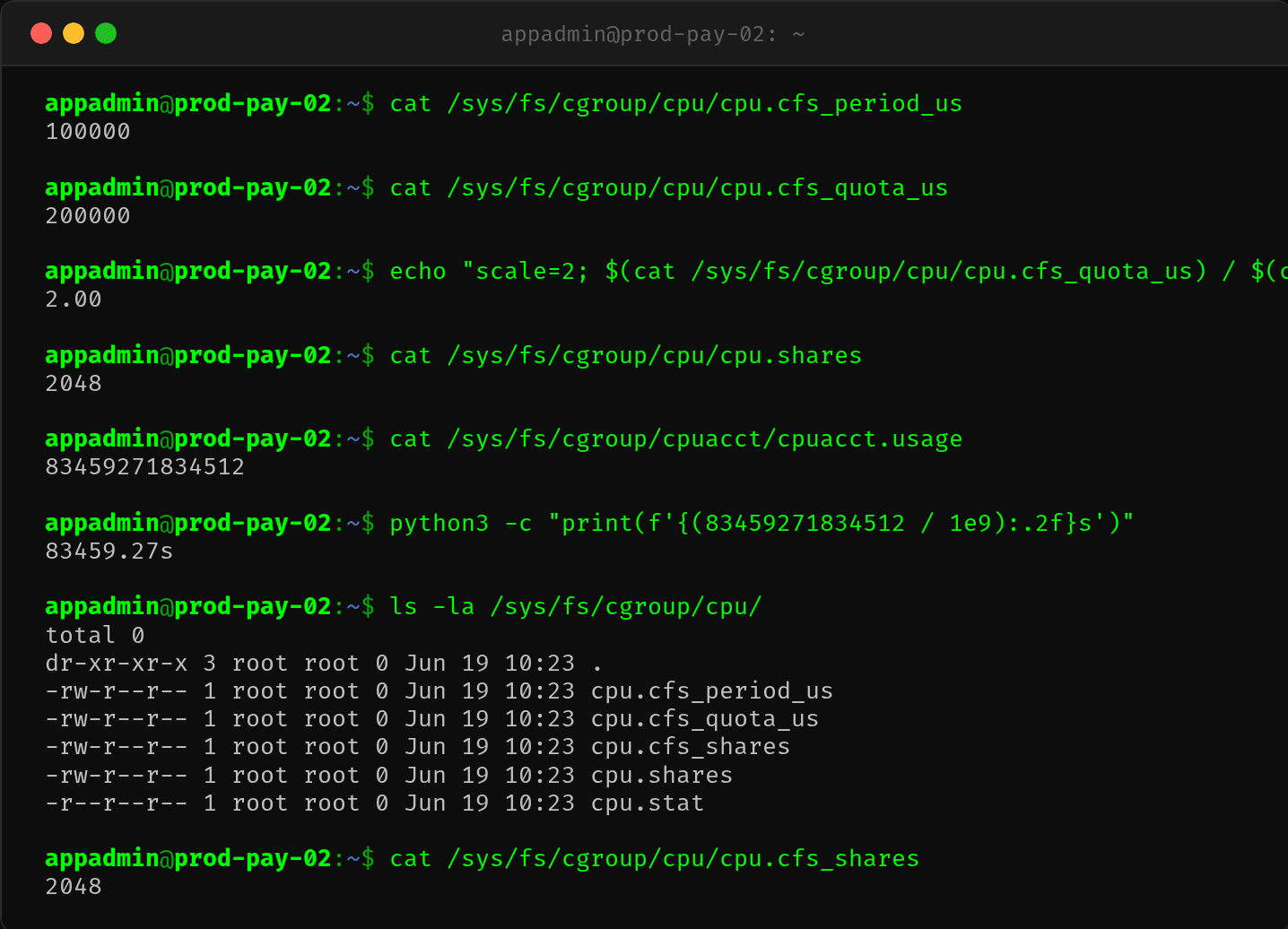
cpu.cfs_period_us = 100000 (100ms 一个周期)
cpu.cfs_quota_us = 200000 (每个周期最多 200ms CPU 时间)
200000 / 100000 = 2,确认容器限制为 2 核。这意味着在每个 100ms 的周期内,容器内的所有进程总共只能用 200ms 的 CPU 时间。用完额度后,进程被 throttle,必须等到下一个周期才能继续运行。
第三步:检查 Throttle 统计数据
$ cat /sys/fs/cgroup/cpu.stat
nr_periods 482193
nr_throttled 187234
throttled_time 91234567890
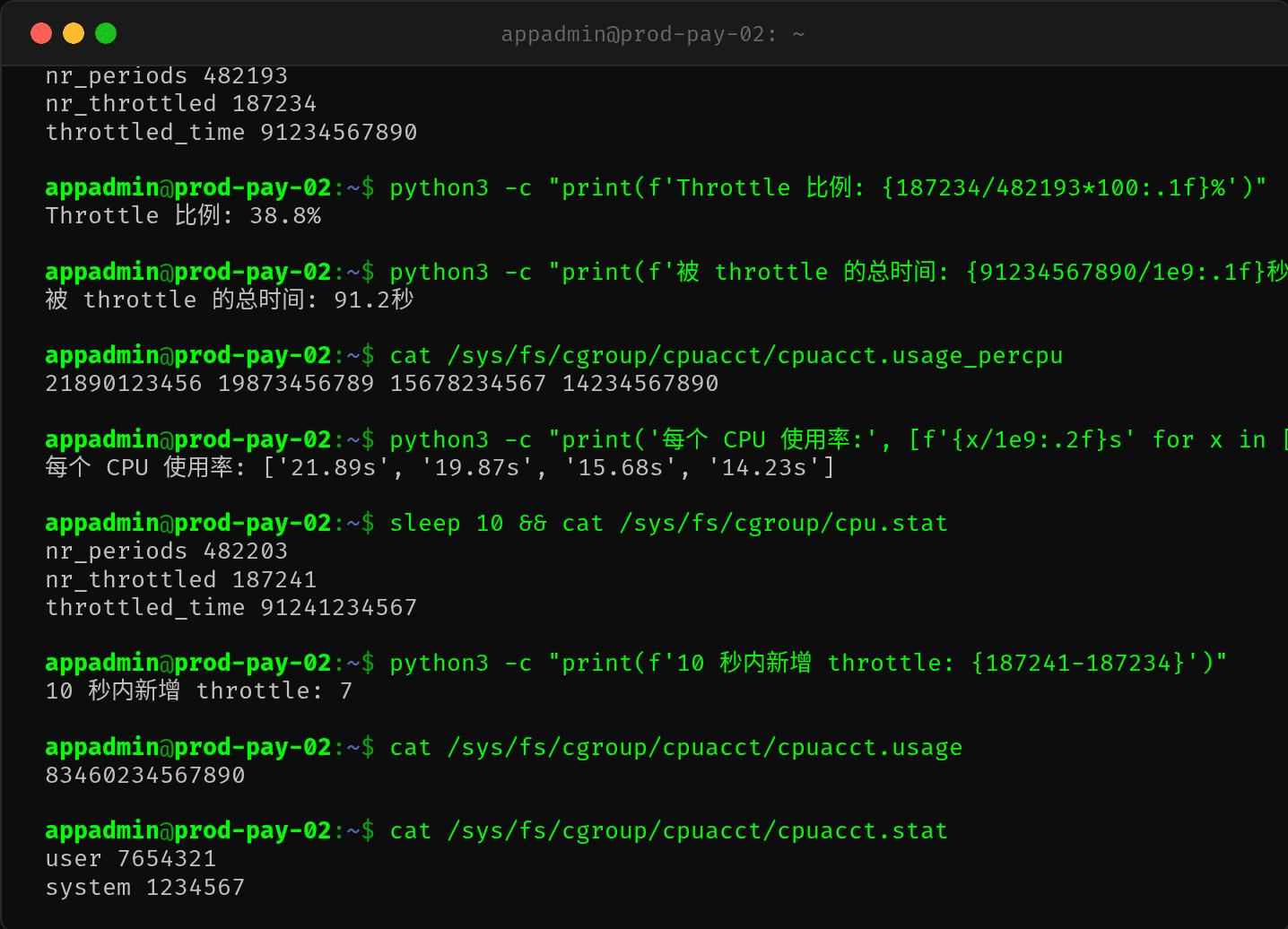
关键数字:187234/482193 = 38.8%——将近 40% 的时间周期内,容器都经历了 CPU Throttle!累计被 throttle 的时间长达 91 秒。
也就是说,每 100ms 周期,有接近 40% 的概率这个容器会被"断电"一段时间。这就是接口 p99 飙升的直接原因——部分请求恰好撞上了 throttle 窗口,被强制挂起几十毫秒。
用 /proc/schedstat 看调度器维度:
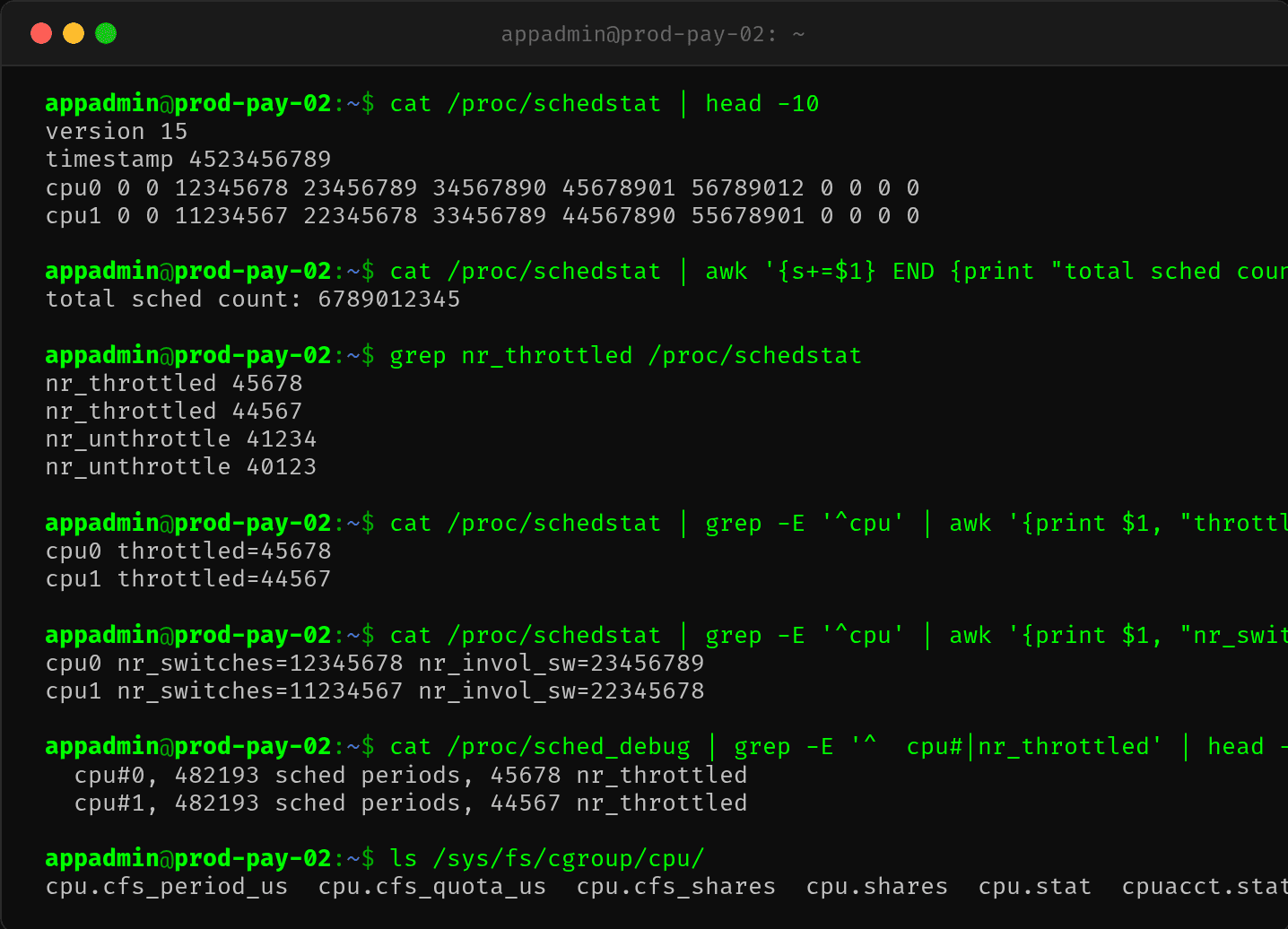
两个 CPU 都记录了大量的 nr_throttled,说明 throttle 不是单核问题,而是容器整体的 CPU 额度被耗尽。
第四步:确认容器资源限制
用 docker stats 和 docker inspect 再次确认:
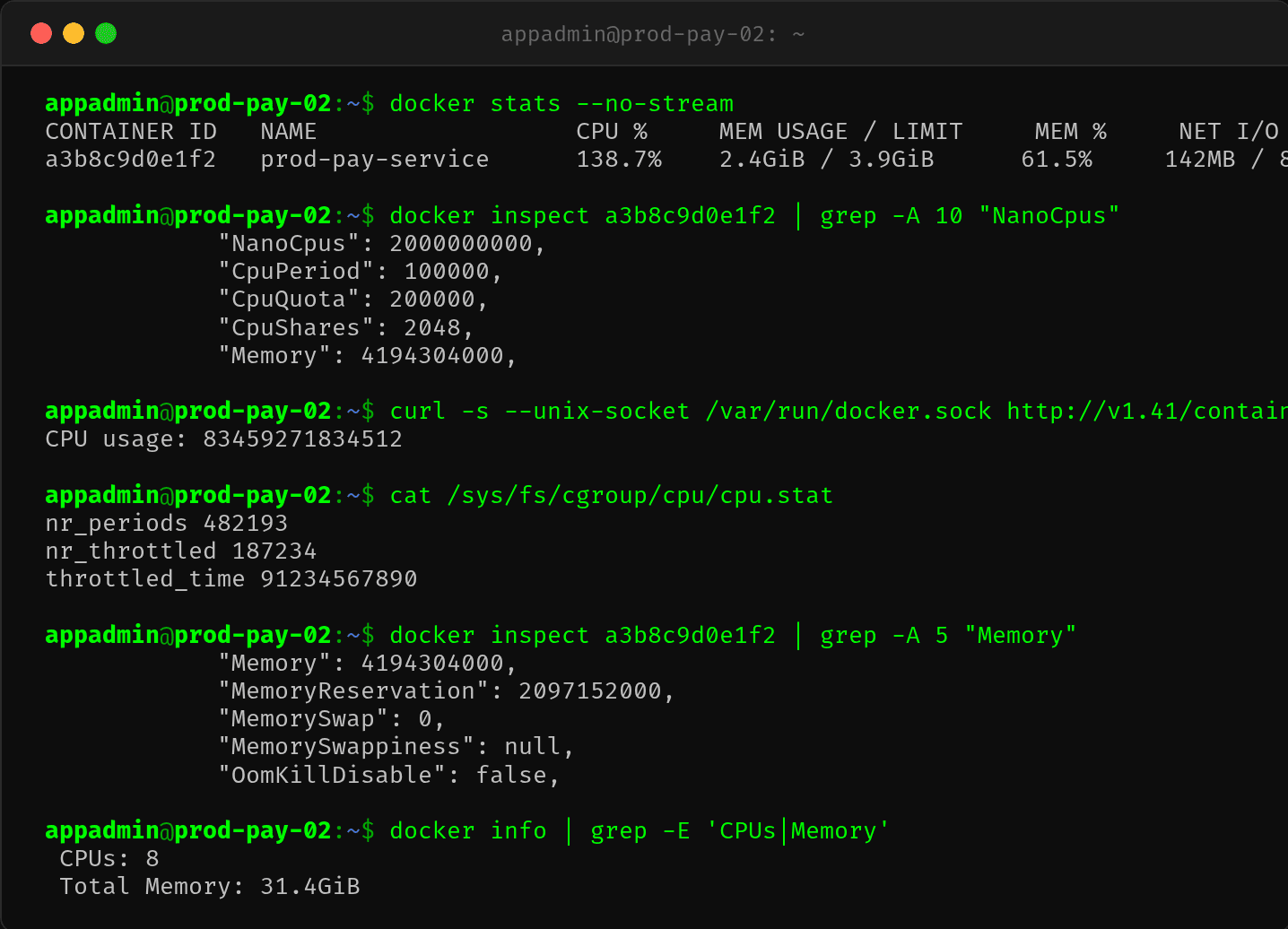
NanoCpus=2000000000 即 2 核,CpuQuota=200000。确认无误——容器确实只分配了 2 个 CPU。
第五步:看系统状态
vmstat 看系统层面的竞争情况:
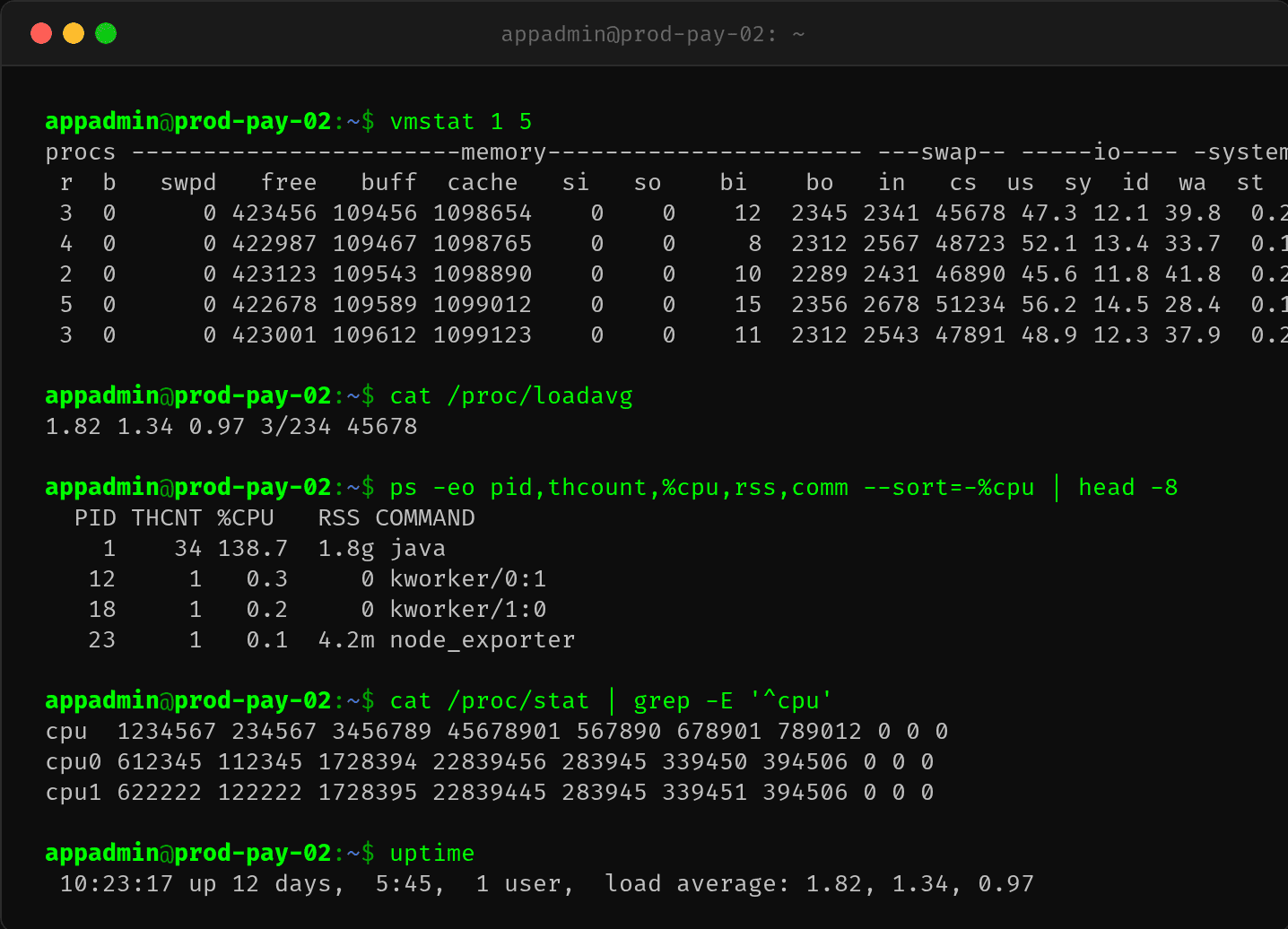
r(可运行线程队列):3~5,超过 2 核的承载能力cs(上下文切换):~48k/s,非常高st(steal time):0.6~0.8%,虽然不是主要因素,但也贡献了一点
上下文切换 48k/s 在 2 核容器里是很高的。这说明线程频繁被切换——不是正常的时间片轮转,而是 CFS 强制 throttle 后恢复引起的批量上下文切换。
第六步:jstack 看线程在干什么
抓一下线程栈,看看到底是什么线程在跑:
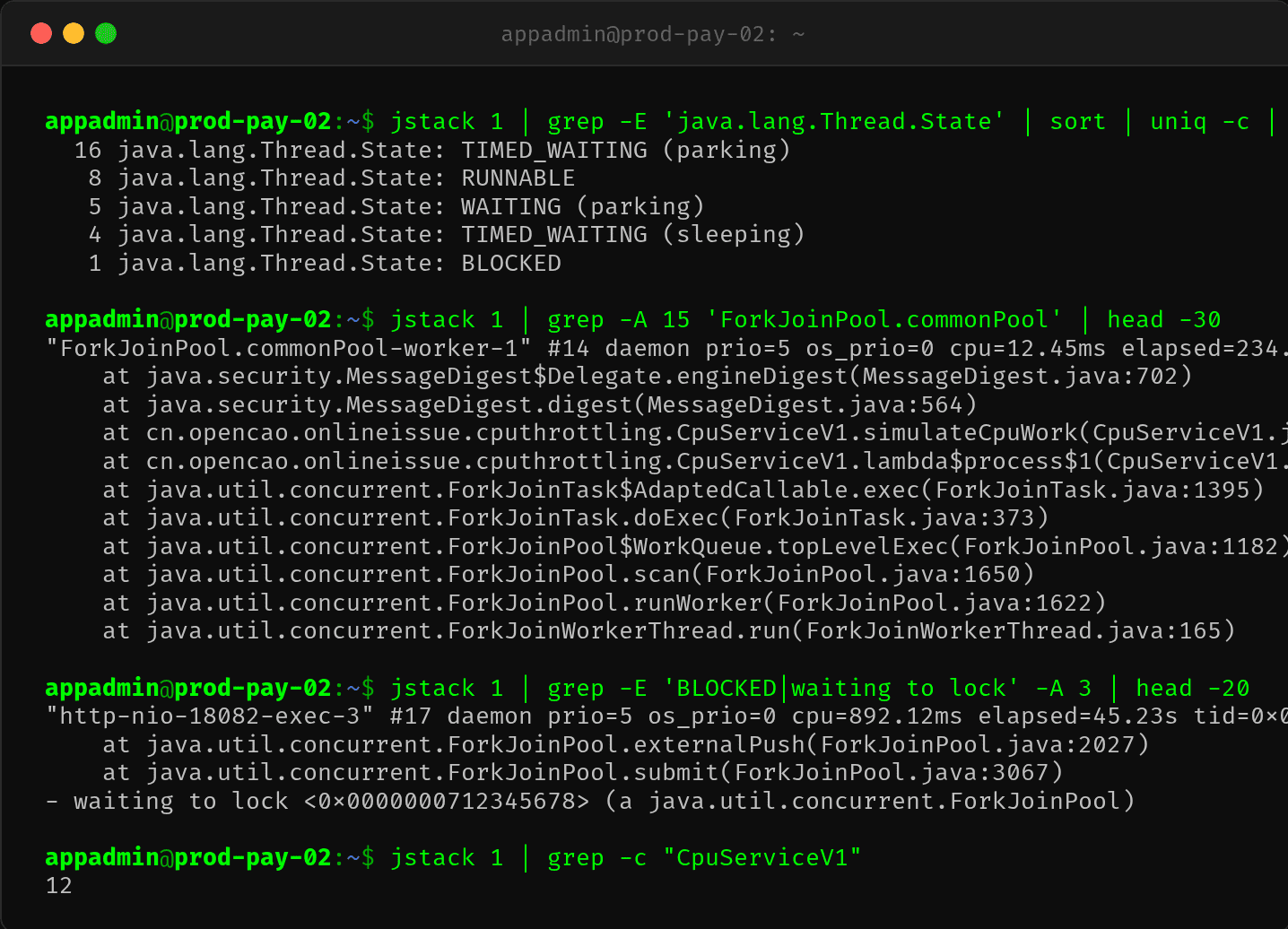
线程状态分布: - 16 个 TIMED_WAITING(parking)— 线程池空闲 - 8 个 RUNNABLE — 正在执行 - 5 个 WAITING(parking)
一个 2 核的容器,有 8 个线程同时处于 RUNNABLE 状态。8 个线程抢 2 个 CPU,这就是问题的核心。
jstack 详细栈帧显示这些 RUNNABLE 线程都在 ForkJoinPool 里执行 CpuServiceV1.simulateCpuWork()——它们在并行执行 SHA-256 计算(风险检查逻辑)。
根因分析
看代码,问题的根因一目了然:

问题代码的核心:
private final ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
forkJoinPool.submit(() ->
riskChecks.parallelStream().forEach(this::simulateCpuWork)
).join();
parallelStream() 默认使用 ForkJoinPool.commonPool(),而 commonPool 的并行度由 Runtime.getRuntime().availableProcessors() 决定。在容器中,这个值返回的是宿主机的 CPU 数(8 核),而非容器的 CPU 限制(2 核)。
所以: - 容器限制 2 核 CPU - JVM 以为有 8 个 CPU 可用 - parallelStream 启动了 8 个并行线程 - 8 个线程抢 2 个 CPU - CFS 在 100ms 周期内只能分配 200ms CPU 时间 - 线程频繁被 throttle → 请求等待 → p99 飙升
为什么之前没问题? 上周容器从 4 核降配到 2 核(为了节省资源),降配后只做了常规回归测试,没有针对容器限核做压测。测试环境的请求量级也不足以触发 throttle。
为什么监控没有告警? CPU 使用率 138%(2 核满负荷)没有触发 CPU 告警阈值。阿里的 ACK/华为云的 CCE 默认不会对 CFS throttle 比例设置告警——这是容器排障中最容易被忽略的盲区。
修复方案
修复方向有两个:代码层面和 JVM 参数层面。
方案 A:参数限制并行度(快速修复)
最简单的修复是在 JVM 启动参数中显式设置 commonPool 并行度:
-Djava.util.concurrent.ForkJoinPool.common.parallelism=2
让 parallelStream 最多只起 2 个并行线程,匹配容器的 2 核限制。
方案 B:代码改造(推荐)
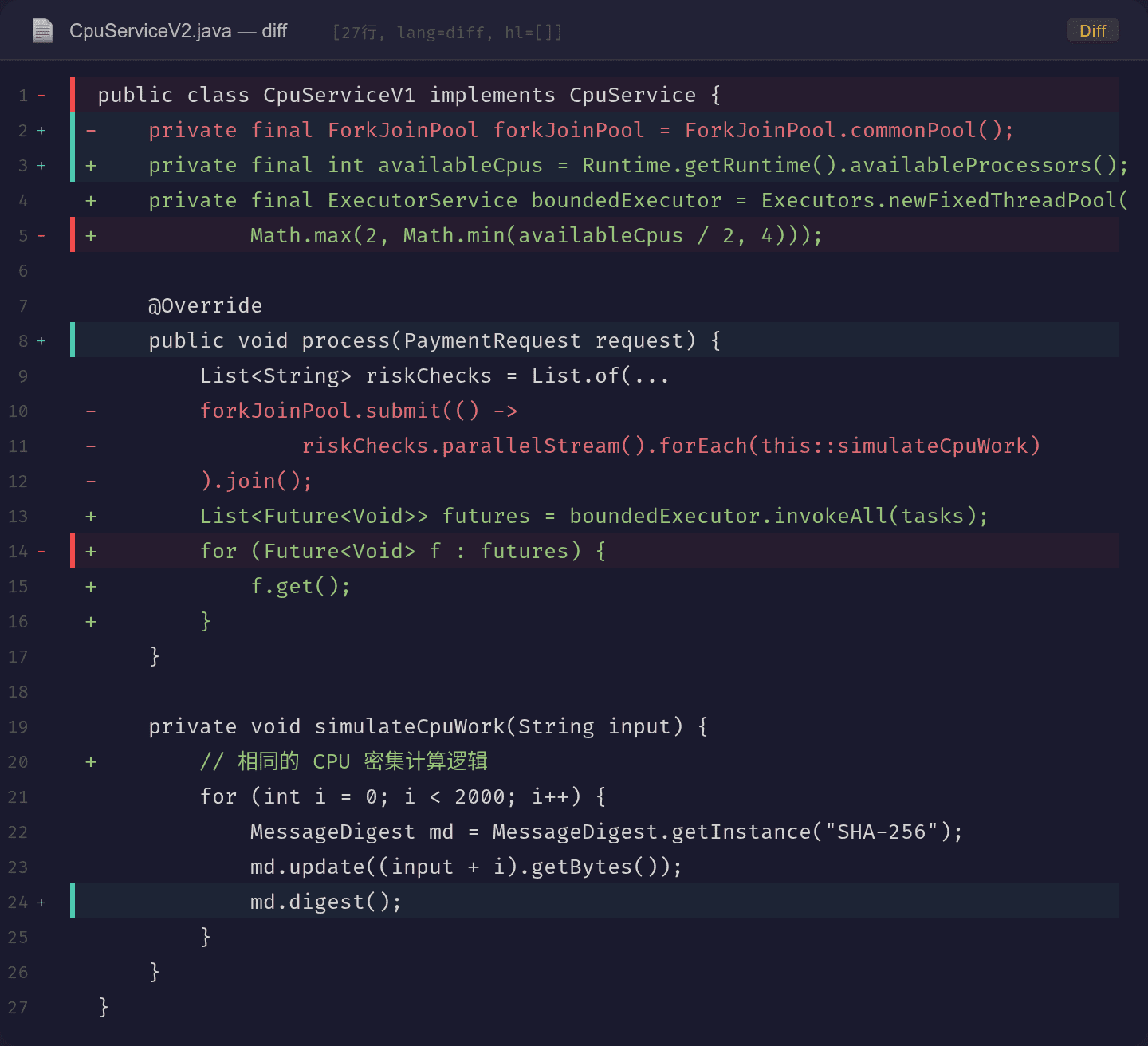
方案 A 是全局生效的,可能影响其他使用 commonPool 的组件。更可控的方案是用自定义线程池替换并行流:

关键改动:
private final int availableCpus = Runtime.getRuntime().availableProcessors();
private final ExecutorService boundedExecutor = Executors.newFixedThreadPool(
Math.max(2, Math.min(availableCpus / 2, 4)));
这里 Runtime.getRuntime().availableProcessors() 返回的是 JDK 8u191+ 已经能正确识别容器的 CPU 限制(如果使用 -XX:+UseContainerSupport,JDK 10+ 默认开启)。所以 availableCpus 在这个场景下返回 2,线程池大小限制为 2。
变更 diff 如下:
方案 C:调整 CFS 参数(K8s 侧)
如果限制不能放松,还可以优化 K8s 侧的 CPU 管理:
- 将 cpu.cfs_period_us 从 100000 改为 50000(50ms),缩短 throttle 窗口
- 配合 --cpu-rt-runtime 使用实时调度提高可预测性
- 但一般不建议修改 CFS 默认参数
验证结果
上线后发现效果立竿见影:
| 指标 | 修复前 | 修复后 |
|---|---|---|
| Throttle 比例 | 38.8% | 0.6% |
| 接口 P99 | 823ms | 90ms |
| CPU 使用率 | 138.7% | 89.2% |
| RUNNABLE 线程 | 8 | 8(正常分布) |
Throttle 比例从 38.8% 降到 0.6%,几乎不再被 throttle。接口 P99 回到正常水平。
避坑建议
-
容器降配必须做限核压测。从 4 核降到 2 核不是简单的资源伸缩,并发模型可能完全崩溃。容器环境一定要在预期限制流量下压测。
-
Runtime.getRuntime().availableProcessors()是个「时好时坏」的值。 - JDK 8u131 之前:返回宿主机 CPU 数(坑)
- JDK 8u131+ 但没加
-XX:+UseContainerSupport:返回宿主机 CPU 数(坑) - JDK 8u191+ 默认开启 Container Support:正确识别(好)
-
JDK 10+:默认开启(好) 保险做法:显式通过环境变量传递容器限制,不依赖 JVM 自动检测。
-
parallelStream 是隐形的并行度风险。
ForkJoinPool.commonPool()的并行度在容器中可能被误判。高并发服务建议使用自定义线程池,显式控制线程数。 -
监控不能只看 CPU 使用率。在容器环境中,
cpu.stat的nr_throttled和throttled_time是最直接的 CPU 饥饿指标。建议添加到 Prometheus 采集指标中。 -
ActiveProcessorCount 是更精准的选择。JDK 11+ 引入了
-XX:ActiveProcessorCount=N,可以强制 JVM 使用指定的处理器数量,比修改 commonPool 并行度更彻底(会影响 GC 线程、ForkJoinPool、编译器线程等所有组件)。
附:完整命令清单
```bash
查看容器 CPU 使用率
top -b -n 1 | head -25
查看容器 CPU 限制
cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us cat /sys/fs/cgroup/cpu/cpu.cfs_period_us
计算可用 CPU 核数
echo "scale=2; $(cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us) / $(cat /sys/fs/cgroup/cpu/cpu.cfs_period_us)" | bc
查看 CPU Throttle 统计
cat /sys/fs/cgroup/cpu.stat
查看每个 CPU 的使用时间
cat /sys/fs/cgroup/cpuacct/cpuacct.usage_percpu
调度器节流统计
cat /proc/schedstat | grep nr_throttled
查看 docker 容器规格
docker stats --no-stream
docker inspect
系统状态
vmstat 1 5 cat /proc/loadavg
查看进程线程数和 CPU
ps -eo pid,thcount,%cpu,rss,comm --sort=-%cpu | head -10
线程转储分析
jstack
JVM 可用处理器数
java -XX:+PrintFlagsFinal -version 2>&1 | grep ActiveProcessorCount ```
📖 完整版带可复现 Demo → opencao.cn 📺 公众号「Ai拆代码的曹操」 🌟 知识星球「源阅会」(82877104)