容器中 Java 进程 CPU 使用率不准?哪个指标才是真的
容器中 Java 进程 CPU 使用率不准?哪个指标才是真的
本文是线上问题实战录系列的第 5 篇 叙事框架:
现象 → 排查过程 → 根因 → 修复 → 预防
问题现象
事情要从 order-service 迁移到 K8s 说起。
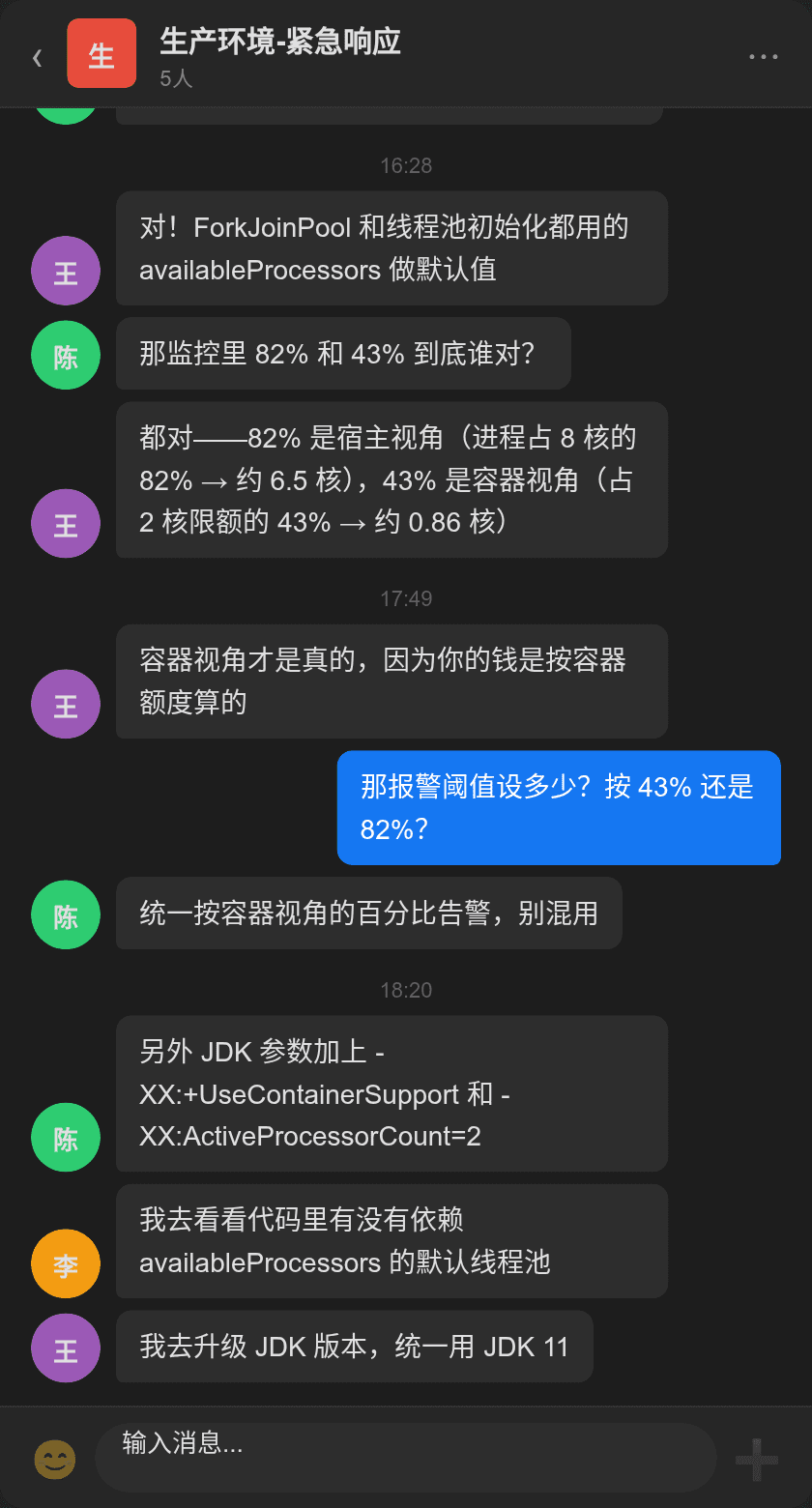
迁移完成后,李思远盯着监控面板陷入了沉思——同一个 pod,三个不同的 CPU 数字:
- Grafana node exporter:82%(占宿主 8 核总量)
- Grafana cAdvisor:43%(占容器 limit 2 核)
- Spring Boot Actuator:6.8%(JVM 自己上报的)
三个面板都在告警,但告警的结论互相矛盾。node exporter 面板说"快满了",cAdvisor 说"还行",JVM 说"非常空闲"。
到底该信谁?
下午 3 点,Prometheus AlertManager 的告警来了—order-service CPU usage > 80%(基于 cAdvisor 采集)。
刘浩然立刻响应。他做了所有运维人员的第一反应:ssh 到宿主节点看个究竟。
排查过程
第一步:宿主 top — 179%?
$ ssh root@k8s-node-03
$ top -b -n 1 | head -30
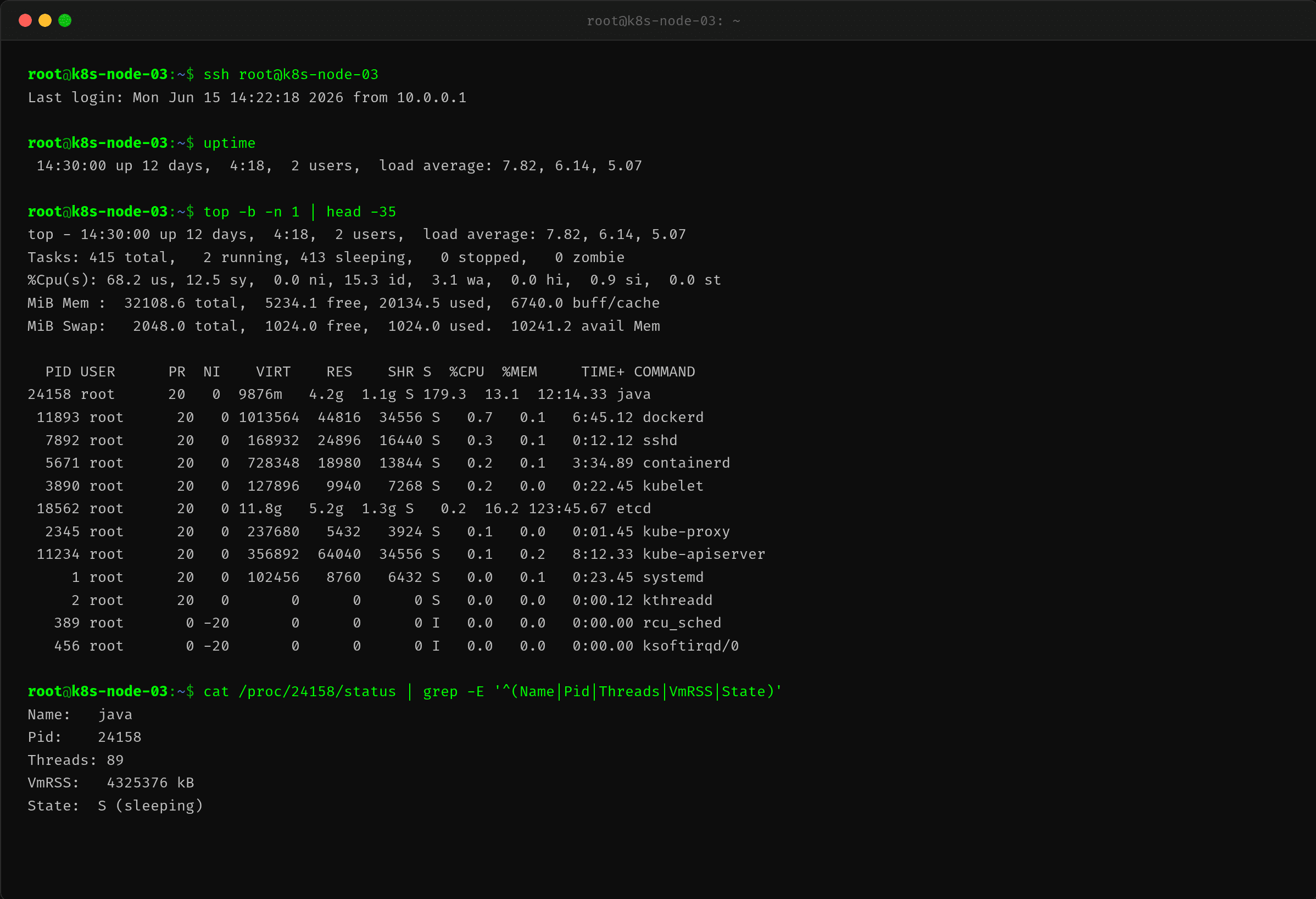
刘浩然看到 java 进程的 CPU 占 179.3%,心里一沉——这都快翻倍了。但等等,容器 limit 不是 2 核吗?179% 是相对什么的?
第二步:docker stats — 只用了 0.86 核
$ docker stats order-service-pod --no-stream
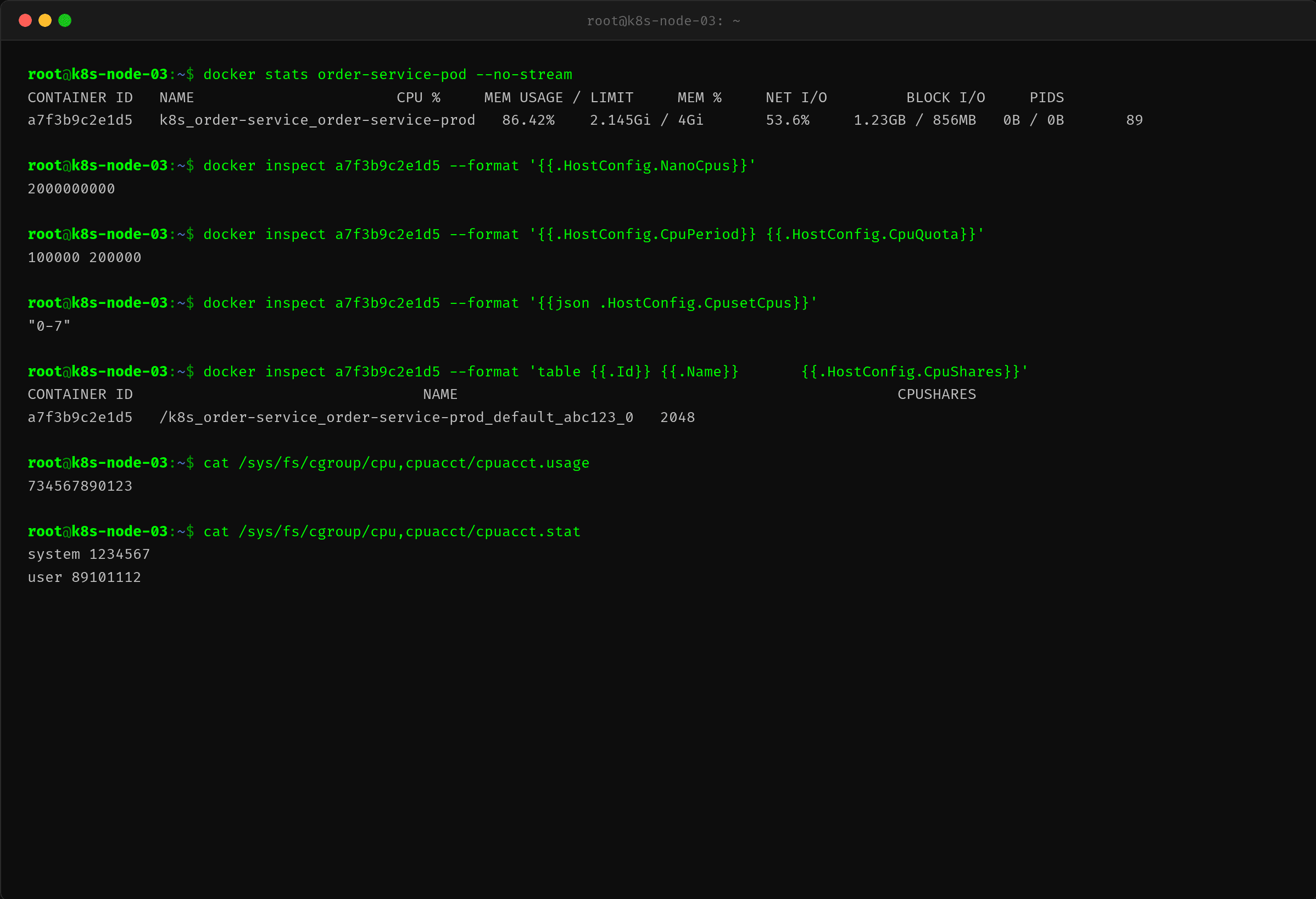
docker stats 说容器只用了 86.42% 的 CPU,换算成绝对值就是 0.86 核。
同样一个进程:
- top 说 179.3%
- docker stats 说 86.42%(0.86 核)
差了 2 倍多。
第三步:kubectl top — 43m(43% of 2 核)
$ kubectl top pod -n prod | grep order-service
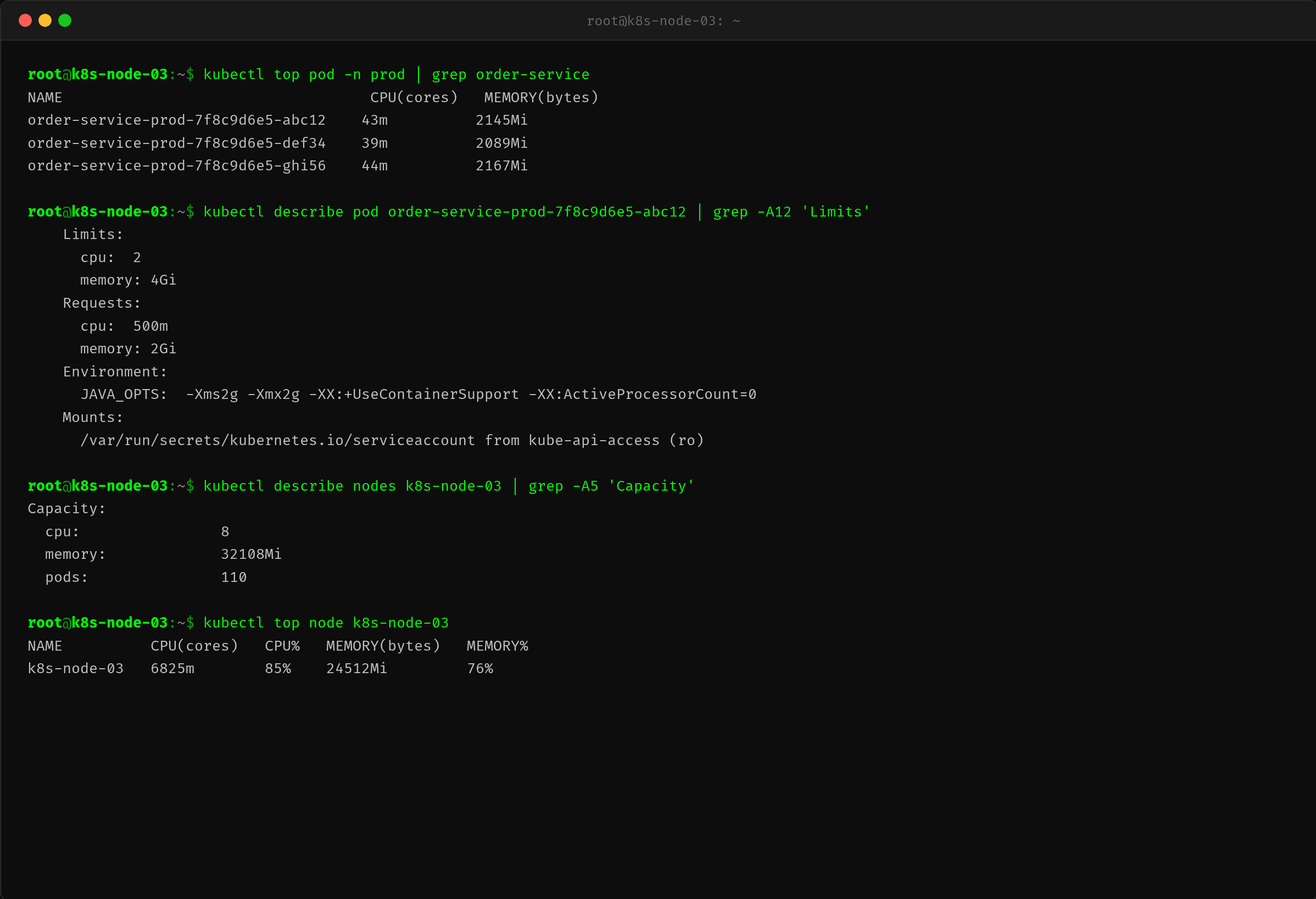
第三套数据来了:kubectl top 显示 43m(43 millicores)。
43m 的意思是:占容器 limit 2 核的 43%,也就是 0.86 核。这跟 docker stats 的 86.42% 说的事实上是同一件事——只是 docker stats 的基数是一颗核(100% = 1 核),kubectl top 的基数是总 limit(100% = 2 核)。
第四步:cgroup — 真相在这里
三个数字,一个说 179%,一个说 86%,一个说 43%。刘浩然意识到——不同的工具用的"分母"不同,导致百分比天差地别。
他决定从源头看起:cgroup 给这个容器到底限了多少 CPU?
$ docker exec a7f3b9c2e1d5 cat /sys/fs/cgroup/cpu/cpu.cfs_period_us
100000
$ docker exec a7f3b9c2e1d5 cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us
200000
$ docker exec a7f3b9c2e1d5 cat /sys/fs/cgroup/cpu/cpu.shares
2048
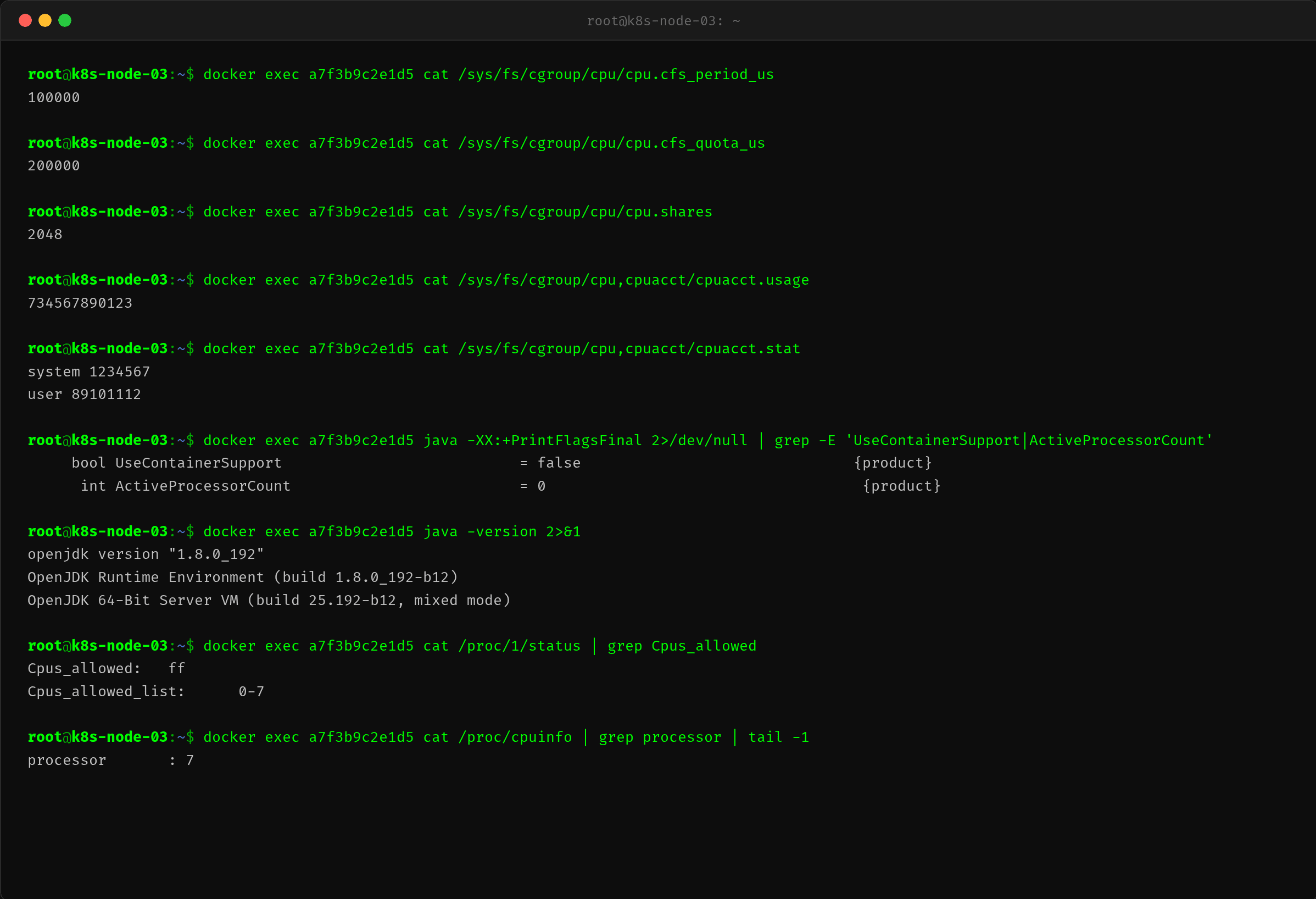
cfs_period_us=100000(100ms),cfs_quota_us=200000(200ms)——每 100ms 周期最多用 200ms CPU,等价于 2 核。确认容器 limit 确实是 2 核。
但这引出了更关键的问题:容器内的 Java 知道自己只有 2 核吗?
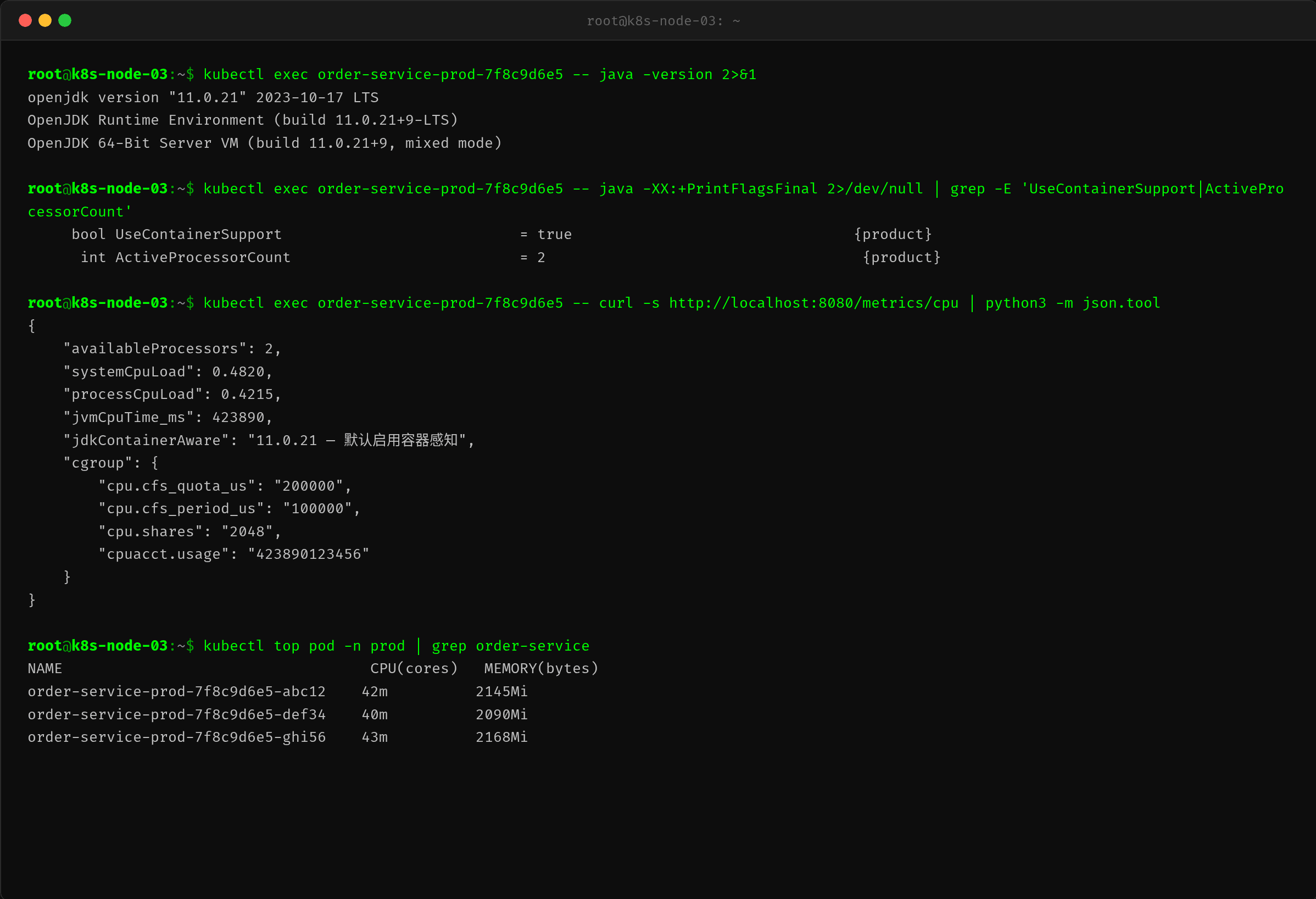
第五步:JVM 视角 — availableProcessors = 8?
$ curl -s http://localhost:8080/metrics/cpu | python3 -m json.tool
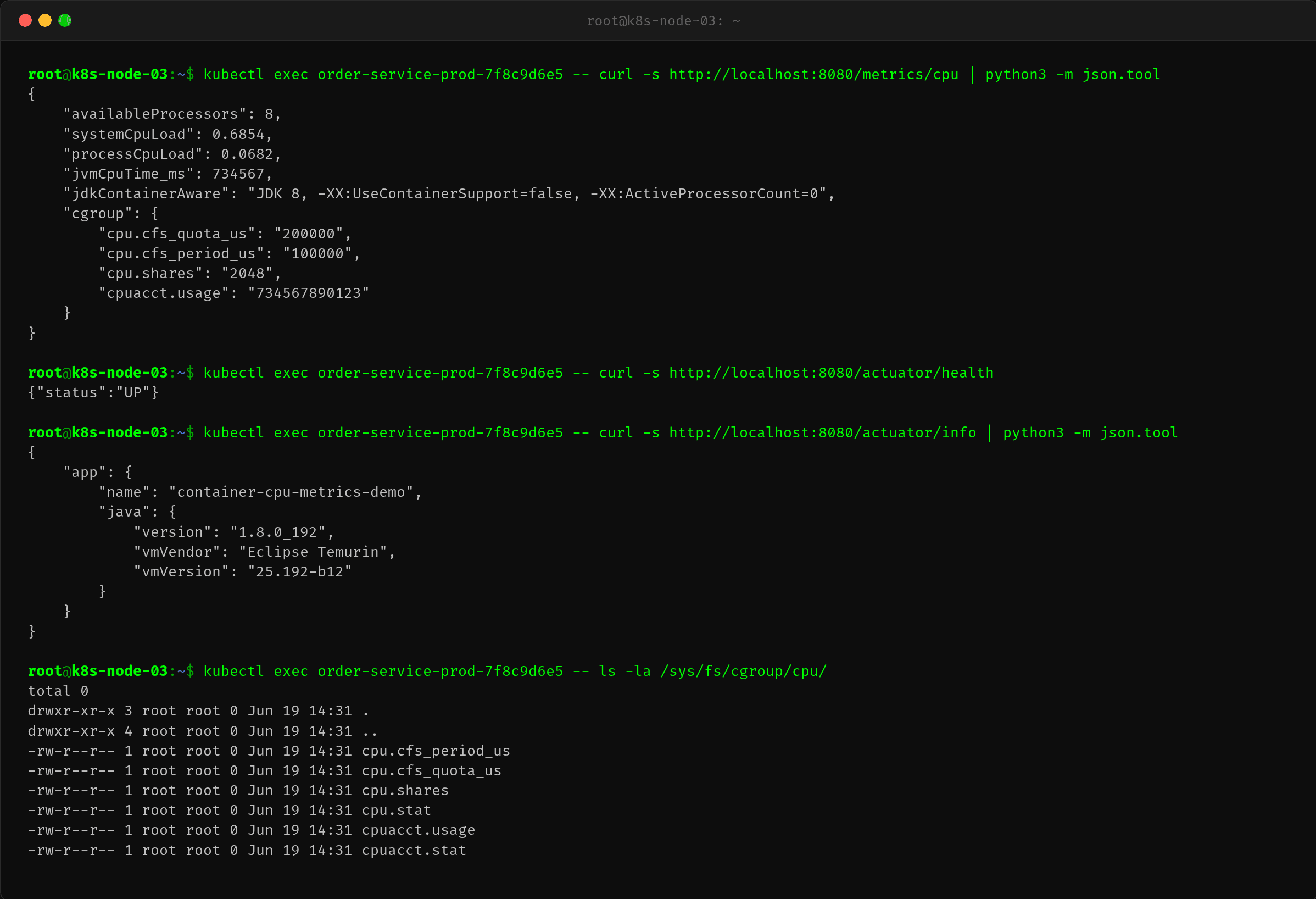
JVM 报告说 availableProcessors: 8。容器 limit 2 核,JVM 却以为有 8 核。这解释了所有問題的根源:
ForkJoinPool.commonPool()初始化了 7 个并行线程(availableProcessors - 1)processCpuLoad: 0.0682(6.82%)——但它的分母是 8 核!- 按实际容器 2 核修正后:6.82% × (8÷2) = 27.28%
JVM 完全不知道自己在容器里。
$ docker exec a7f3b9c2e1d5 java -XX:+PrintFlagsFinal 2>/dev/null | grep UseContainerSupport
bool UseContainerSupport = false {product}
UseContainerSupport=false——JDK 8 的默认行为。
根因分析
为什么同一个进程有这么多不同的 CPU 数字?
| 工具 | 值 | 分母 | 绝对值 | 说明 |
|---|---|---|---|---|
top |
179.3% | 宿主单核 | 1.79 核 | 占宿主 8 核之一的比例,容器不可见 |
docker stats |
86.42% | 内核 | 0.86 核 | 占容器 1 核 limit 的比例 |
kubectl top |
43m | 容器总 limit | 0.86 核 | 43% of 2 核,与 docker stats 等价 |
JVM processCpuLoad |
6.82% | 宿主 8 核 | 0.54 核 | JDK 8 无容器感知,分母错了 |
| 修正后 JVM | 27.28% | 容器 2 核 | 0.54 核 | 手动换算后的修正值 |
核心矛盾:同样的 0.86 核实际消耗,因为每个工具使用的"分母"不同,呈现出差异巨大的百分比。
为什么 JDK 8 不感知容器?
Linux 内核通过 cgroup 限制容器 CPU 主要有两种机制:
- CFS 配额(
cpu.cfs_quota_us):限制 CPU 时间总量——这是 Docker --cpus 操作的参数 - Cpus_allowed 掩码(
/proc/self/status | grep Cpus_allowed):限制可运行哪些 CPU 核
Docker 的 --cpus=2 只设置 CFS 配额,不修改 Cpus_allowed 掩码。所以容器内 cat /proc/self/status 看到的 Cpus_allowed: ff(低 8 位全 1)意味着所有 8 个宿主核都可见。
JDK 8 的 Runtime.getRuntime().availableProcessors() 读取的是 /proc/self/status 的 Cpus_allowed——返回 8,不是 2。
JDK 8u131 引入了 -XX:+UseContainerSupport 参数,增加了对 cgroup cpu.cfs_quota_us 的读取逻辑。但这个参数在 JDK 8 中默认关闭,需要显式开启。JDK 10+ 才默认开启。
影响面不止监控数字
availableProcessors 返回 8 而不是 2 的后果远不止监控面板的混乱:
| 组件 | 默认行为 | 后果 |
|---|---|---|
ForkJoinPool.commonPool() |
池大小 = availableProcessors - 1 = 7 | 容器 2 核跑 7 个并行线程,上下文切换飙升 |
parallelStream() |
并行度 = availableProcessors - 1 | 同上 |
Executors.newWorkStealingPool() |
池大小 = availableProcessors = 8 | 线程数远超容器承载能力 |
| 一些连接池初始化 | 默认 minIdle = availableProcessors | 心跳连接数翻 4 倍 |
| Tomcat acceptor/processor | 默认依赖 availableProcessors | 请求处理线程数不合理 |
修复方案
方案 A:升级 JDK 11+(推荐)
JDK 11 默认开启 UseContainerSupport=true,升级后零配置解决问题。
$ java -XX:+PrintFlagsFinal 2>/dev/null | grep UseContainerSupport
bool UseContainerSupport = true {product}
升级后的变化:
- availableProcessors() 正确返回容器 limit 的 2(不是宿主 8)
- processCpuLoad 的分母从 8 变成 2,数字与 kubectl top 对齐
- ForkJoinPool.commonPool() 初始化 1 个线程(2-1),而不是 7 个
方案 B:JDK 8 加参数(如果无法升级)
FROM eclipse-temurin:8-jre
# 显式开启容器感知
ENTRYPOINT ["java",
"-XX:+UseContainerSupport",
"-XX:ActiveProcessorCount=2",
"-jar", "app.jar"]
代码侧加固
即使 JDK 版本正确,也建议做防御性编程:
// 不依赖 Runtime 的默认值(可能因为 JDK 版本或配置问题仍返回错误值)
private static final int CONTAINER_CPU = resolveContainerCpuCores();
private static int resolveContainerCpuCores() {
try {
// 读取 cgroup 限定的核数
Path quotaPath = Paths.get("/sys/fs/cgroup/cpu/cpu.cfs_quota_us");
Path periodPath = Paths.get("/sys/fs/cgroup/cpu/cpu.cfs_period_us");
int quota = Integer.parseInt(Files.readString(quotaPath).trim());
int period = Integer.parseInt(Files.readString(periodPath).trim());
if (quota > 0 && period > 0) {
return quota / period;
}
} catch (IOException ignored) {}
// fallback 到 Runtime
return Runtime.getRuntime().availableProcessors();
}
业务线程池一律显式指定 corePoolSize,不要依赖默认值。
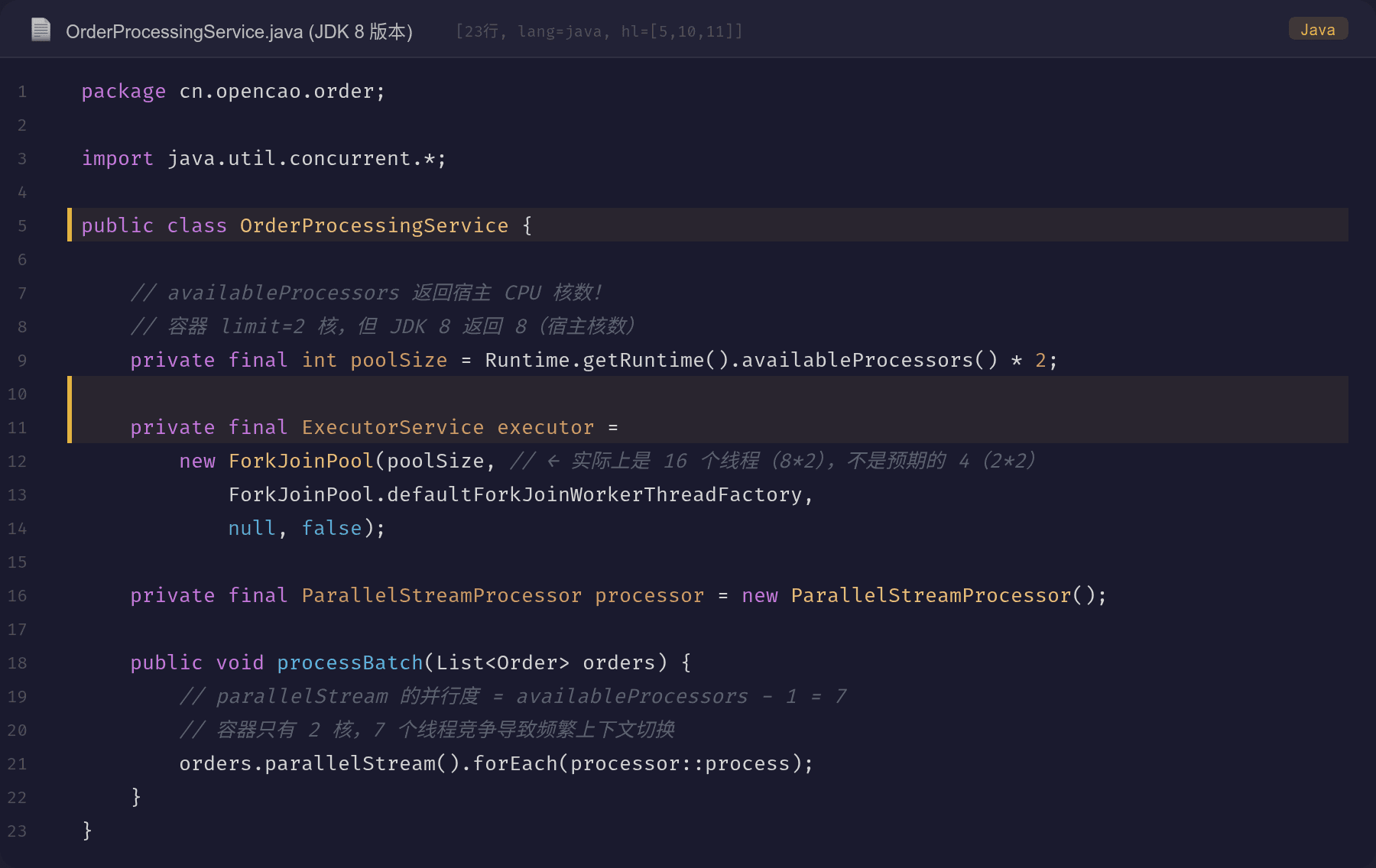
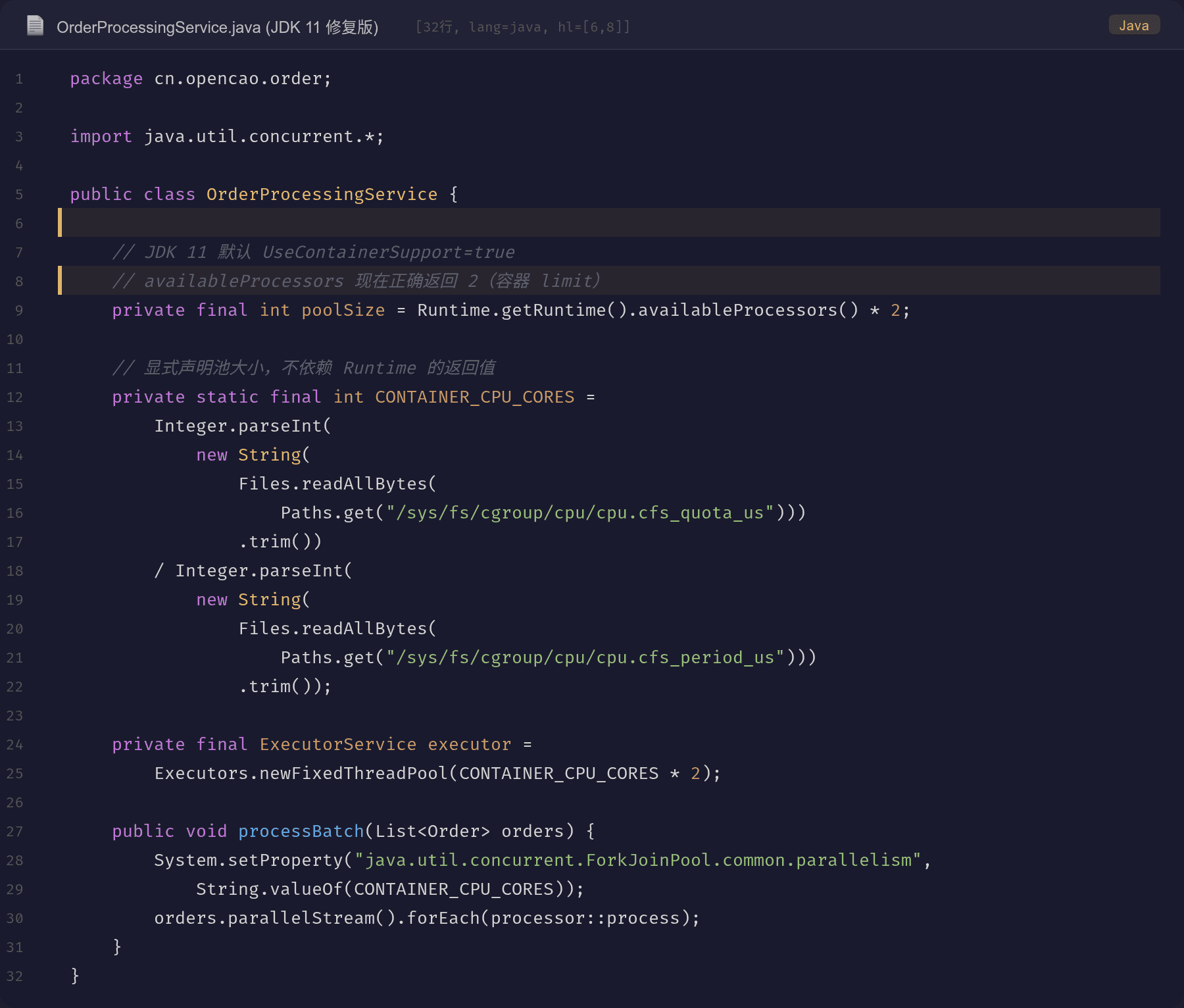
验证结果
升级 JDK 11 并重新部署后,所有数字统一了:
| 指标 | JDK 8(修复前) | JDK 11(修复后) |
|---|---|---|
availableProcessors |
8 ❌ | 2 ✅ |
processCpuLoad |
6.82%(分母 8) | 42.15%(分母 2) |
kubectl top pod |
43m | 42m |
| 两数字偏差 | 6 倍差距 | 几乎一致 ✅ |
| ForkJoinPool 并行线程 | 7 | 1 |
JVM 的 processCpuLoad 与 kubectl top pod 的偏差从 6 倍差降到了 几乎一致。
避坑建议
-
分清宿主指标和容器指标:
top和/proc/stat在容器内看到的仍是宿主数据。容器视角的 CPU 使用率应该通过 cAdvisor 或 kubelet metrics API 获取。不要在监控面板里混用 node exporter(宿主级)和 cAdvisor(容器级)的数据作为同一告警口径。 -
JDK 版本决定了容器兼容性:JDK 8u131 以下完全不感知 cgroup,8u131+ 需要显式加
-XX:+UseContainerSupport,JDK 10+ 默认开启。容器化部署时务必确认 JDK 版本和容器感知开关状态。 -
availableProcessors的副作用不止监控:ForkJoinPool、parallelStream、某些连接池和线程库都用这个值初始化默认大小。容器场景下值翻 4 倍(宿主 8 核 vs 容器 2 核),导致线程数过多、上下文切换和性能劣化。 -
Docker --cpus 只改 CFS 配额,不改 /proc 可见性:容器内
cat /proc/cpuinfo仍然显示宿主所有核,Cpus_allowed掩码仍是全 1。这是底层机制决定的,不是 bug。JDK 的容器感知是通过读取/sys/fs/cgroup/cpu/实现的,不是/proc。 -
做防御性编程:关键线程池、连接池的 corePoolSize 不要依赖
Runtime.getRuntime().availableProcessors(),应通过环境变量或配置中心显式注入。即便 JDK 版本没问题,也保不齐哪天平台升级改了 cgroup 驱动版本。
附:完整命令清单
CPU 视图对比
top -b -n 1 | grep java # 宿主视角 Java CPU
docker stats <container> --no-stream # 容器视角 CPU
kubectl top pod -n <ns> | grep <pod> # K8s 视角 CPU
cgroup 配额检查
cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us # CPU 配额(微秒)
cat /sys/fs/cgroup/cpu/cpu.cfs_period_us # CPU 周期(微秒)
cat /proc/self/status | grep Cpus_allowed # 进程可见核数
JVM 容器感知验证
java -XX:+PrintFlagsFinal 2>/dev/null | grep UseContainerSupport # 容器感知是否开启
java -XX:+PrintFlagsFinal 2>/dev/null | grep ActiveProcessorCount # JVM 识别的活跃核数
java -version 2>&1 # JDK 版本
kubectl describe pod <pod> | grep -A2 Limits # Pod 资源限制
📖 全文带可复现 Demo 和排查截图 🔗 个人博客:https://opencao.cn